进击大数据系列(十一)Hadoop 任务调度框架 Oozie
前面介绍了前面介绍了 Hadoop 基本概念与生态、安装(HDFS+YARN+MapReduce)实战操作、常用命令、架构基石 HDFS、统一资源管理和调度平台 YARN、分布式计算框架 MapReduce 、数据仓库 Hive、计算引擎 Spark、实时计算流计算引擎 Flink、 数据库 Hbase等相关的知识点,今天我将详细的为大家介绍 大数据 Hadoop 任务调度器 Oozie 相关知识。
Oozie 是大数据四大协作框架之一——任务调度框架,另外三个分别为数据转换工具 Sqoop,文件收集库框架 Flume,大数据 WEB 工具 Hue,这三个后面的文章将逐一给大家介绍。
Oozie 概述
Oozie 是一个用来管理 Hadoop 生态圈 job 的工作流调度系统。由 Cloudera公司贡献给 Apache。

Oozie 是运行于 Java servlet 容器上的一个 java web 应用。Oozie 的目的是按照 DAG(有向无环图)调度一系列的 Map/Reduce 或者 Hive等任务。Oozie 工作流由 hPDL(Hadoop Process Definition Language)定义(这是一种 XML 流程定义语言)。适用场景包括:
- 需要按顺序进行一系列任务;
- 需要并行处理的任务;
- 需要定时、周期触发的任务;
- 可视化作业流运行过程;
- 运行结果或异常的通报。
Oozie 发展至今已经到 5.X 版本,在前面的几个版本中,Oozie 经历了如下发展:
- Oozie v1 是一个基于工作流引擎的调度框架(base WorkFlow Engine),你可以指定工作流job来运行hadoop mapreduce任务或者pig任务。
- Oozie v2 是一个基于协调调度的框架(base Coordinator Engine),你可以指定工作流基于时间和数据来进行调度,可以基于一个时间点来调度工作流,也可以基于数据(hdfs)来调度工作流。
- Oozie v3 是一个基于绑定引擎的框架(base Bundle Engine),它提供了更高层次的API来bundle一系列coordinator application,用户可以使用start/stop/resume/suspend/return 来更好的操作和控制一系列coordinator application。
Oozie的特点
- Oozie 是管理hadoop作业的调度系统
- Oozie 的工作流作业是一系列动作的有向无环图(DAG)
- Oozie 协调作业是通过时间(频率)和有效数据触发当前的Oozie工作流程
- Oozie 支持各种hadoop作业,例如:java map-reduce、Streaming map-reduce、pig、hive、sqoop和distcp等等,也支持系统特定的作业,例如java程序和shell脚本。
- Oozie 是一个可伸缩,可靠和可拓展的系统
为什么选择Oozie
在没有工作流调度系统之前,公司里面的任务都是通过 crontab 来定义的,时间长了后会发现很多问题:
- 1.大量的crontab任务需要管理
- 2.任务没有按时执行,各种原因失败,需要重试
- 3.多服务器环境下,crontab分散在很多集群上,光是查看log就很花时间
于是,出现了一些管理crontab任务的调度系统,如 CronHub、CronWeb 等。而在大数据领域,现在市面上常用的工作流调度工具有Oozie, Azkaban,Cascading,Hamake等。更多关于大数据 Hadoop系列的学习文章,请参阅:大数据 Hadoop 系列,本系列持续更新中。
Oozie和Azkaban对比
两者在功能方面大致相同,只是Oozie底层在提交Hadoop Spark作业是通过org.apache.hadoop的封装好的接口进行提交,而Azkaban可以直接操作shell语句。在安全性上可能Oozie会比较好。
- 工作流定义: Oozie是通过xml定义的而Azkaban为properties来定义。
- 部署过程: Oozie的部署相对困难些,同时它是从Yarn上拉任务日志。
- 任务检测: Azkaban中如果有任务出现失败,只要进程有效执行,那么任务就算执行成功,这是BUG,但是Oozie能有效的检测任务的成功与失败。
- 操作工作流: Azkaban使用Web操作。Oozie支持Web,RestApi,Java API操作。
