边学边实战系列(三):ElasticSearch 安装与基础使用
前面介绍了 ElasticSearch 基础概念、生态与应用场景、技术原理相关的知识点。今天我将详细的为大家介绍 ElasticSearch 安装与基础使用相关知识,希望大家能够从中收获多多!
安装 ElasticSearch
ElasticSearch 是基于Java平台的,所以先要安装Java。
平台确认
这里我准备了一台Centos7虚拟机, 为方便选择后续安装的版本,所以需要看下系统版本信息。
[root@centos ~]# uname -a
Linux centos 3.10.0-862.el7.x86_64 #1 SMP Fri Apr 20 16:44:24 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
安装Java
安装 Elasticsearch 之前,你需要先安装一个较新的版本的 Java,最好的选择是,你可以从http://www.java.com/获得官方提供的最新版本的 Java。安装以后,确认是否安装成功:
[root@centos ~]# java --version
openjdk 14.0.2 2020-07-14
OpenJDK Runtime Environment 20.3 (slowdebug build 14.0.2+12)
OpenJDK 64-Bit Server VM 20.3 (slowdebug build 14.0.2+12, mixed mode, sharing)
下载ElasticSearch
从https://www.elastic.co/cn/downloads/elasticsearch下载ElasticSearch
比如可以通过curl下载
[root@centos opt]# curl -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.12.0-linux-x86_64.tar.gz
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
解压
[root@centos opt]# tar zxvf /opt/elasticsearch-7.12.0-linux-x86_64.tar.gz
...
[root@centos opt]# ll | grep elasticsearch
drwxr-xr-x 9 root root 4096 Mar 18 14:21 elasticsearch-7.12.0
-rw-r--r-- 1 root root 327497331 Apr 5 21:05 elasticsearch-7.12.0-linux-x86_64.tar.gz
增加elasticSearch用户
必须创建一个非root用户来运行ElasticSearch(ElasticSearch5及以上版本,基于安全考虑,强制规定不能以root身份运行。)
如果你使用root用户来启动ElasticSearch,则会有如下错误信息:
[root@centos opt]# cd elasticsearch-7.12.0/
[root@centos elasticsearch-7.12.0]# ./bin/elasticsearch
[2021-04-05T21:36:46,510][ERROR][o.e.b.ElasticsearchUncaughtExceptionHandler] [centos] uncaught exception in thread [main]
org.elasticsearch.bootstrap.StartupException: java.lang.RuntimeException: can not run elasticsearch as root
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:163) ~[elasticsearch-7.12.0.jar:7.12.0]
at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:150) ~[elasticsearch-7.12.0.jar:7.12.0]
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:75) ~[elasticsearch-7.12.0.jar:7.12.0]
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:116) ~[elasticsearch-cli-7.12.0.jar:7.12.0]
at org.elasticsearch.cli.Command.main(Command.java:79) ~[elasticsearch-cli-7.12.0.jar:7.12.0]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:115) ~[elasticsearch-7.12.0.jar:7.12.0]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:81) ~[elasticsearch-7.12.0.jar:7.12.0]
Caused by: java.lang.RuntimeException: can not run elasticsearch as root
at org.elasticsearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:101) ~[elasticsearch-7.12.0.jar:7.12.0]
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:168) ~[elasticsearch-7.12.0.jar:7.12.0]
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:397) ~[elasticsearch-7.12.0.jar:7.12.0]
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:159) ~[elasticsearch-7.12.0.jar:7.12.0]
... 6 more
uncaught exception in thread [main]
java.lang.RuntimeException: can not run elasticsearch as root
at org.elasticsearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:101)
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:168)
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:397)
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:159)
at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:150)
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:75)
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:116)
at org.elasticsearch.cli.Command.main(Command.java:79)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:115)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:81)
For complete error details, refer to the log at /opt/elasticsearch-7.12.0/logs/elasticsearch.log
2021-04-05 13:36:46,979269 UTC [8846] INFO Main.cc@106 Parent process died - ML controller exiting
所以我们增加一个独立的elasticsearch用户来运行
# 增加elasticsearch用户
[root@centos elasticsearch-7.12.0]# useradd elasticsearch
[root@centos elasticsearch-7.12.0]# passwd elasticsearch
Changing password for user elasticsearch.
New password:
BAD PASSWORD: The password contains the user name in some form
Retype new password:
passwd: all authentication tokens updated successfully.
# 修改目录权限至新增的elasticsearch用户
[root@centos elasticsearch-7.12.0]# chown -R elasticsearch /opt/elasticsearch-7.12.0
# 增加data和log存放区,并赋予elasticsearch用户权限
[root@centos elasticsearch-7.12.0]# mkdir -p /data/es
[root@centos elasticsearch-7.12.0]# chown -R elasticsearch /data/es
[root@centos elasticsearch-7.12.0]# mkdir -p /var/log/es
[root@centos elasticsearch-7.12.0]# chown -R elasticsearch /var/log/es
然后修改上述的data和log路径,vi /opt/elasticsearch-7.12.0/config/elasticsearch.yml
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
path.data: /data/es
#
# Path to log files:
#
path.logs: /var/log/es
修改Linux系统的限制配置
- 1.修改系统中允许应用最多创建多少文件等的限制权限。Linux默认来说,一般限制应用最多创建的文件是65535个。但是ES至少需要65536的文件创建权限。
- 2.修改系统中允许用户启动的进程开启多少个线程。默认的Linux限制root用户开启的进程可以开启任意数量的线程,其他用户开启的进程可以开启1024个线程。必须修改限制数为4096+。因为ES至少需要4096的线程池预备。ES在5.x版本之后,强制要求在linux中不能使用root用户启动ES进程。所以必须使用其他用户启动ES进程才可以。
- 3.Linux低版本内核为线程分配的内存是128K。4.x版本的内核分配的内存更大。如果虚拟机的内存是1G,最多只能开启3000+个线程数。至少为虚拟机分配1.5G以上的内存。
修改如下配置
[root@centos elasticsearch-7.12.0]# vi /etc/security/limits.conf
elasticsearch soft nofile 65536
elasticsearch hard nofile 65536
elasticsearch soft nproc 4096
elasticsearch hard nproc 4096
启动ElasticSearch
[root@centos elasticsearch-7.12.0]# su elasticsearch
[elasticsearch@centos elasticsearch-7.12.0]$ ./bin/elasticsearch -d
[2021-04-05T22:03:38,332][INFO ][o.e.n.Node ] [centos] version[7.12.0], pid[13197], build[default/tar/78722783c38caa25a70982b5b042074cde5d3b3a/2021-03-18T06:17:15.410153305Z], OS[Linux/3.10.0-862.el7.x86_64/amd64], JVM[AdoptOpenJDK/OpenJDK 64-Bit Server VM/15.0.1/15.0.1+9]
[2021-04-05T22:03:38,348][INFO ][o.e.n.Node ] [centos] JVM home [/opt/elasticsearch-7.12.0/jdk], using bundled JDK [true]
[2021-04-05T22:03:38,348][INFO ][o.e.n.Node ] [centos] JVM arguments [-Xshare:auto, -Des.networkaddress.cache.ttl=60, -Des.networkaddress.cache.negative.ttl=10, -XX:+AlwaysPreTouch, -Xss1m, -Djava.awt.headless=true, -Dfile.encoding=UTF-8, -Djna.nosys=true, -XX:-OmitStackTraceInFastThrow, -XX:+ShowCodeDetailsInExceptionMessages, -Dio.netty.noUnsafe=true, -Dio.netty.noKeySetOptimization=true, -Dio.netty.recycler.maxCapacityPerThread=0, -Dio.netty.allocator.numDirectArenas=0, -Dlog4j.shutdownHookEnabled=false, -Dlog4j2.disable.jmx=true, -Djava.locale.providers=SPI,COMPAT, --add-opens=java.base/java.io=ALL-UNNAMED, -XX:+UseG1GC, -Djava.io.tmpdir=/tmp/elasticsearch-17264135248464897093, -XX:+HeapDumpOnOutOfMemoryError, -XX:HeapDumpPath=data, -XX:ErrorFile=logs/hs_err_pid%p.log, -Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m, -Xms1894m, -Xmx1894m, -XX:MaxDirectMemorySize=993001472, -XX:G1HeapRegionSize=4m, -XX:InitiatingHeapOccupancyPercent=30, -XX:G1ReservePercent=15, -Des.path.home=/opt/elasticsearch-7.12.0, -Des.path.conf=/opt/elasticsearch-7.12.0/config, -Des.distribution.flavor=default, -Des.distribution.type=tar, -Des.bundled_jdk=true]
查看安装是否成功
[root@centos ~]# netstat -ntlp | grep 9200
tcp6 0 0 127.0.0.1:9200 :::* LISTEN 13549/java
tcp6 0 0 ::1:9200 :::* LISTEN 13549/java
[root@centos ~]# curl 127.0.0.1:9200
{
"name" : "centos",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "ihttW8b2TfWSkwf_YgPH2Q",
"version" : {
"number" : "7.12.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "78722783c38caa25a70982b5b042074cde5d3b3a",
"build_date" : "2021-03-18T06:17:15.410153305Z",
"build_snapshot" : false,
"lucene_version" : "8.8.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
安装Kibana
Kibana是界面化的查询数据的工具,下载时尽量下载与ElasicSearch一致的版本。
- 下载Kibana
从https://www.elastic.co/cn/downloads/kibana下载Kibana
- 解压
[root@centos opt]# tar -vxzf kibana-7.12.0-linux-x86_64.tar.gz
- 使用elasticsearch用户权限
[root@centos opt]# chown -R elasticsearch /opt/kibana-7.12.0-linux-x86_64
#配置Kibana的远程访问
[root@centos opt]# vi /opt/kibana-7.12.0-linux-x86_64/config/kibana.yml
server.host: 0.0.0.0
- 启动
需要切换至elasticsearch用户。
[root@centos opt]# su elasticsearch
[elasticsearch@centos opt]$ cd /opt/kibana-7.12.0-linux-x86_64/
[elasticsearch@centos kibana-7.12.0-linux-x86_64]$ ./bin/kibana
log [22:30:22.185] [info][plugins-service] Plugin "osquery" is disabled.
