边学边实战系列(八):ElasticSearch 集群部署、分片与故障转移
ElasticSearch 基础概念 、技术原理、安装和基础使用、索引管理、 DSL 查询、聚合查询、索引文档与读取文档流程相关的知识点,今天我将详细的为大家介绍 ElasticSearch 集群部署、分片及故障转移相关知识。
相关概念
单机 & 集群
- 单台 Elasticsearch 服务器提供服务,往往都有最大的负载能力,超过这个阈值,服务器性能就会大大降低甚至不可用,所以生产环境中,一般都是运行在指定服务器集群中。
- 除了负载能力,单点服务器也存在其他问题:
- 单台机器存储容量有限
- 单服务器容易出现单点故障,无法实现高可用
- 单服务的并发处理能力有限
配置服务器集群时,集群中节点数量没有限制,大于等于 2 个节点就可以看做是集群了。一般出于高性能及高可用方面来考虑集群中节点数量都是 3 个以上。
集群 Cluster
一个集群就是由一个或多个服务器节点组织在一起,共同持有整个的数据,并一起提供索引和搜索功能。一个 Elasticsearch 集群有一个唯一的名字标识,这个名字默认就是”elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。
节点 Node
集群中包含很多服务器,一个节点就是其中的一个服务器。作为集群的一部分,它存储数据,参与集群的索引和搜索功能。
一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色 的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于 Elasticsearch集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做 “elasticsearch”的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何 Elasticsearch 节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
为什么要部署 Elasticsearch 集群
单机部署的 Elasticsearch 在做数据存储时会遇到存储数据上线和机器故障问题,因此对于 Elasticsearch 集群的部署是有必要的。搭建 Elasticsearch 集群,可以将创建的索引库拆分成多个分片(索引可以被拆分为不同的部分进行存储,称为分片。
在集群环境下,一个索引的不同分片可以拆分到不同的节点中),存储到不同的节点上,以此来解决海量数据存储问题;将分片上的数据分布在不同的节点上可以解决单点故障问题。
Elasticsearch集群职责
在Elasticsearch集群中,不同的节点可以承担不同的职责,例如:
- Master节点:负责集群的管理和调度,包括分配和重新分配分片、节点的加入和退出、索引的创建和删除等。
- Data节点:负责存储数据和执行搜索请求,包括分片的读写、搜索请求的处理等。
- Ingest节点:负责对文档进行预处理,例如对文档进行解析、转换、过滤等操作。
- Coordinating节点:负责协调搜索请求,将请求转发给适当的Data节点进行处理,并将结果汇总返回给客户端。
在实际的生产环境中,可以根据集群的规模和负载情况来决定节点的职责划分。例如,在小型集群中,可以将所有节点都设置为Master节点和Data节点;在大型集群中,可以将一部分节点设置为Master节点,一部分节点设置为Data节点,同时还可以设置一些Coordinating节点和Ingest节点来协调搜索请求和处理文档预处理。
Windows 集群
部署集群
创建 elasticsearch-cluster 文件夹,在内部复制三个 elasticsearch 服务