- 权限控制: Oozie基本无权限控制,Azkaban有较完善的权限控制,供用户对工作流读写执行操作。
- 运行环境: Oozie的action主要运行在hadoop中而Azkaban的actions运行在Azkaban的服务器中。
- 记录workflow的状态: Azkaban将正在执行的workflow状态保存在内存中,Oozie将其保存在Mysql中。
- 出现失败的情况: Azkaban会丢失所有的工作流,但是Oozie可以在继续失败的工作流运行
Oozie 的架构
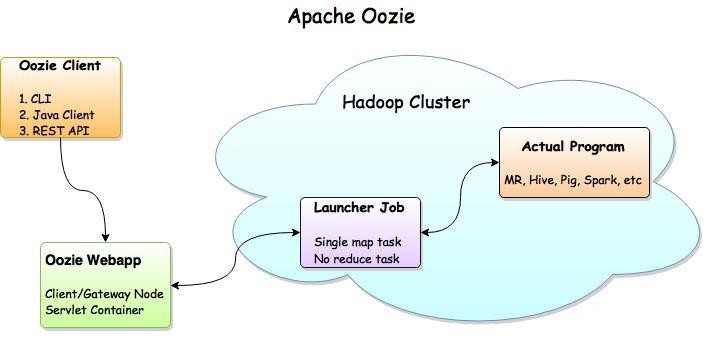
Oozie Client:提供命令行、java api、rest 等方式,对 Oozie 的工作流流程的提交、启动、运行等操作。
Oozie WebApp:即 Oozie Server,本质是一个 java 应用。可以使用内置的web 容器,也可以使用外置的 web 容器;Hadoop Cluster:底层执行 Oozie 编排流程的各个 hadoop 生态圈组件。
Oozie 基本原理
Oozie 对工作流的编排,是基于 workflow.xml 文件来完成的。用户预先将工作流执行规则定制于 workflow.xml 文件中,并在 job.properties 配置相关的参数,然后由 Oozie Server 向 MR 提交 job 来启动工作流。
流程节点
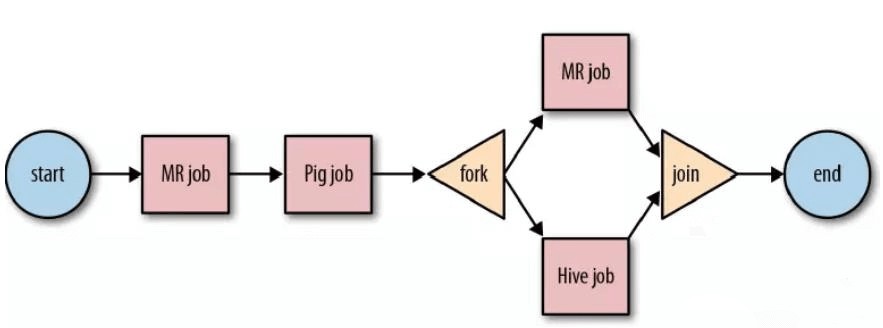
工作流由两种类型的节点组成,分别是:Control Flow Nodes:控制工作流执行路径,包括 start,end,kill,decision,fork,join。Action Nodes:决定每个操作执行的任务类型,包括 MapReduce、java、hive、shell 等。

Oozie 工作流类型
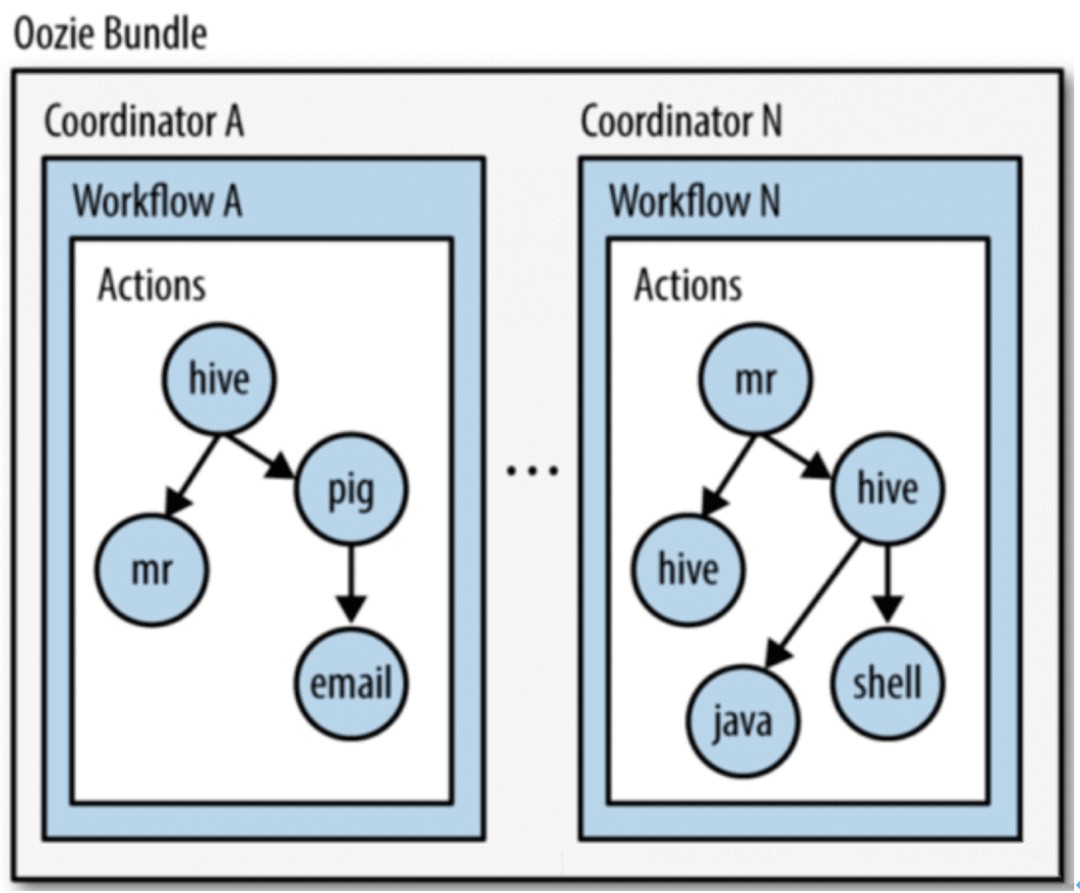
规则相对简单,不涉及定时、批处理的工作流。顺序执行流程节点。Workflow 有个大缺点:没有定时和条件触发功能。
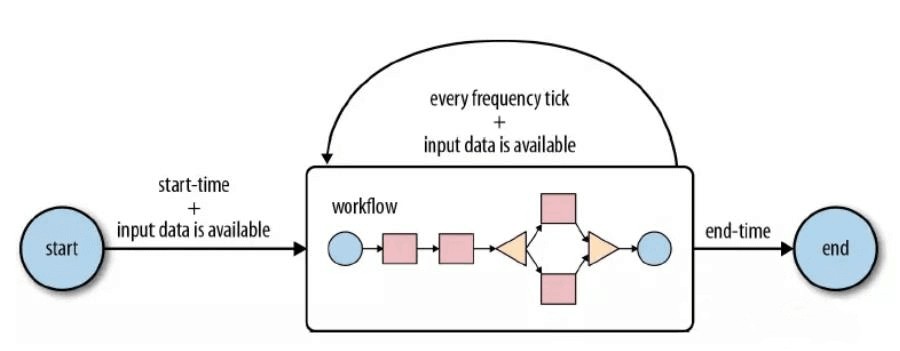
Coordinator 将多个工作流 Job 组织起来,称为 Coordinator Job,并指定触发时间和频率,还可以配置数据集、并发数等,类似于在工作流外部增加了一个协调器来管理这些工作流的工作流 Job 的运行。
针对 coordinator 的批处理工作流。Bundle 将多个 Coordinator 管理起来,这样我们只需要一个 Bundle 提交即可。
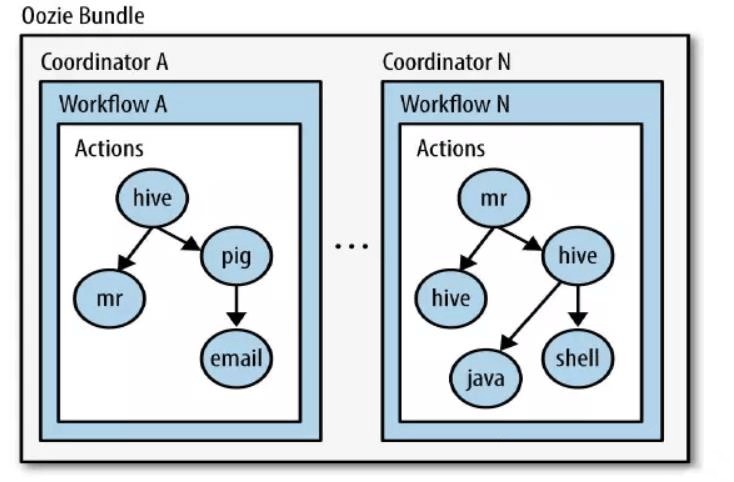
Oozie安装、启动
首先需要下载oozie,Apache版本的oozie需要自己编译,不过这里不进行编译,使用CDH版本 的Oozie。读者可自行去CDH官方网站下载。
这里使用Oozie4.0.0版本,安装环境要求如下:
- Unix box (tested on Mac OS X and Linux)
- Java JDK 1.6+
- Maven 3.0.1+
- Hadoop 0.20.2+
- Pig 0.7+
除了需要下载Oozie压缩包外,读者还需要有hadoop环境,此外,需要下载ext.js的压缩包。这里使用hadoop2.5.0版本,用户可以下载适当版本的oozie和hadoop版本 安装即可。
解压好Oozie安装包之后,首先在hadoop配置文件中为Oozie进程配置代理用户,在core-site.xml文件中配置如下:
<property><name>hadoop.proxyuser.[OOZIE_SERVER_USER].hosts</name><value>[OOZIE_SERVER_HOSTNAME]</value></property><property><name>hadoop.proxyuser.[OOZIE_SERVER_USER].groups</name><value>[USER_GROUPS_THAT_ALLOW_IMPERSONATION]</value></property>
OOZIE_SERVER_USER是你的服务器用户名,OOZIE_SERVER_HOSTNAME是主机名,USER_GROUPS_THAT_ALLOW_IMPERSONATION一般填*,表示所有组。