log [22:30:22.283] [warning][config][deprecation] Config key [monitoring.cluster_alerts.email_notifications.email_address] will be required for email notifications to work in 8.0."
log [22:30:22.482] [info][plugins-system] Setting up [100] plugins: [taskManager,licensing,globalSearch,globalSearchProviders,banners,code,usageCollection,xpackLegacy,telemetryCollectionManager,telemetry,telemetryCollectionXpack,kibanaUsageCollection,securityOss,share,newsfeed,mapsLegacy,kibanaLegacy,translations,legacyExport,embeddable,uiActionsEnhanced,expressions,charts,esUiShared,bfetch,data,home,observability,console,consoleExtensions,apmOss,searchprofiler,painlessLab,grokdebugger,management,indexPatternManagement,advancedSettings,fileUpload,savedObjects,visualizations,visTypeVislib,visTypeVega,visTypeTimelion,features,licenseManagement,watcher,canvas,visTypeTagcloud,visTypeTable,visTypeMetric,visTypeMarkdown,tileMap,regionMap,visTypeXy,graph,timelion,dashboard,dashboardEnhanced,visualize,visTypeTimeseries,inputControlVis,discover,discoverEnhanced,savedObjectsManagement,spaces,security,savedObjectsTagging,maps,lens,reporting,lists,encryptedSavedObjects,dashboardMode,dataEnhanced,cloud,upgradeAssistant,snapshotRestore,fleet,indexManagement,rollup,remoteClusters,crossClusterReplication,indexLifecycleManagement,enterpriseSearch,beatsManagement,transform,ingestPipelines,eventLog,actions,alerts,triggersActionsUi,stackAlerts,ml,securitySolution,case,infra,monitoring,logstash,apm,uptime]
log [22:30:22.483] [info][plugins][taskManager] TaskManager is identified by the Kibana UUID: xxxxxx
...
如果是后台启动:
[elasticsearch@centos kibana-7.12.0-linux-x86_64]$ nohup ./bin/kibana &
- 界面访问
- 可以导入simple data
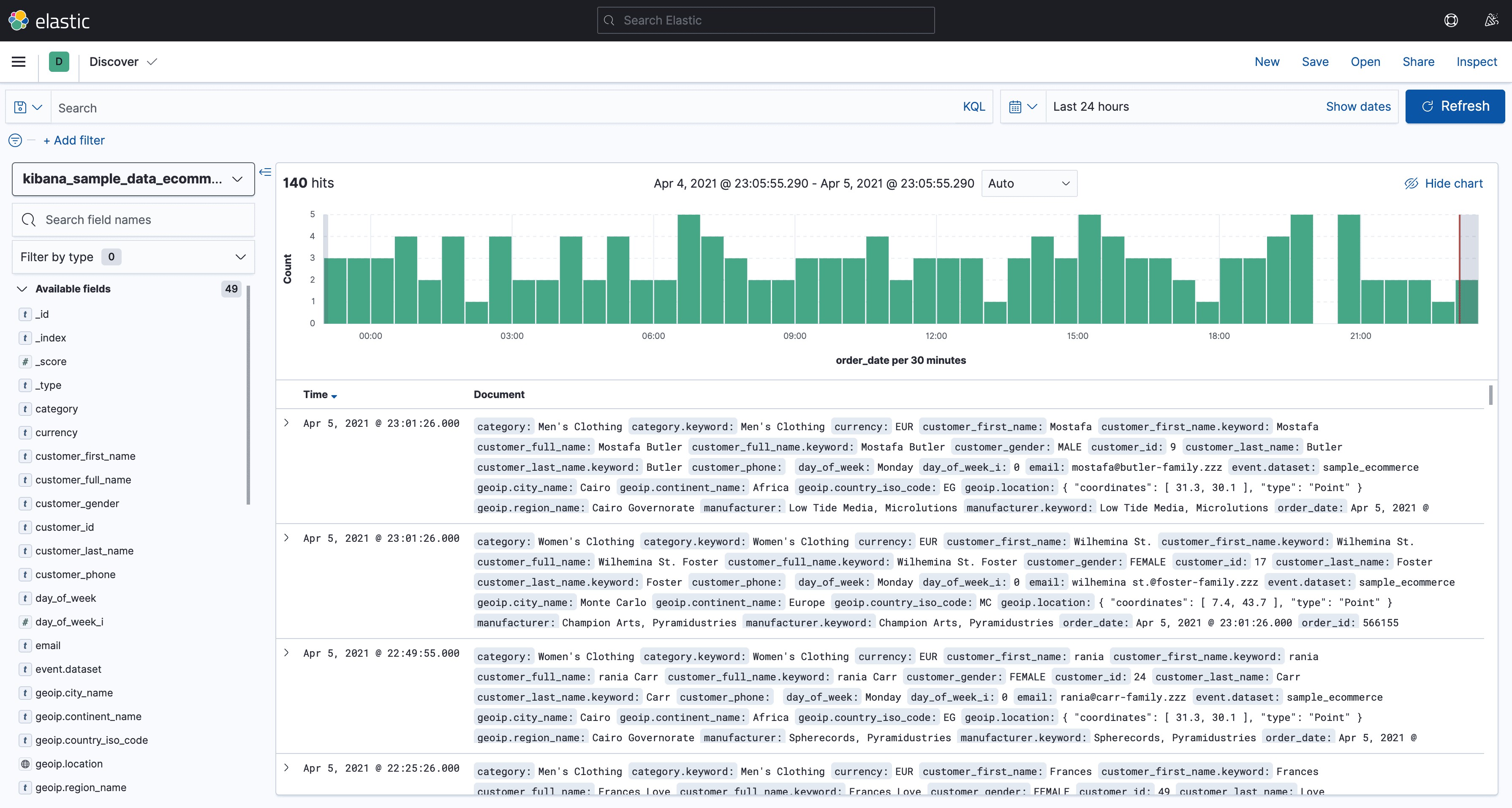
- 查看数据
- 其实以上的安装各个版本大同小异,都相差不大,所以,没有按目前的新版本来进行安装演示。官方网站也有具体的安装操作步骤,也可以参考。
配置密码访问