修改集群文件目录中每个节点的 config/elasticsearch.yml 配置文件
node-1001 节点
#节点 1 的配置信息:
#集群名称,节点之间要保持一致
cluster.name: my-elasticsearch
#节点名称,集群内要唯一
node.name: node-1001
node.master: true
node.data: true
#ip 地址
network.host: localhost
#http 端口
http.port: 1001
#tcp 监听端口
transport.tcp.port: 9301
#discovery.seed_hosts: ["localhost:9301", "localhost:9302","localhost:9303"]
#discovery.zen.fd.ping_timeout: 1m
#discovery.zen.fd.ping_retries: 5
#集群内的可以被选为主节点的节点列表
#cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
#跨域配置
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"
node-1002 节点
#节点 2 的配置信息:
#集群名称,节点之间要保持一致
cluster.name: my-elasticsearch
#节点名称,集群内要唯一
node.name: node-1002
node.master: true
node.data: true
#ip 地址
network.host: localhost
#http 端口
http.port: 1002
#tcp 监听端口
transport.tcp.port: 9302
discovery.seed_hosts: ["localhost:9301"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
#集群内的可以被选为主节点的节点列表
#cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
#跨域配置
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"
node-1003 节点
#节点 3 的配置信息:
#集群名称,节点之间要保持一致
cluster.name: my-elasticsearch
#节点名称,集群内要唯一
node.name: node-1003
node.master: true
node.data: true
#ip 地址
network.host: localhost
#http 端口
http.port: 1003
#tcp 监听端口
transport.tcp.port: 9303
#候选主节点的地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["localhost:9301", "localhost:9302"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
#集群内的可以被选为主节点的节点列表
#cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
#跨域配置
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"
启动集群
启动前先删除每个节点中的 data 目录中所有内容(如果存在)
分别双击执行 bin/elasticsearch.bat, 启动节点服务器,启动后,会自动加入指定名称的集群
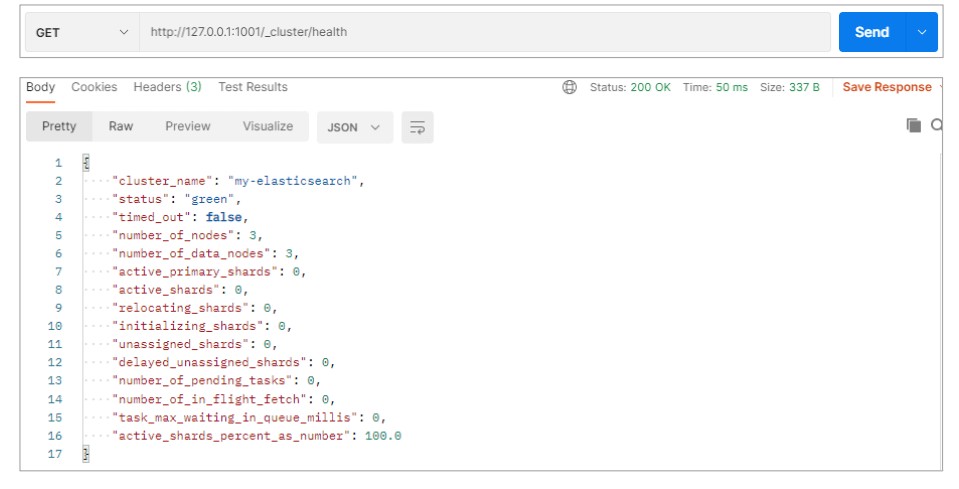