解压好的oozie安装包里的目录如下图所示(这里是我们配置好的截图,具体可以看目录作用可以看官网介绍)。
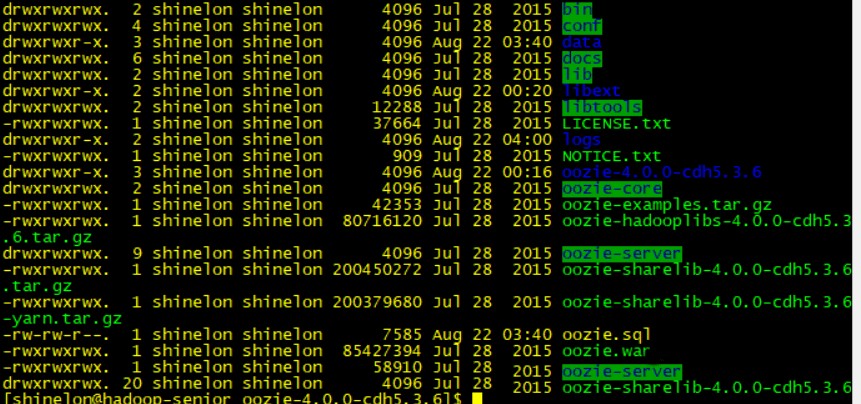
这里需要将hadoop-lib文件解压,即上图中的oozie-hadooplibs-4.0.0-cdh5.3.6.tar.gz压缩包解压,解压之后目录如上图所示,为oozie-4.0.0-cdh5.3.6,在该目录下,有一个hadooplibs目录,这个目录下有两个文件:
hadooplib-2.5.0-cdh5.3.6.oozie-4.0.0-cdh5.3.6
hadooplib-2.5.0-mr1-cdh5.3.6.oozie-4.0.0-cdh5.3.6
这两个文件是oozie为hadoop提供的支持类库,第一个是hadoop2的类库,第二个是hadoop1的类库,在后面配置时当然要选择hadoop2了。
接着,创建一个libext文件夹,将上面所说的hadoop2的类库以及ext的压缩包拷贝到这个目录下。
然后使用下面命令生成一个war包,它会将oozie部署到内嵌的tomcat容器中:
bin/oozie-setup.sh prepare-war
接着,安装sharelib,需要制定hdfs文件系统地址,然后还需要制定sharelib安装包的地址,如果不指定,它会在oozie安装目录下搜索,但是在oozie安装目录下有两个sharelib压缩包,记住,必须选择支持yarn的压缩包,命令如下所示:
bin/oozie-setup.sh sharelib create -fs hdfs://hadoop-senior.shinelon.com:8020 -locallib oozie-sharelib-4.0.0-cdh5.3.6-yarn.tar.gz
使用oozie安装目录下自带的sql文件创建数据库:
bin/ooziedb.sh create -sqlfile oozie.sql -run DB Connection
最后,还需要在oozie-site.xml配置文件中指定hadoop配置文件的目录:
<property>
<name>
oozie.service.HadoopAccessorService.hadoop.configurations
</name>
<value>*=/opt/cdh-5.3.6/hadoop-2.5.0-cdh5.3.6/etc/hadoop</value>
</property>
至此,我们完成了oozie的所有配置,可以使用如下命令运行oozie(注意,启动之前必须先启动hadoop):
bin/oozied.sh start
启动之后,可以在浏览器中通过11000端口访问oozie前端控制台,如下图所示:
Oozie Cli 命令
注意:使用Oozie之前必须先启动hdfs,yarn和jobhistory,这里jobhistory一开始很容易忘~
启动任务
oozie job -oozie oozie_url -config job.properties_address -run
停止任务
oozie job -oozie oozie_url -kill jobId -oozie-oozi -W
提交任务
oozie job -oozie oozie_url -config job.properties_address -submit
开始任务
oozie job -oozie oozie_url -config job.properties_address -startJobId -oozie-oozi -W
查看任务执行情况
oozie job -oozie oozie_url -config job.properties_address -info jobId -oozie-oozi -W
更多关于大数据 Hadoop系列的学习文章,请参阅:大数据 Hadoop 系列,本系列持续更新中。
Oozie的使用
Oozie调度shell脚本
1)解压官方案例模板
[xjl@hadoop102 oozie-4.0.0-cdh5.3.6]$ tar -zxvf oozie-examples.tar.gz
2)创建工作目录
[xjl@hadoop102 oozie-4.0.0-cdh5.3.6]$ mkdir oozie-apps/
3)拷贝任务模板到oozie-apps/目录
[xjl@hadoop102 oozie-4.0.0-cdh5.3.6]$ cp -r examples/apps/shell/ oozie-apps