使用基本许可证时,默认情况下禁用Elasticsearch安全功能。由于我测试环境是放在公网上的,所以需要设置下密码访问。相关文档可以参考:https://www.elastic.co/guide/en/elasticsearch/reference/7.12/security-minimal-setup.html
- 停止kibana和elasticsearch服务
- 将xpack.security.enabled设置添加到ES_PATH_CONF/elasticsearch.yml文件并将值设置为true
- 启动elasticsearch (./bin/elasticsearch -d)
- 执行如下密码设置器,./bin/elasticsearch-setup-passwords interactive来设置各个组件的密码
- 将elasticsearch.username设置添加到KIB_PATH_CONF/kibana.yml 文件并将值设置给elastic用户: elasticsearch.username: "elastic"
- 创建kibana keystore, ./bin/kibana-keystore create
- 在kibana keystore 中添加密码 ./bin/kibana-keystore add elasticsearch.password
- 重启kibana 服务即可 nohup ./bin/kibana &
然后就可以使用密码登录了:
查询和聚合的基础使用
安装完ElasticSearch 和 Kibana后,为了快速上手,我们通过官网GitHub提供的一个数据进行入门学习,主要包括查询数据和聚合数据。
从索引文档开始
- 索引一个文档
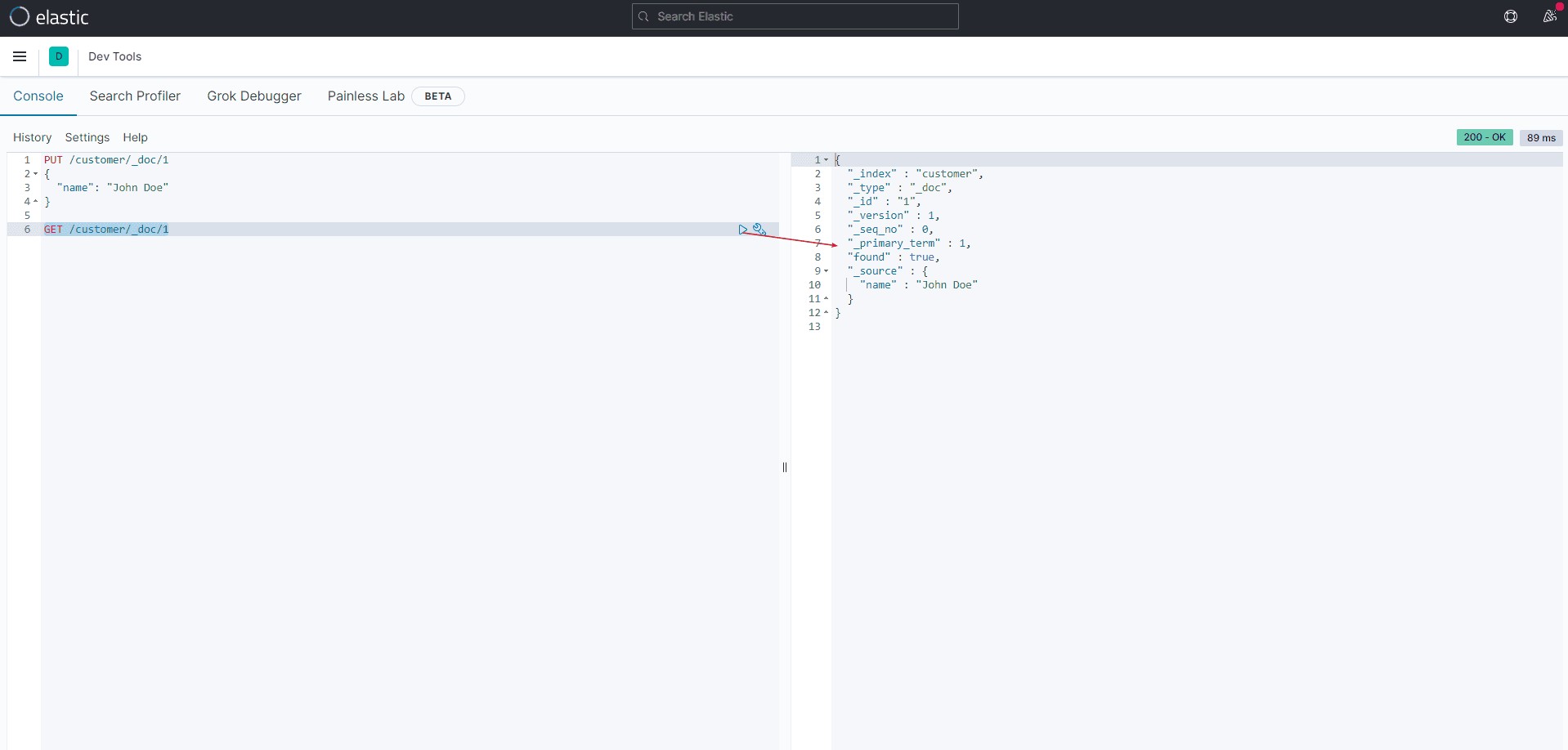
PUT /customer/_doc/1
{
"name": "John Doe"
}为了方便测试,我们使用kibana的dev tool来进行学习测试:
查询刚才插入的文档
学习准备:批量索引文档
ES 还提供了批量操作,比如这里我们可以使用批量操作来插入一些数据,供我们在后面学习使用。使用批量来批处理文档操作比单独提交请求要快得多,因为它减少了网络往返。