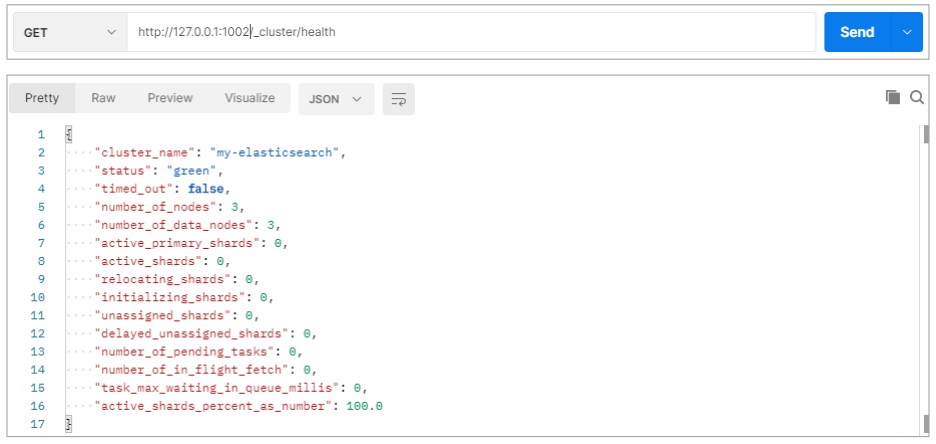
测试集群
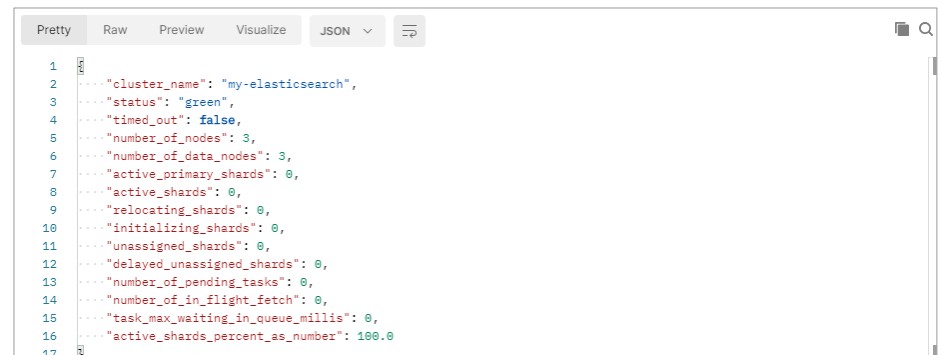
查看集群状态
node-1001 节点
node-1002 节点
node-1003 节点
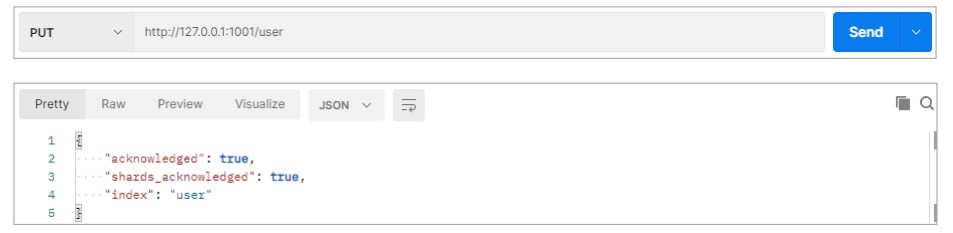
向集群中的 node-1001 节点增加索引
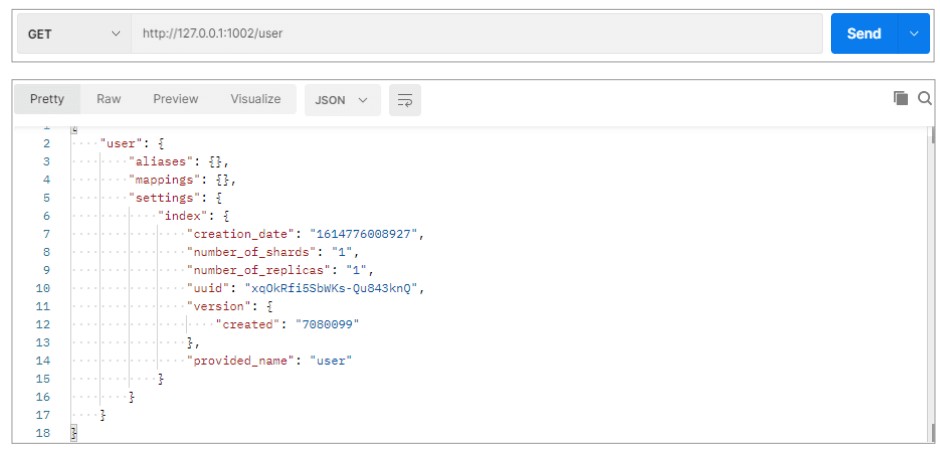
向集群中的 node-1002 节点查询索引
Linux 集群
编写内容如下的docker-compose文件,将其上传到Linux的/root目录下:
version: '2.2'
services:
es01:
image: elasticsearch:7.12.1
container_name: es01
environment:
- node.name=es01
- cluster.name=es-docker-cluster # 集群名称相同
- discovery.seed_hosts=es02,es03 # 可以发现的其他节点
- cluster.initial_master_nodes=es01,es02,es03 # 可以选举为主节点
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data01:/usr/share/elasticsearch/data # 数据卷
ports:
- 9200:9200 # 容器内外端口映射
networks:
- elastic
es02:
image: elasticsearch:7.12.1
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data02:/usr/share/elasticsearch/data
ports:
- 9201:9200
networks:
- elastic
es03:
image: elasticsearch:7.12.1
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data03:/usr/share/elasticsearch/data
networks:
- elastic
ports:
- 9202:9200
volumes:
data01:
driver: local
data02:
driver: local
data03:
driver: local
networks:
elastic:
driver: bridgees运行需要修改一些linux系统权限,进入并修改/etc/sysctl.conf文件
vi /etc/sysctl.conf
在文件中添加下面的内容:
vm.max_map_count=262144
然后执行命令,让配置生效:
sysctl -p
通过docker-compose启动集群:
docker-compose up -d
启动完成后,使用docker查看运行的容器,可以看到已启动Elasticsearch集群:

Elasticsearch集群健康状态
Elasticsearch集群的健康状态可以通过以下命令或API来查看:
命令行方式:
可以使用curl命令或者httpie命令来访问Elasticsearch的API来获取集群健康状态,例如:
curl -X GET "localhost:9200/_cat/health?v"
或者
http GET localhost:9200/_cat/health?v
其中,localhost:9200是Elasticsearch的地址和端口号,_cat/health是API的路径,v表示显示详细信息。执行以上命令后,会返回如下信息:
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1578318307 02:38:27 elasticsearch green 1 1 6 3 0 0 0 0 - 100.0%其中,status字段表示集群的健康状态,有以下几种取值:
- green:所有主分片和副本分片都正常分配到节点上。
- yellow:所有主分片都正常分配到节点上,但是有一些副本分片还没有分配到节点上。
- red:有一些主分片没有分配到节点上,导致数据不可用。
API方式:
可以使用Elasticsearch的API来获取集群健康状态,例如:
GET /_cluster/health
执行以上命令后,会返回如下信息:
{
"cluster_name" : "my_cluster",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 6,
"active_shards" : 6,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}其中,status字段表示集群的健康状态,其他字段的含义和命令行方式相同。
Elasticsearch集群分片
Elasticsearch 集群中的数据被分成多个分片(shard),每个分片是一个独立的Lucene索引。分片可以在集群中的不同节点上分布,以提高搜索和写入性能。分片有两种类型:主分片(primary shard)和副本分片(replica shard)。
主分片是每个文档的主要存储位置,每个主分片都有一个唯一的标识符,并且只能在一个节点上存在。当一个文档被索引时,它被路由到一个主分片,然后被写入该分片的Lucene索引。
副本分片是主分片的拷贝,它们可以在不同的节点上存在。副本分片的数量可以在索引创建时指定,它们可以提高搜索性能和可用性。当一个主分片不可用时,副本分片可以被用来提供搜索结果。副本分片也可以用来平衡负载,因为它们可以被用来处理读取请求。
在 Elasticsearch 集群中,分片的数量和副本的数量可以通过索引的设置进行配置。通常,主分片的数量应该小于或等于集群中的节点数,以确保每个节点都有主分片。副本分片的数量应该根据集群的负载和可用性需求进行配置。
当索引创建完成的时候,主分片的数量就固定了,但是复制分片的数量可以随时调整。
Elasticsearch故障转移
集群的 master 节点会监控集群中的所有节点的状态,一旦发现有节点宕机,就会立即将宕机的节点分片的数据迁移到其他节点上,以此来保证数据安全,这个流程叫故障转移。与此同时剩余节点中会重新选举主节点,当原来的主节点恢复正常时,原来迁移到其他节点上面的分片会被迁移到恢复的节点上,但此时原来的主节点不再是主节点(哥不再是当年的哥)。
总结
Elasticsearch 故障转移的实现主要依赖于以下两个机制:
- 分片复制机制:Elasticsearch将索引分为多个分片,每个分片都有多个副本,分布在不同的节点上。当一个节点发生故障时,其他节点上的副本可以接管该分片的工作,保证数据的可用性。
- 主从复制机制:Elasticsearch集群中的每个分片都有一个主节点和多个从节点。当主节点宕机时,从节点会自动选举一个新的主节点,以继续处理该分片的请求。
在实际应用中,为了进一步提高Elasticsearch集群的可用性和稳定性,可以采用以下措施:
- 配置多个节点:将Elasticsearch集群部署在多个节点上,以分散风险,避免单点故障。
- 监控节点状态:使用监控工具对Elasticsearch节点进行实时监控,及时发现并处理故障。
- 自动化运维:使用自动化运维工具对Elasticsearch集群进行管理和维护,减少人为操作的错误和风险。
- 定期备份数据:定期备份Elasticsearch集群中的数据,以防止数据丢失和损坏,保证数据的可恢复性。
- 发表于 2023-06-19 16:05
- 阅读 ( 32 )