4)编写脚本p1.sh
[xjl@hadoop102 oozie-4.0.0-cdh5.3.6]$ vi oozie-apps/shell/p1.sh
内容如下:
#!/bin/bash
/sbin/ifconfig > /opt/module/p1.log
5)修改job.properties和workflow.xml文件
job.properties
#HDFS地址
nameNode=hdfs://hadoop102:8020
#ResourceManager地址
jobTracker=hadoop103:8032
#队列名称
queueName=default
examplesRoot=oozie-apps
oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/shell
EXEC=p1.sh
workflow.xml
<workflow-app xmlns="uri:oozie:workflow:0.4" name="shell-wf">
<start to="shell-node"/>
<action name="shell-node">
<shell xmlns="uri:oozie:shell-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>${EXEC}</exec>
<!-- <argument>my_output=Hello Oozie</argument> -->
<file>/user/atguigu/oozie-apps/shell/${EXEC}#${EXEC}</file>
<capture-output/>
</shell>
<ok to="end"/>
<error to="fail"/>
</action>
<decision name="check-output">
<switch>
<case to="end">
${wf:actionData('shell-node')['my_output'] eq 'Hello Oozie'}
</case>
<default to="fail-output"/>
</switch>
</decision>
<kill name="fail">
<message>Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<kill name="fail-output">
<message>Incorrect output, expected [Hello Oozie] but was [${wf:actionData('shell-node')['my_output']}]</message>
</kill>
<end name="end"/>
</workflow-app>
6)上传任务配置
[xjl@hadoop102 oozie-4.0.0-cdh5.3.6]$ /opt/module/cdh/hadoop-2.5.0-cdh5.3.6/bin/hadoop fs -put oozie-apps/ /user/atguigu
7)执行任务
[xjl@hadoop102 oozie-4.0.0-cdh5.3.6]$ bin/oozie job -oozie http://hadoop102:11000/oozie -config oozie-apps/shell/job.properties -run
8)杀死某个任务
[xjl@hadoop102 oozie-4.0.0-cdh5.3.6]$ bin/oozie job -oozie http://hadoop102:11000/oozie -kill 0000004-170425105153692-oozie-z-W
Oozie逻辑调度执行多个Job
1)解压官方案例模板
[xjl@hadoop102 oozie-4.0.0-cdh5.3.6]$ tar -zxf oozie-examples.tar.gz
2)编写脚本
[xjl@hadoop102 oozie-4.0.0-cdh5.3.6]$ vi oozie-apps/shell/p2.sh
内容如下:
#!/bin/bash
/bin/date > /opt/module/p2.log
3)修改job.properties和workflow.xml文件
job.properties
nameNode=hdfs://hadoop102:8020