下载测试数据数据是index为bank,accounts.json 下载地址:https://github.com/elastic/elasticsearch/blob/v6.8.18/docs/src/test/resources/accounts.json(如果你无法下载,也可以clone ES的官方仓库:https://github.com/elastic/elasticsearch,选择本文中使用的版本分支,然后进入/docs/src/test/resources/accounts.json目录获取)。
数据的格式如下:
{批量插入数据
"account_number": 0,
"balance": 16623,
"firstname": "Bradshaw",
"lastname": "Mckenzie",
"age": 29,
"gender": "F",
"address": "244 Columbus Place",
"employer": "Euron",
"email": "bradshawmckenzie@euron.com",
"city": "Hobucken",
"state": "CO"
}将accounts.json拷贝至指定目录,我这里放在/opt/下面,然后执行:
curl -H "Content-Type: application/json" -XPOST "localhost:9200/bank/_bulk?pretty&refresh" --data-binary "@/opt/accounts.json"
查看状态[elasticsearch@centos root]$ curl "localhost:9200/_cat/indices?v=true" | grep bank
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1524 100 1524 0 0 119k 0 --:--:-- --:--:-- --:--:-- 124k
yellow open bank yq3eSlAWRMO2Td0Sl769rQ 1 1 1000 0 379.2kb 379.2kb查询数据
我们通过kibana来进行查询测试。