jobTracker=hadoop103:8032
queueName=default
examplesRoot=oozie-apps
oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/shell
EXEC1=p1.sh
EXEC2=p2.sh
workflow.xml
<workflow-app xmlns="uri:oozie:workflow:0.4" name="shell-wf">
<start to="p1-shell-node"/>
<action name="p1-shell-node">
<shell xmlns="uri:oozie:shell-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>${EXEC1}</exec>
<file>/user/atguigu/oozie-apps/shell/${EXEC1}#${EXEC1}</file>
<!-- <argument>my_output=Hello Oozie</argument>-->
<capture-output/>
</shell>
<ok to="p2-shell-node"/>
<error to="fail"/>
</action>
<action name="p2-shell-node">
<shell xmlns="uri:oozie:shell-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>${EXEC2}</exec>
<file>/user/admin/oozie-apps/shell/${EXEC2}#${EXEC2}</file>
<!-- <argument>my_output=Hello Oozie</argument>-->
<capture-output/>
</shell>
<ok to="end"/>
<error to="fail"/>
</action>
<decision name="check-output">
<switch>
<case to="end">
${wf:actionData('shell-node')['my_output'] eq 'Hello Oozie'}
</case>
<default to="fail-output"/>
</switch>
</decision>
<kill name="fail">
<message>Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<kill name="fail-output">
<message>Incorrect output, expected [Hello Oozie] but was [${wf:actionData('shell-node')['my_output']}]</message>
</kill>
<end name="end"/>
</workflow-app>
3)上传任务配置
$ bin/hadoop fs -rmr /user/atguigu/oozie-apps/
$ bin/hadoop fs -put oozie-apps/map-reduce /user/atguigu/oozie-apps
4)执行任务
[xjl@hadoop102 oozie-4.0.0-cdh5.3.6]$ bin/oozie job -oozie http://hadoop102:11000/oozie -config oozie-apps/shell/job.properties -run
Oozie调度MapReduce任务
1)找到一个可以运行的mapreduce任务的jar包(可以用官方的,也可以是自己写的)
2)拷贝官方模板到oozie-apps
[xjl@hadoop102 oozie-4.0.0-cdh5.3.6]$ cp -r /opt/module/cdh/ oozie-4.0.0-cdh5.3.6/examples/apps/map-reduce/ oozie-apps/
3) 测试一下wordcount在yarn中的运行
[xjl@hadoop102 oozie-4.0.0-cdh5.3.6]$ /opt/module/cdh/hadoop-2.5.0-cdh5.3.6/bin/yarn jar /opt/module/cdh/hadoop-2.5.0-cdh5.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar wordcount /input/ /output/
4) 配置map-reduce任务的job.properties以及workflow.xml
job.properties
nameNode=hdfs://hadoop102:8020
jobTracker=hadoop103:8032
queueName=default
examplesRoot=oozie-apps
#hdfs://hadoop102:8020/user/admin/oozie-apps/map-reduce/workflow.xml
oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/map-reduce/workflow.xml
outputDir=map-reduce
workflow.xml
<workflow-app xmlns="uri:oozie:workflow:0.2" name="map-reduce-wf">
<start to="mr-node"/>
<action name="mr-node">
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/output/"/>
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
<!-- 配置调度MR任务时,使用新的API -->
<property>
<name>mapred.mapper.new-api</name>
<value>true</value>
</property>
<property>
<name>mapred.reducer.new-api</name>
<value>true</value>
</property>
<!-- 指定Job Key输出类型 -->
<property>
<name>mapreduce.job.output.key.class</name>
<value>org.apache.hadoop.io.Text</value>
</property>
<!-- 指定Job Value输出类型 -->
<property>
<name>mapreduce.job.output.value.class</name>
<value>org.apache.hadoop.io.IntWritable</value>
</property>
<!-- 指定输入路径 -->
<property>
<name>mapred.input.dir</name>
<value>/input/</value>
</property>
<!-- 指定输出路径 -->
<property>
<name>mapred.output.dir</name>
<value>/output/</value>
</property>
<!-- 指定Map类 -->
<property>
<name>mapreduce.job.map.class</name>
<value>org.apache.hadoop.examples.WordCount$TokenizerMapper</value>
</property>
<!-- 指定Reduce类 -->
<property>
<name>mapreduce.job.reduce.class</name>
<value>org.apache.hadoop.examples.WordCount$IntSumReducer</value>
</property>
<property>
<name>mapred.map.tasks</name>
<value>1</value>
</property>
</configuration>
</map-reduce>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
5)拷贝待执行的jar包到map-reduce的lib目录下
[xjl@hadoop102 oozie-4.0.0-cdh5.3.6]$ cp -a /opt /module/cdh/hadoop-2.5.0-cdh5.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar oozie-apps/map-reduce/lib