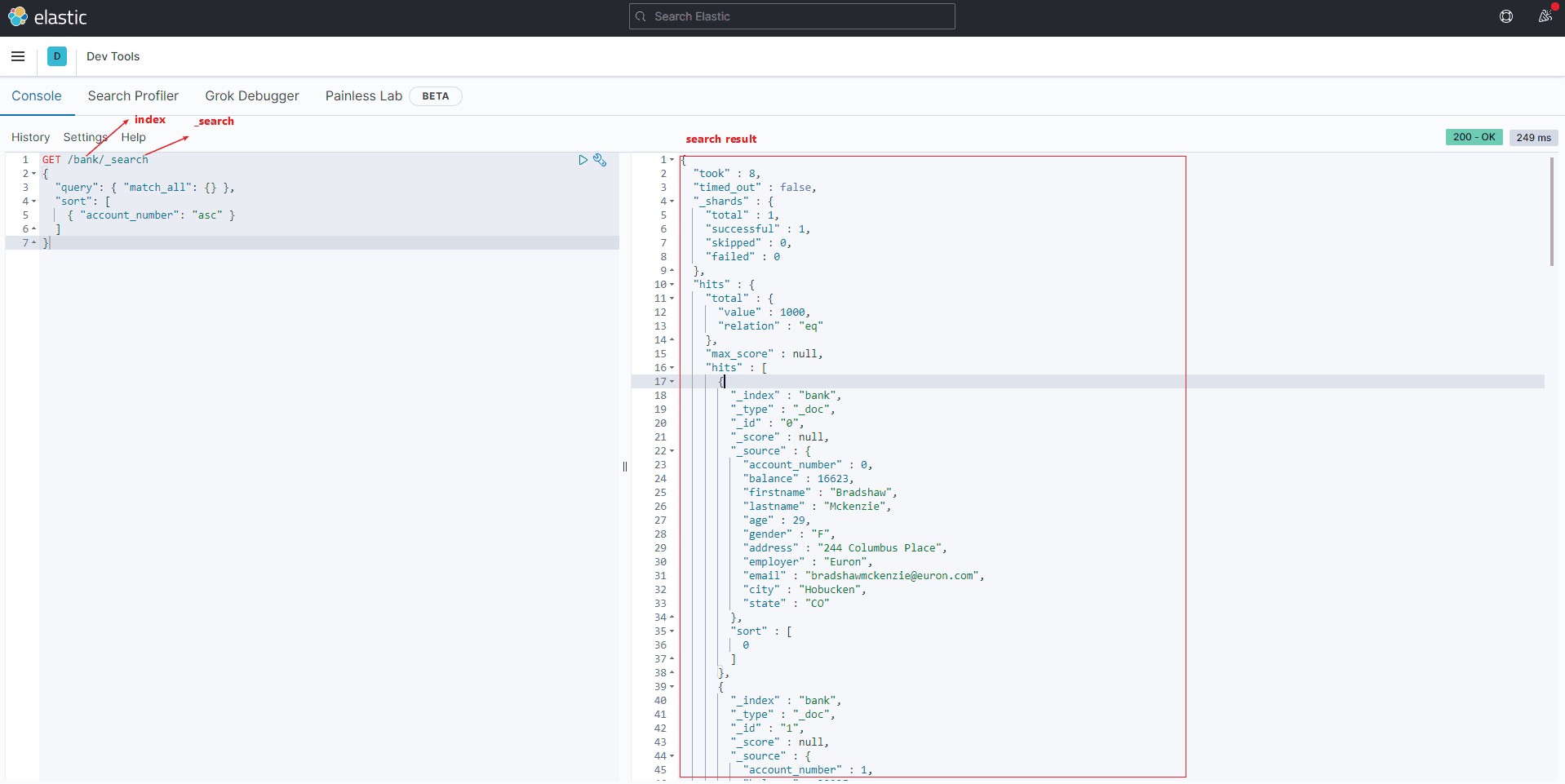
查询所有match_all表示查询所有的数据,sort即按照什么字段排序
GET /bank/_search
{
"query": { "match_all": {} },
"sort": [
{ "account_number": "asc" }
]
}1结果
相关字段解释
- took – Elasticsearch运行查询所花费的时间(以毫秒为单位)
- timed_out –搜索请求是否超时
- _shards - 搜索了多少个碎片,以及成功,失败或跳过了多少个碎片的细目分类。
- max_score – 找到的最相关文档的分数
- hits.total.value - 找到了多少个匹配的文档
- hits.sort - 文档的排序位置(不按相关性得分排序时)
- hits._score - 文档的相关性得分(使用match_all时不适用)
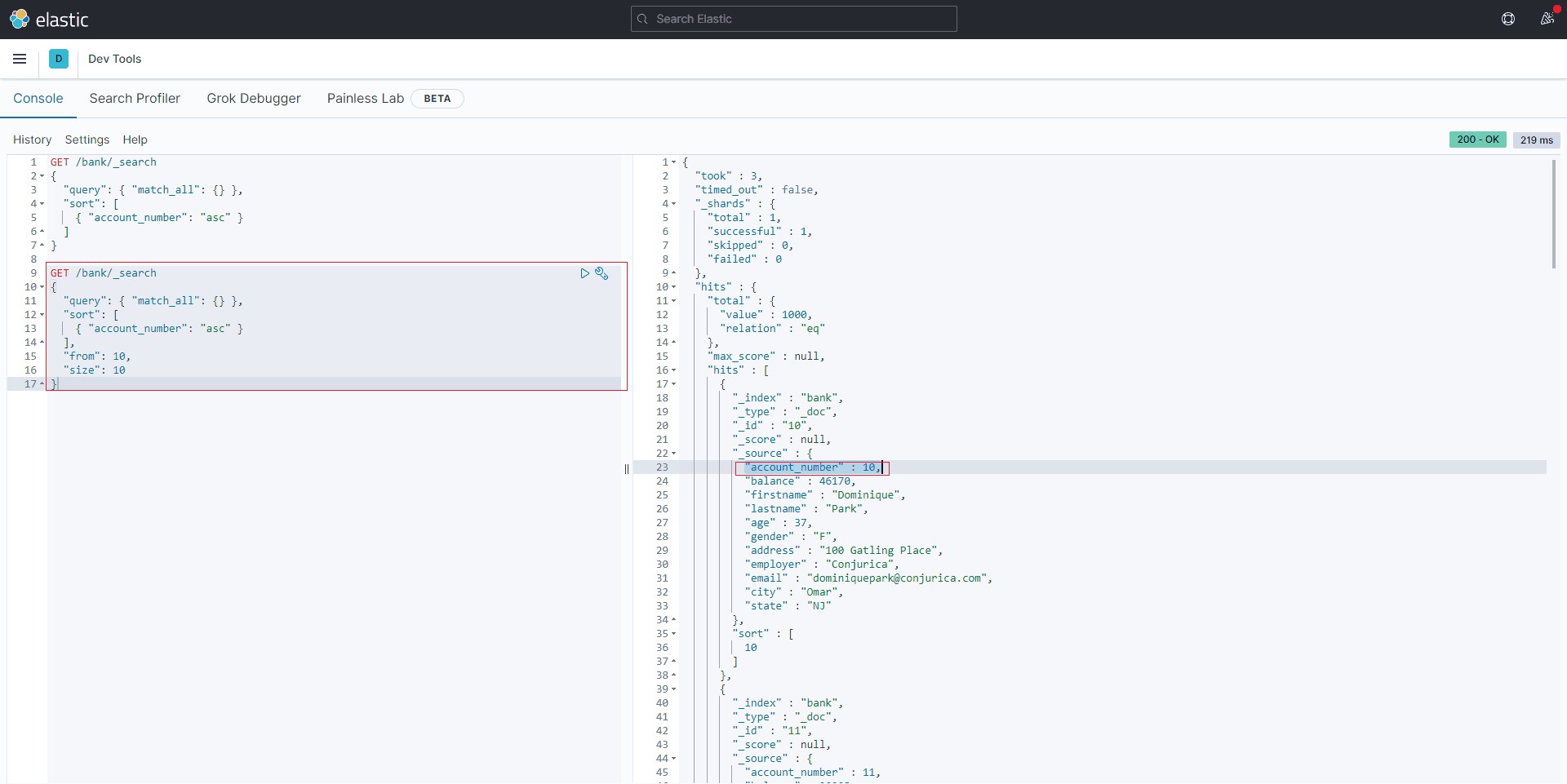
本质上就是from和size两个字段
GET /bank/_search
{
"query": { "match_all": {} },
"sort": [
{ "account_number": "asc" }
],
"from": 10,
"size": 10
}2结果
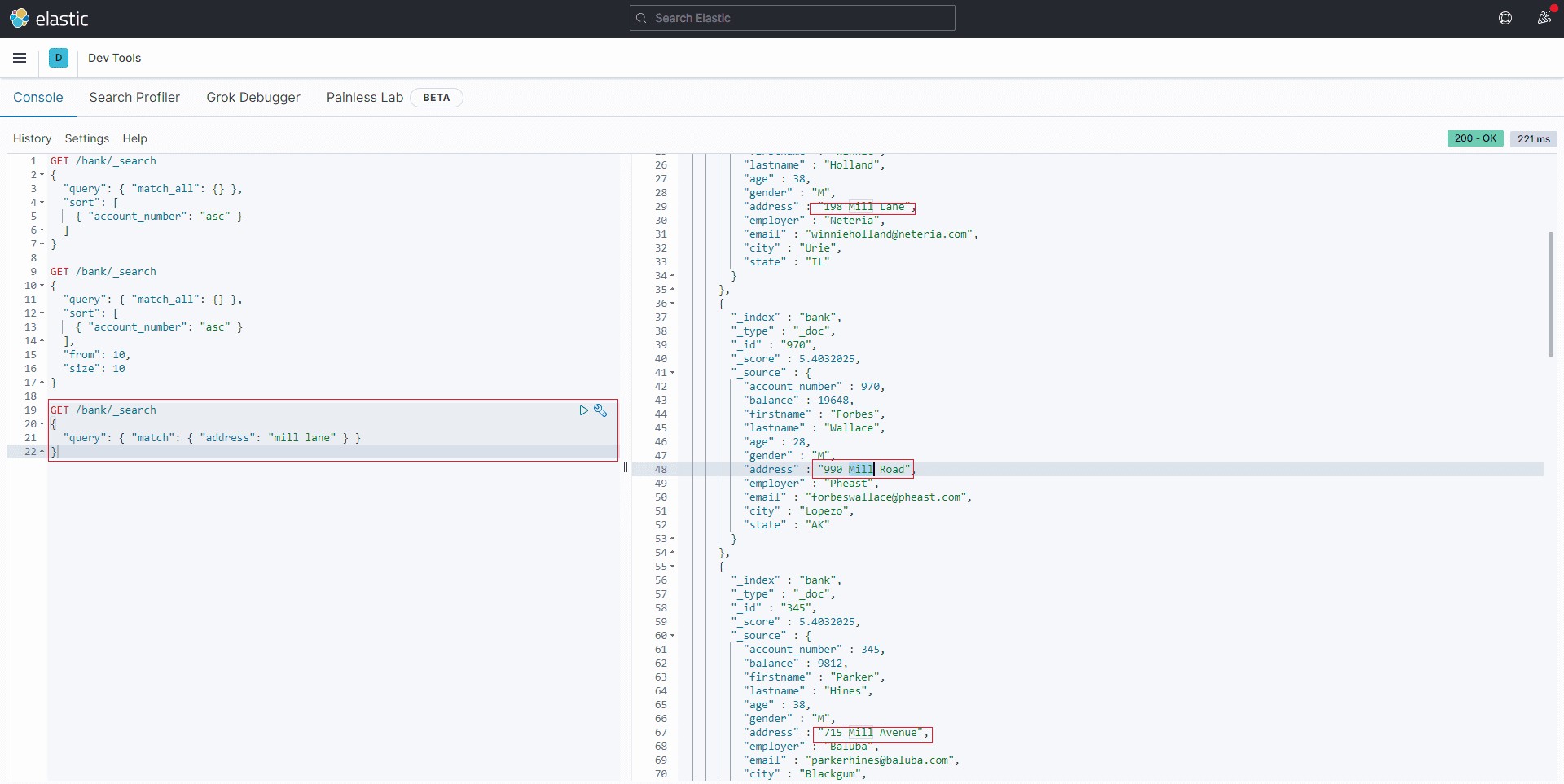
指定字段查询:match如果要在字段中搜索特定字词,可以使用match; 如下语句将查询address 字段中包含 mill 或者 lane的数据。
GET /bank/_search
{
"query": { "match": { "address": "mill lane" } }
}3结果
(由于ES底层是按照分词索引的,所以上述查询结果是address 字段中包含 mill 或者 lane的数据)。
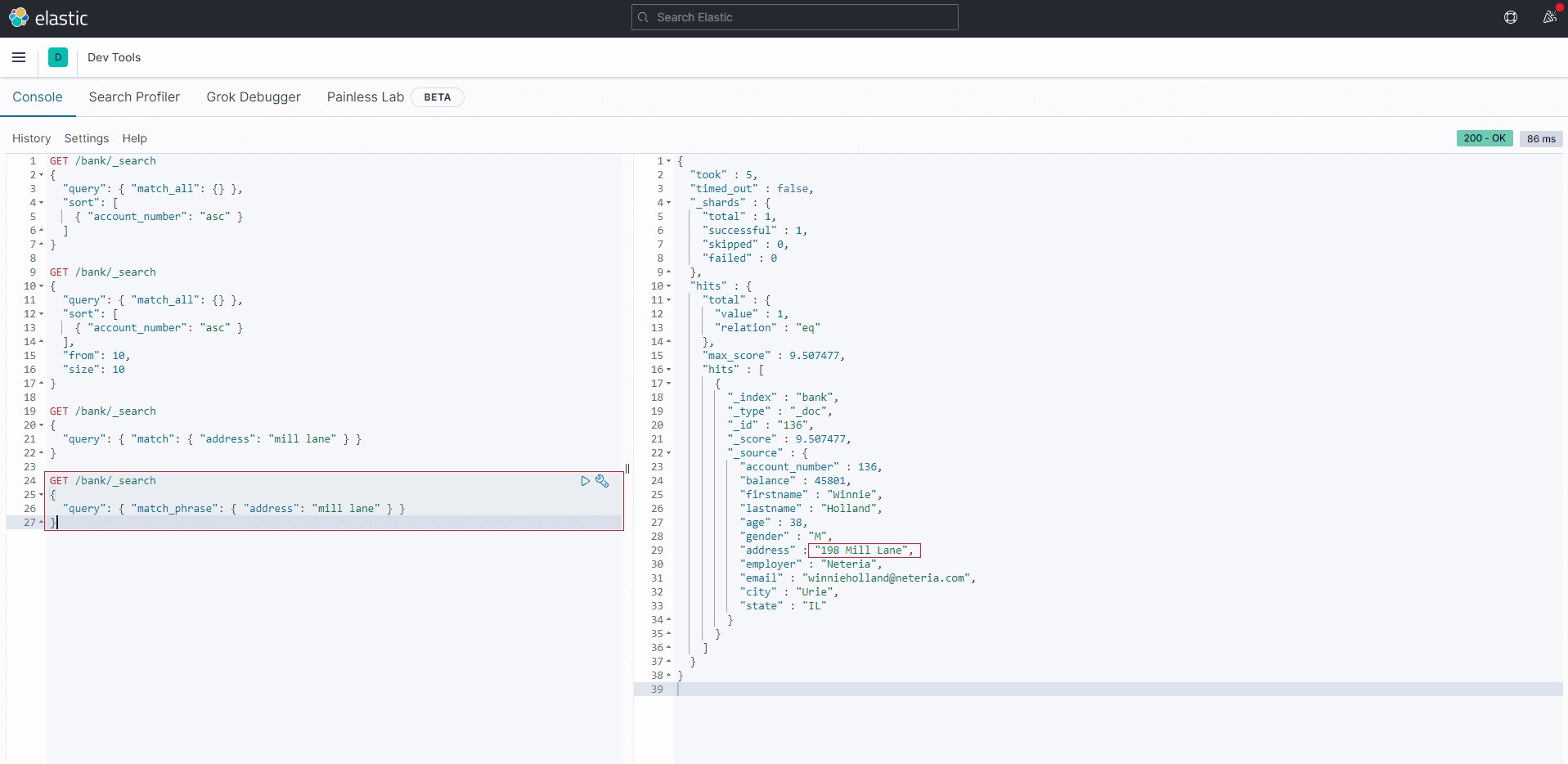
查询段落匹配:match_phrase如果我们希望查询的条件是 address字段中包含 "mill lane",则可以使用match_phrase。