6)上传配置好的app文件夹到HDFS
[xjl@hadoop102 oozie-4.0.0-cdh5.3.6]$ /opt/module/cdh/hadoop-2.5.0-cdh5.3.6/bin/hdfs dfs -put oozie-apps/map-reduce/ /user/admin/oozie-apps
7)执行任务
[xjl@hadoop102 oozie-4.0.0-cdh5.3.6]$ bin/oozie job -oozie http://hadoop102:11000/oozie -config oozie-apps/map-reduce/job.properties -run
Oozie定时任务/循环任务
分步实现:
1)配置Linux时区以及时间服务器
2)检查系统当前时区:
# date -R
注意:如果显示的时区不是+0800,删除localtime文件夹后,再关联一个正确时区的链接过去,命令如下:
# rm -rf /etc/localtime
# ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
同步时间:
# ntpdate pool.ntp.org
修改NTP配置文件:
# vi /etc/ntp.conf
去掉下面这行前面的# ,并把网段修改成自己的网段:
restrict 192.168.122.0 mask 255.255.255.0 nomodify notrap
注释掉以下几行:
#server 0.centos.pool.ntp.org
#server 1.centos.pool.ntp.org
#server 2.centos.pool.ntp.org
把下面两行前面的#号去掉,如果没有这两行内容,需要手动添加
server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 10
重启NTP服务:
# systemctl start ntpd.service,
注意,如果是centOS7以下的版本,使用命令:service ntpd start
# systemctl enable ntpd.service,
注意,如果是centOS7以下的版本,使用命令:chkconfig ntpd on
集群其他节点去同步这台时间服务器时间:
首先需要关闭这两台计算机的ntp服务
# systemctl stop ntpd.service,
centOS7以下,则:service ntpd stop
# systemctl disable ntpd.service,
centOS7以下,则:chkconfig ntpd off
# systemctl status ntpd,查看ntp服务状态
# pgrep ntpd,查看ntp服务进程id
同步第一台服务器linux01的时间:
# ntpdate hadoop102
使用root用户制定计划任务,周期性同步时间:
# crontab -e
*/10 * * * * /usr/sbin/ntpdate hadoop102
重启定时任务:
# systemctl restart crond.service,
centOS7以下使用:service crond restart,
其他台机器的配置同理。
3)配置oozie-site.xml文件
属性:oozie.processing.timezone
属性值:GMT+0800
解释:修改时区为东八区区时
注:该属性去oozie-default.xml中找到即可
4)修改js框架中的关于时间设置的代码
$ vi /opt/module/cdh/oozie-4.0.0-cdh5.3.6/oozie-server/webapps/oozie/oozie-console.js
修改如下:
function getTimeZone() {
Ext.state.Manager.setProvider(new Ext.state.CookieProvider());
return Ext.state.Manager.get("TimezoneId","GMT+0800");
}
5)重启oozie服务,并重启浏览器(一定要注意清除缓存)
[xjl@hadoop102 oozie-4.0.0-cdh5.3.6]$ bin/oozied.sh stop