GET /bank/_search
{
"query": { "match_phrase": { "address": "mill lane" } }
}4结果
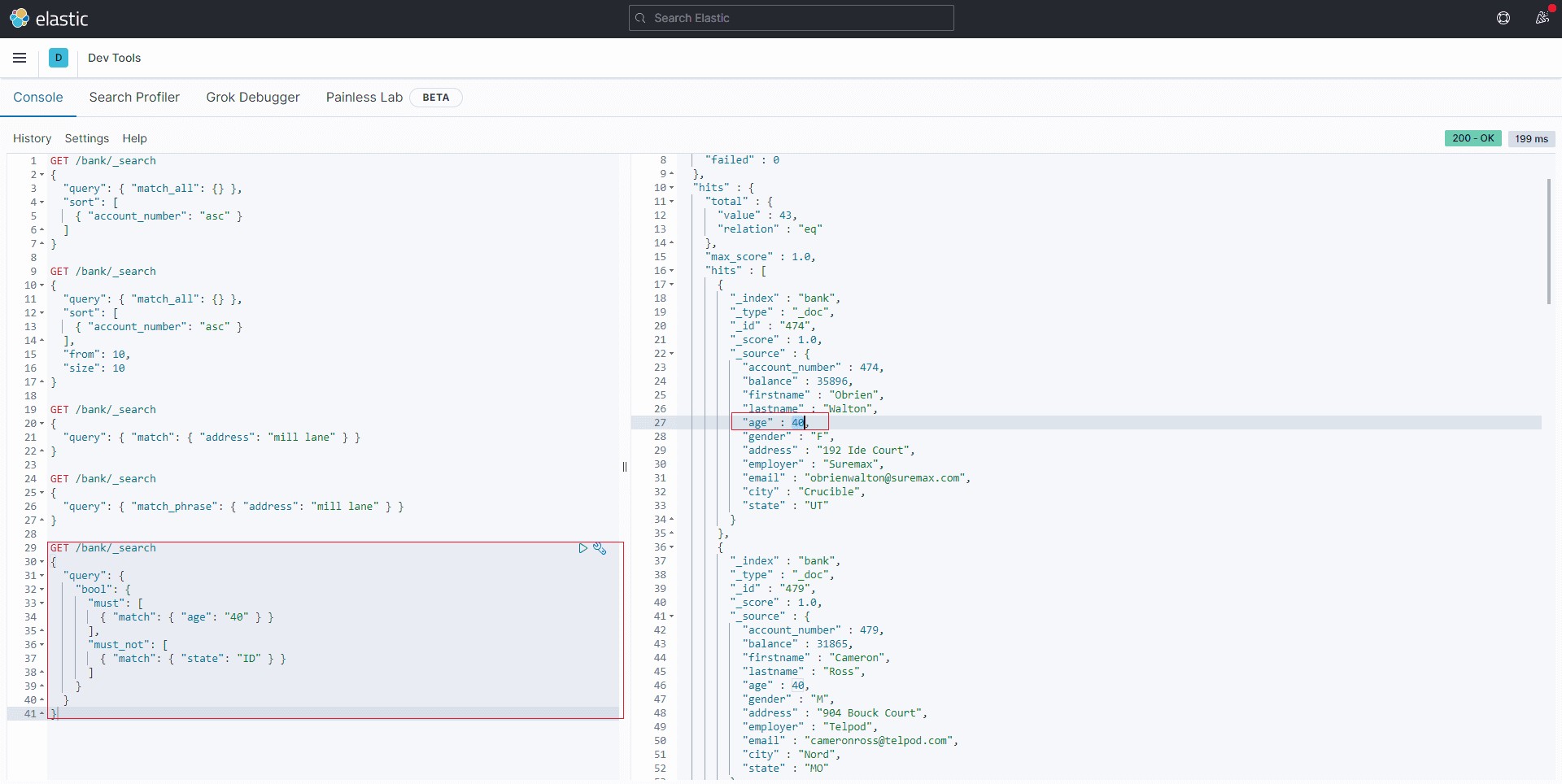
多条件查询: bool如果要构造更复杂的查询,可以使用bool查询来组合多个查询条件。例如,以下请求在bank索引中搜索40岁客户的帐户,但不包括居住在爱达荷州(ID)的任何人。
GET /bank/_search
{
"query": {
"bool": {
"must": [
{ "match": { "age": "40" } }
],
"must_not": [
{ "match": { "state": "ID" } }
]
}
}
}5结果
must, should, must_not 和 filter 都是bool查询的子句。那么filter和上述query子句有啥区别呢?
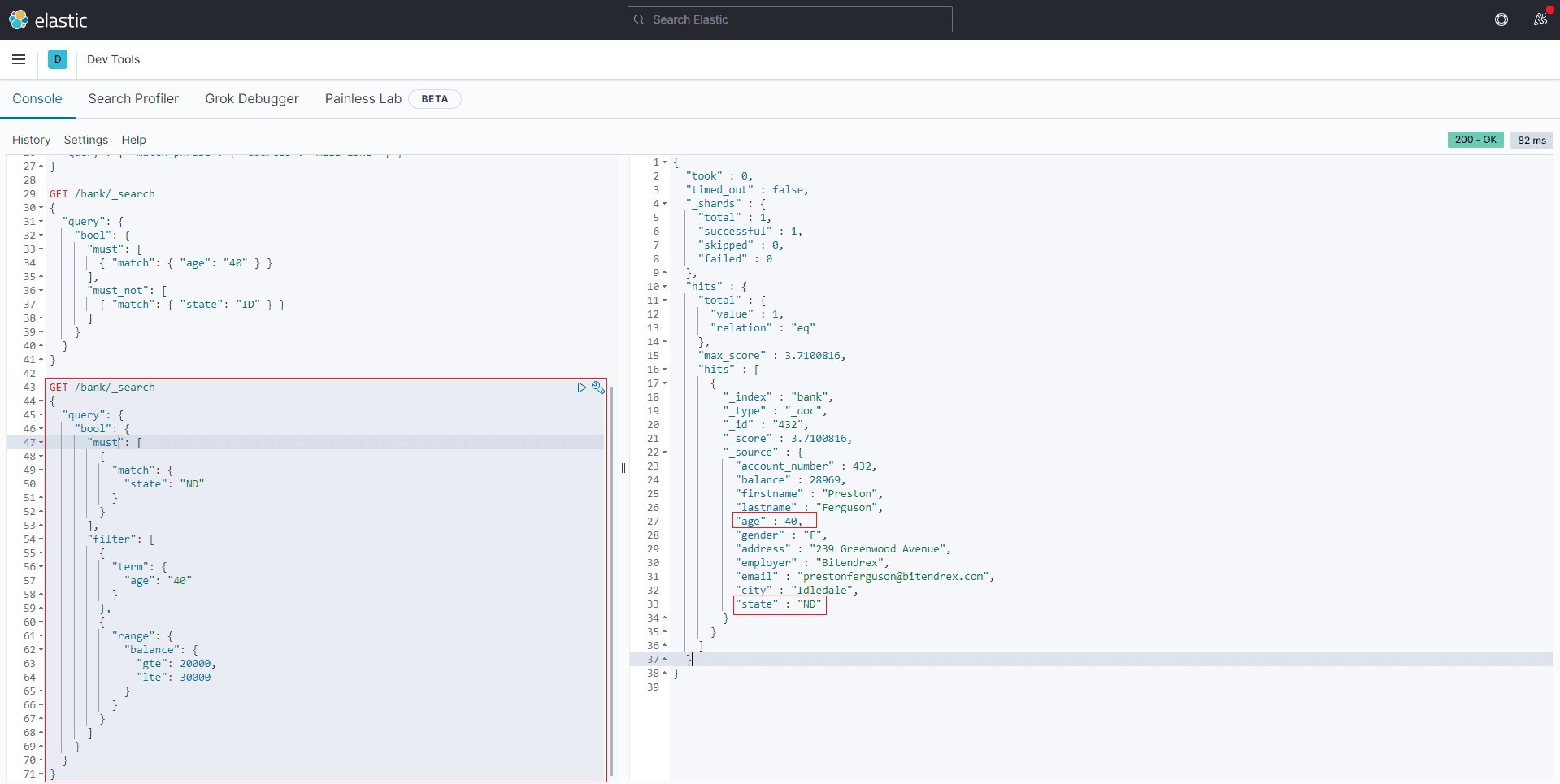
查询条件:query or filter先看下如下查询, 在bool查询的子句中同时具备query/must 和 filter。
GET /bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"state": "ND"
}
}
],
"filter": [
{
"term": {
"age": "40"
}
},
{
"range": {
"balance": {
"gte": 20000,
"lte": 30000
}
}
}
]
}
}
}6结果
两者都可以写查询条件,而且语法也类似。区别在于,query 上下文的条件是用来给文档打分的,匹配越好 _score 越高;filter 的条件只产生两种结果:符合与不符合,后者被过滤掉。
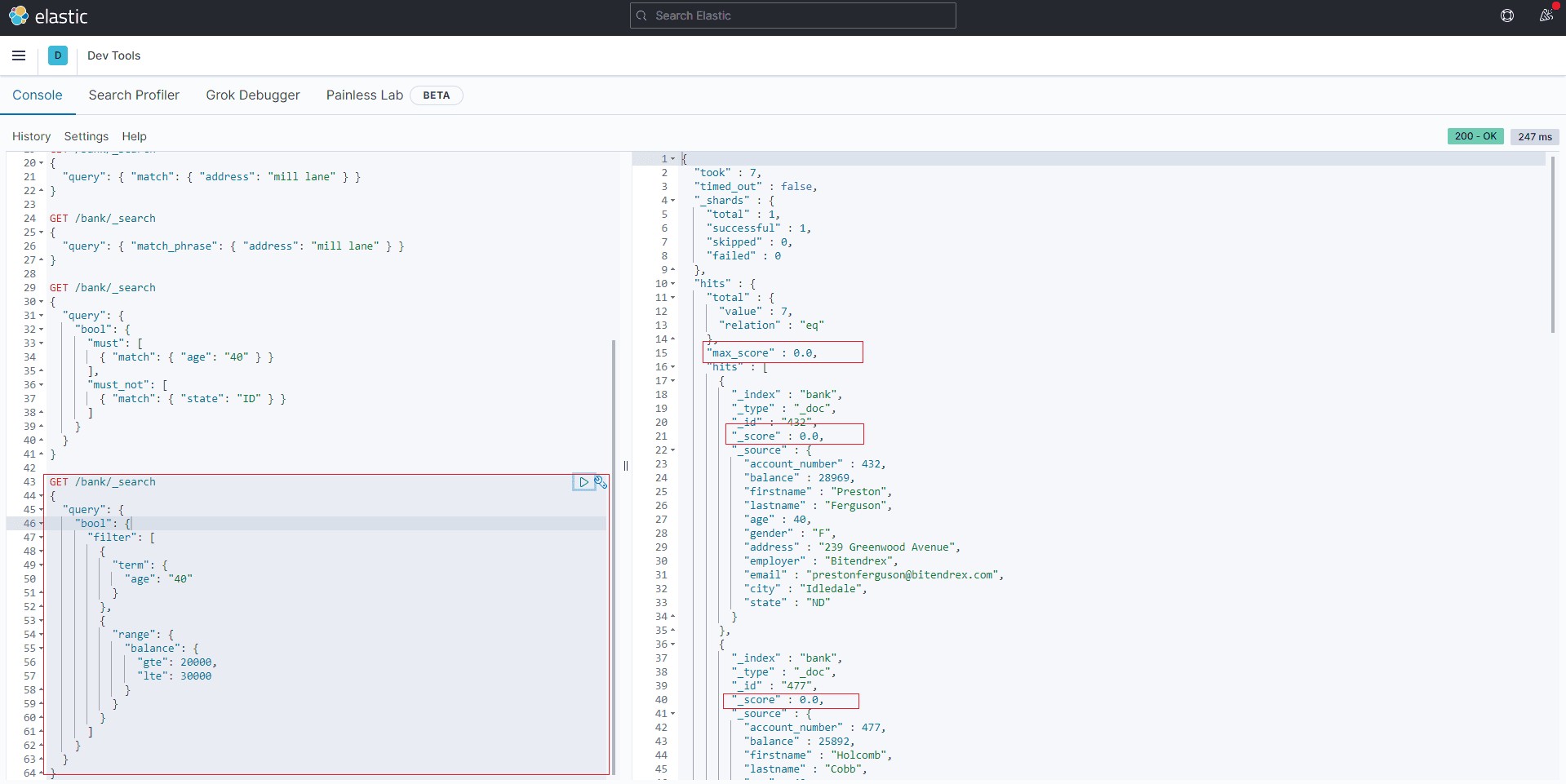
所以,我们进一步看只包含filter的查询。
GET /bank/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"age": "40"
}
},
{
"range": {
"balance": {
"gte": 20000,
"lte": 30000
}
}
}
]
}
}
}结果,显然无_score
聚合查询:Aggregation
我们知道SQL中有group by,在ES中它叫Aggregation,即聚合运算。
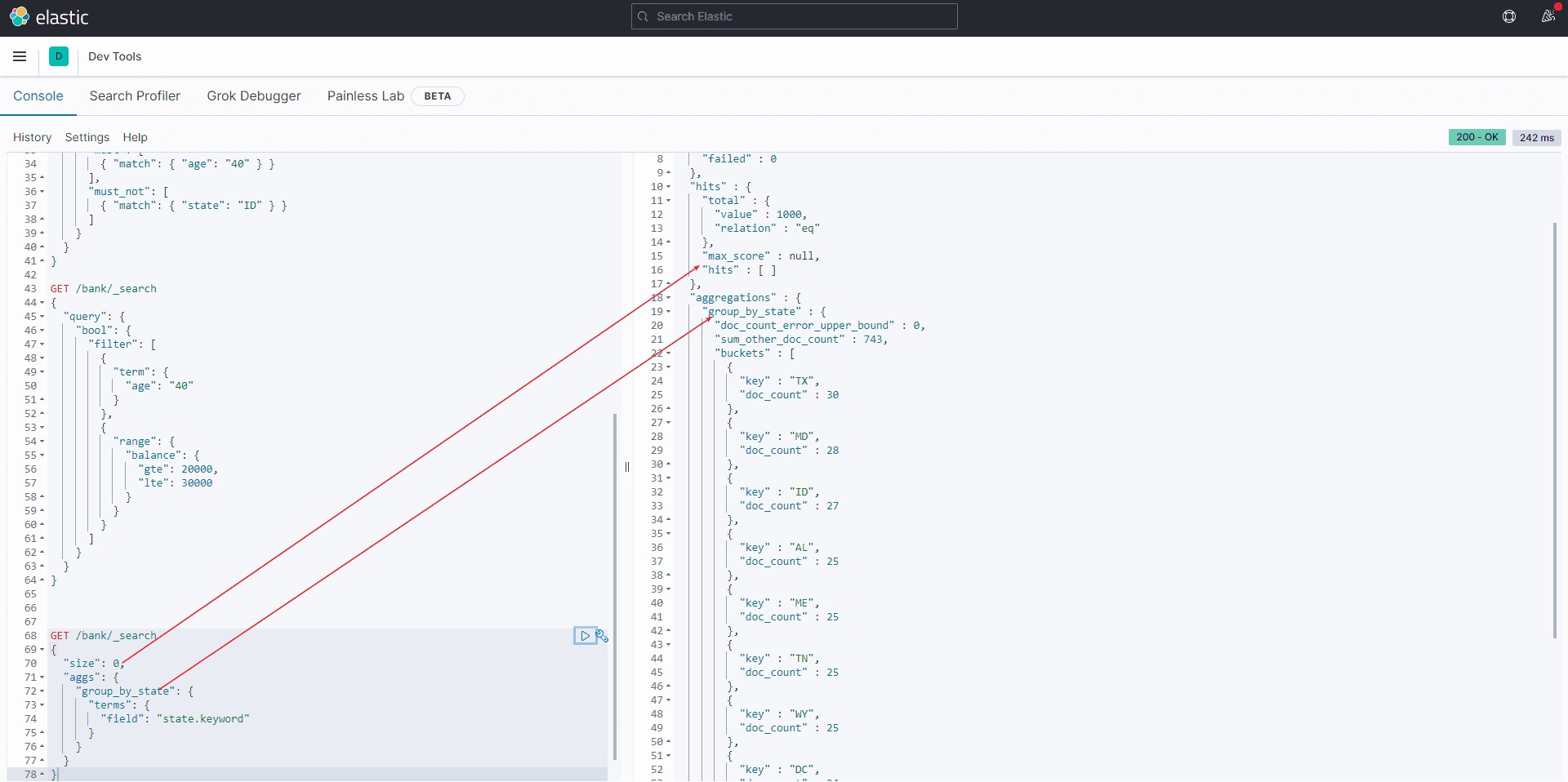
简单聚合比如我们希望计算出account每个州的统计数量, 使用aggs关键字对state字段聚合,被聚合的字段无需对分词统计,所以使用state.keyword对整个字段统计。
GET /bank/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
}
}
}
}7结果
因为无需返回条件的具体数据, 所以设置size=0,返回hits为空。
doc_count表示bucket中每个州的数据条数。
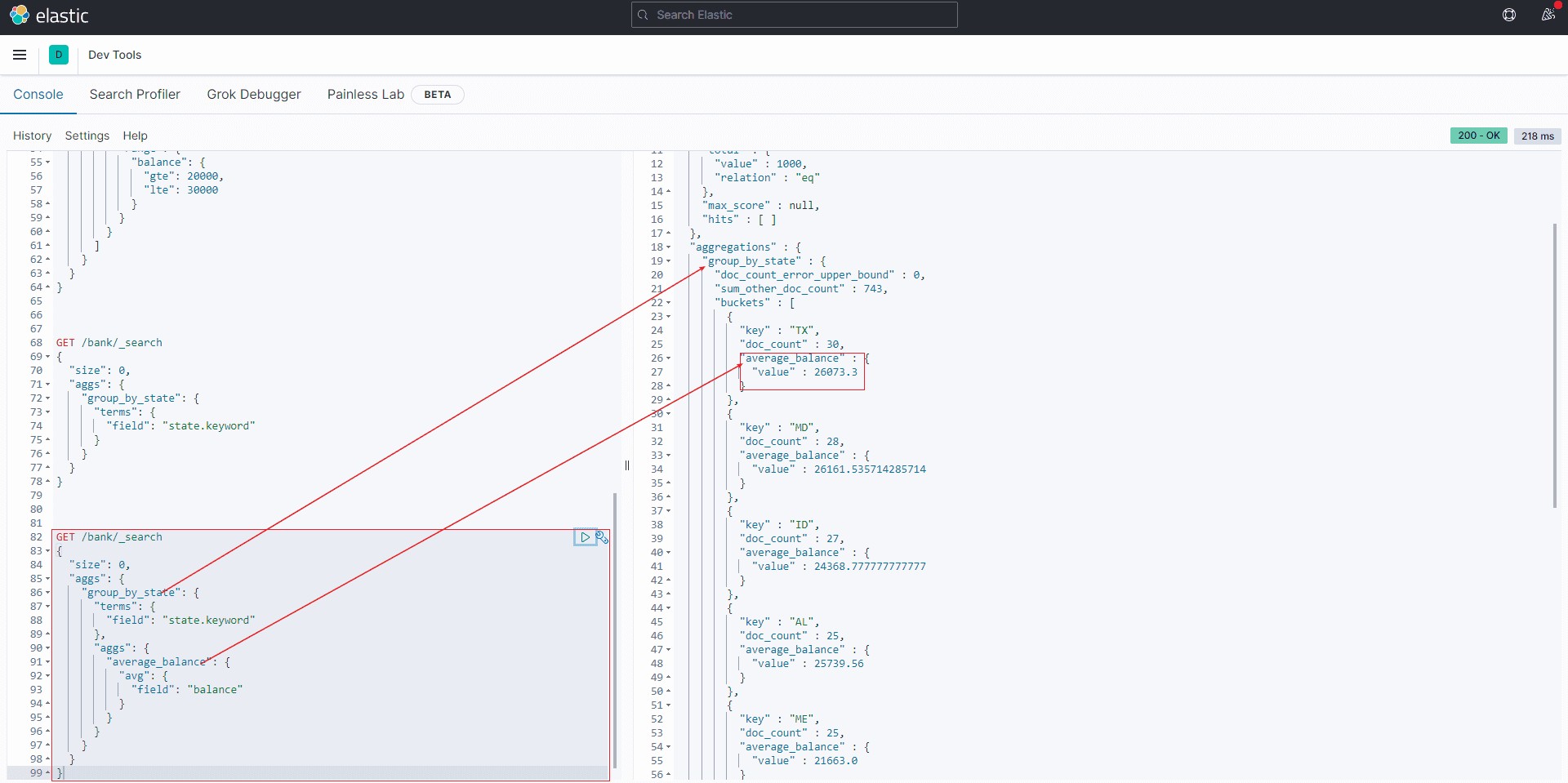
嵌套聚合ES还可以处理个聚合条件的嵌套。比如承接上个例子, 计算每个州的平均结余。涉及到的就是在对state分组的基础上,嵌套计算avg(balance):
GET /bank/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}8结果
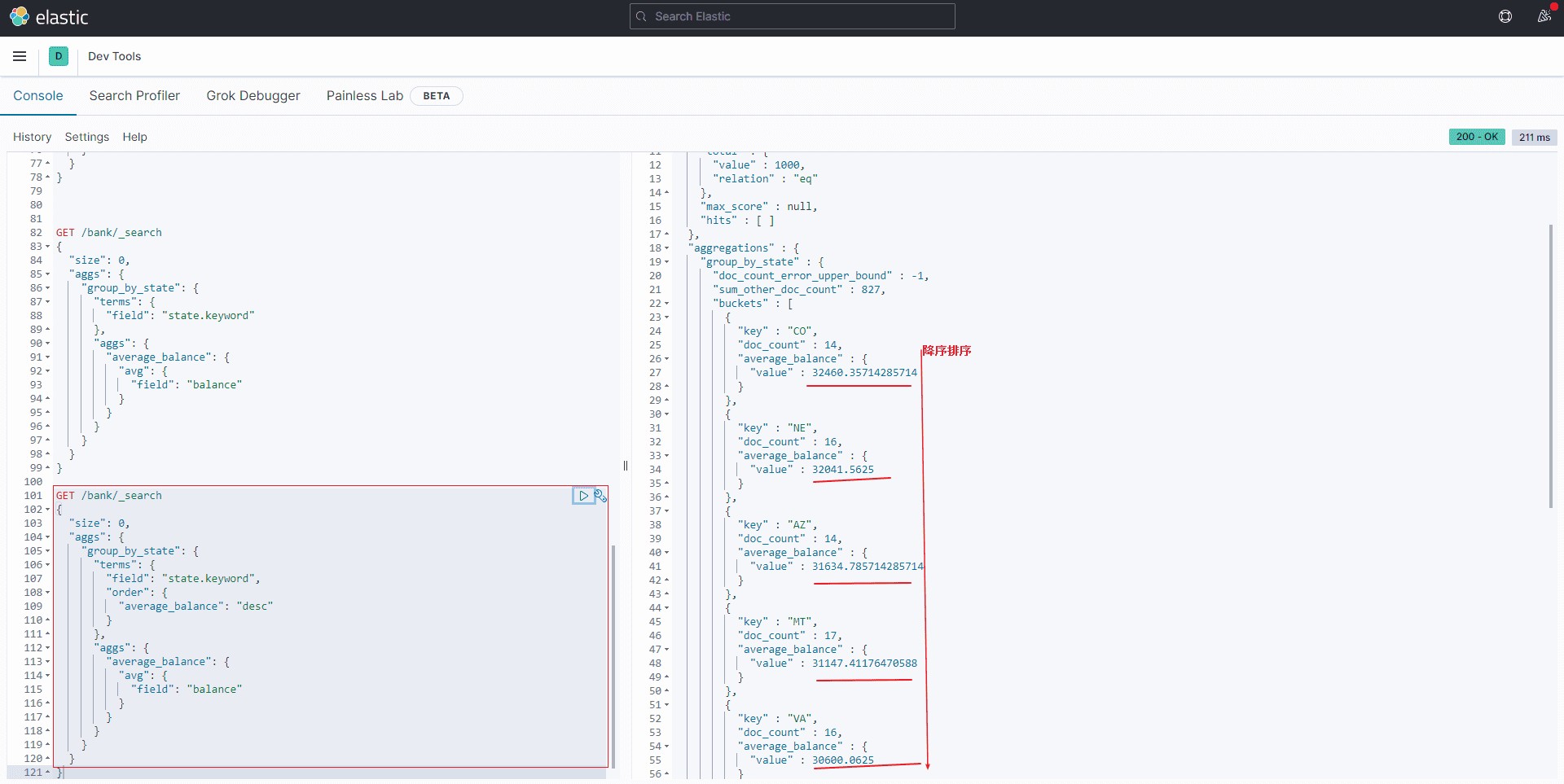
对聚合结果排序可以通过在aggs中对嵌套聚合的结果进行排序。比如承接上个例子, 对嵌套计算出的avg(balance),这里是average_balance,进行排序。
GET /bank/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword",
"order": {
"average_balance": "desc"
}
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}9结果
- 发表于 2023-06-16 10:25
- 阅读 ( 47 )