[xjl@hadoop102 oozie-4.0.0-cdh5.3.6]$ bin/oozied.sh start
6)拷贝官方模板配置定时任务
$ cp -r examples/apps/cron/ oozie-apps/
7)修改模板job.properties和coordinator.xml以及workflow.xml
job.properties
nameNode=hdfs://hadoop102:8020
jobTracker=hadoop103:8032
queueName=default
examplesRoot=oozie-apps
oozie.coord.application.path=${nameNode}/user/${user.name}/${examplesRoot}/cron
#start:必须设置为未来时间,否则任务失败
start=2017-07-29T17:00+0800
end=2017-07-30T17:00+0800
workflowAppUri=${nameNode}/user/${user.name}/${examplesRoot}/cron
EXEC3=p3.sh
coordinator.xml
<coordinator-app name="cron-coord" frequency="${coord:minutes(5)}" start="${start}" end="${end}" timezone="GMT+0800" xmlns="uri:oozie:coordinator:0.2">
<action>
<workflow>
<app-path>${workflowAppUri}</app-path>
<configuration>
<property>
<name>jobTracker</name>
<value>${jobTracker}</value>
</property>
<property>
<name>nameNode</name>
<value>${nameNode}</value>
</property>
<property>
<name>queueName</name>
<value>${queueName}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>
workflow.xml
<workflow-app xmlns="uri:oozie:workflow:0.5" name="one-op-wf">
<start to="p3-shell-node"/>
<action name="p3-shell-node">
<shell xmlns="uri:oozie:shell-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>${EXEC3}</exec>
<file>/user/atguigu/oozie-apps/cron/${EXEC3}#${EXEC3}</file>
<!-- <argument>my_output=Hello Oozie</argument>-->
<capture-output/>
</shell>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<kill name="fail-output">
<message>Incorrect output, expected [Hello Oozie] but was [${wf:actionData('shell-node')['my_output']}]</message>
</kill>
<end name="end"/>
</workflow-app>
8)上传配置
[xjl@hadoop102 oozie-4.0.0-cdh5.3.6]$ /opt/module/cdh/hadoop-2.5.0-cdh5.3.6/bin/hdfs dfs -put oozie-apps/cron/ /user/admin/oozie-apps
9)启动任务
[xjl@hadoop102 oozie-4.0.0-cdh5.3.6]$ bin/oozie job -oozie http://hadoop102:11000/oozie -config oozie-apps/cron/job.properties -run
注意:Oozie允许的最小执行任务的频率是5分钟。
- 发表于 2023-08-11 19:14
- 阅读 ( 450 )
