进击大数据系列(四):Hadoop 架构基石分布式文件系统 HDFS
前面介绍了 Hadoop 基本概念与生态、安装(HDFS+YARN+MapReduce)实战操作、常用命令等相关的知识点,今天我将详细的为大家介绍 大数据 Hadoop 架构基石分布式文件系统 HDFS 相关知识。
HDFS 产出背景及定义
HDFS 产生背景
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。
HDFS 只是分布式文件管理系统中的一种。
HDFS 定义
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS 的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变。
HDFS 优缺点
优点
高容错性
数据自动保存多个副本。它通过增加副本的形式,提高容错性。
某一个副本丢失以后,它可以自动恢复。
适合处理大数据- 数据规模:能够处理数据规模达到GB、TB、甚至PB级别的数据;
- 文件规模:能够处理百万规模以上的文件数量,数量相当之大。
缺点
不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。无法高效的对大量小文件进行存储。- 存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息。这样是不可取的,因为NameNode的内存总是有限的;
- 小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
- 一个文件只能有一个写,不允许多个线程同时写;
- 仅支持数据append(追加),不支持文件的随机修改。
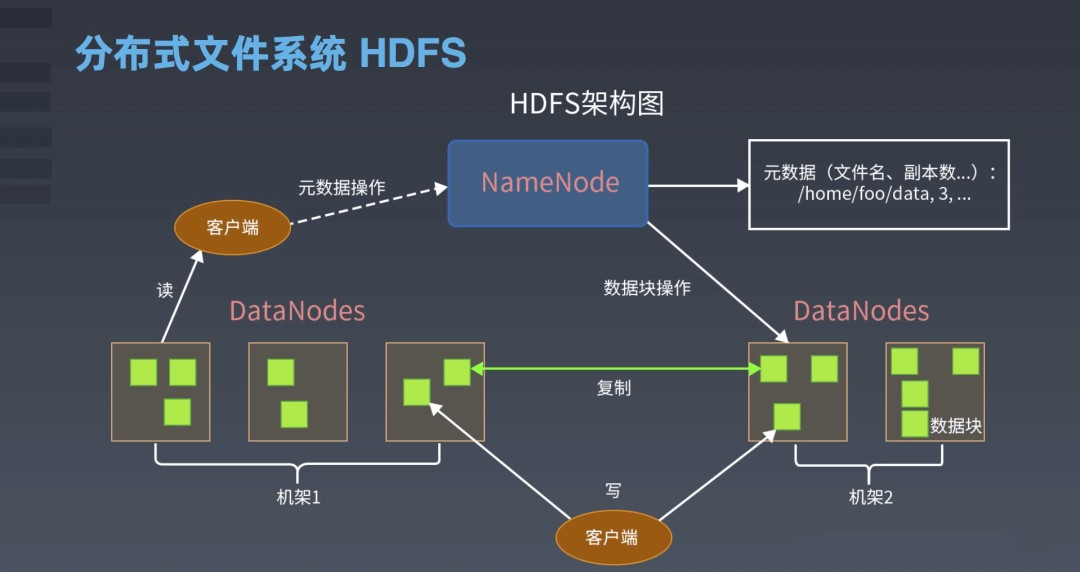
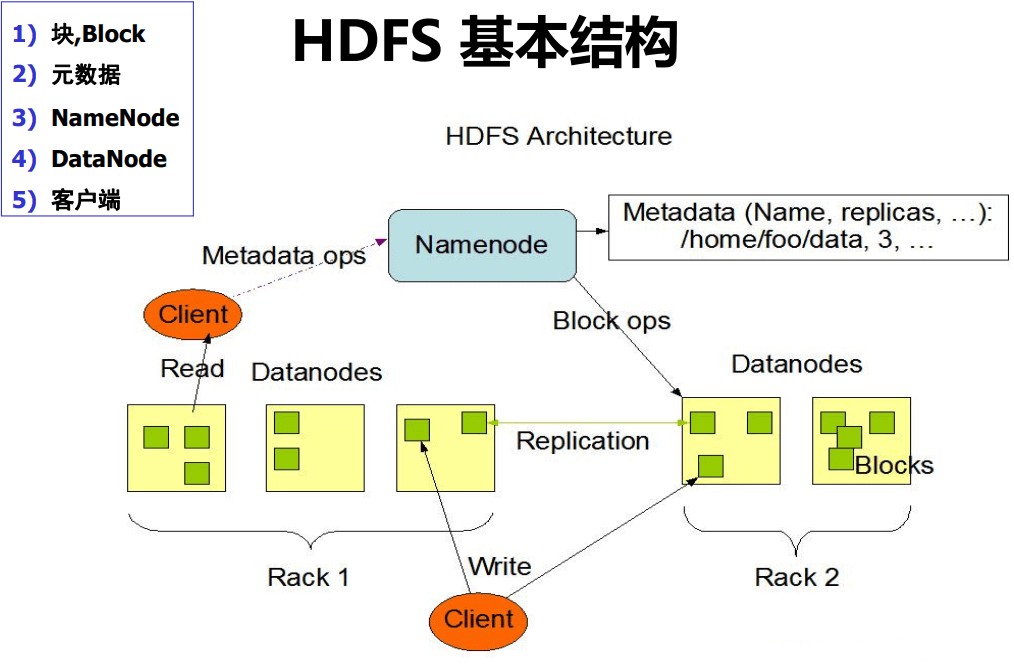
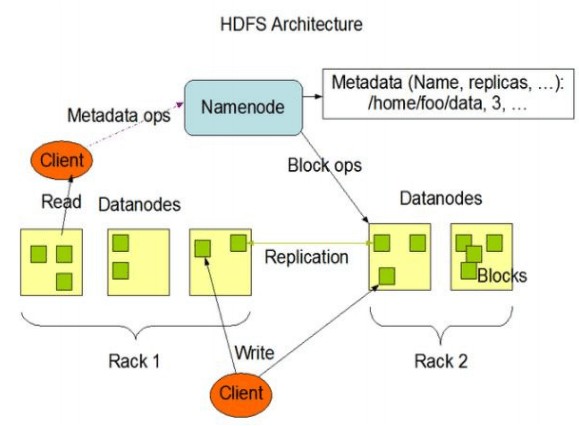
HDFS 组成架构
NameNode(nn)
就是Master,它是一个主管、管理者。
- (1)管理HDFS的名称空间;
- (2)配置副本策略;
- (3)管理数据块(Block)映射信息;
- (4)处理客户端读写请求。
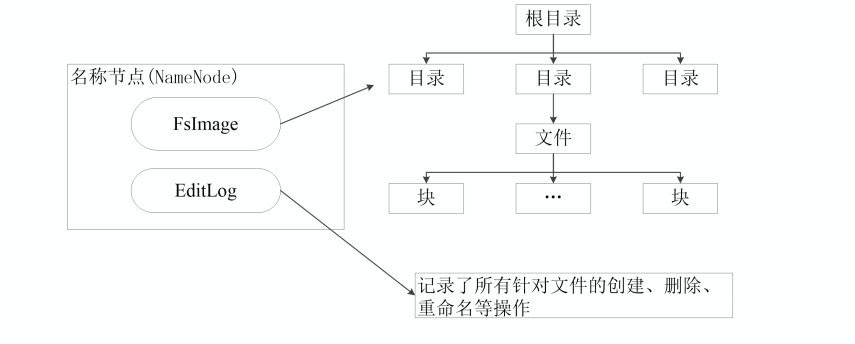
- NameNode负责管理分布式文件系统的Namespace命名空间,保存了两个核心数据结构:FsImage和EditLog
- FsImage用于维护文件系统树以及文件树中所有的文件和文件夹的元数据;
- 操作日志文件EditLog中记录了所有针对文件的创建、删除、重命名等操作;
- 在名称节点启动的时候,它会将FsImage文件中的内容加载到内存中,之后再执行EditLog文件中的各项操作,使得内存中的元数据和实际的同步,存在内存中的元数据支持客户端的读操作。
- 一旦在内存中成功建立文件系统元数据的映射,则创建一个新的FsImage文件和一个空的EditLog文件
- 在名称节点运行期间,HDFS的所有更新操作都是直接写到EditLog中,久而久之, EditLog文件将会变得很大。当EditLog文件非常大的时候,会导致名称节点启动操作非常慢,而在这段时间内HDFS系统处于安全模式,一直无法对外提供写操作,影响了用户的使用。
DataNode
就是Slave。NameNode下达命令,DataNode执行实际的操作。
- (1)存储实际的数据块;
- (2)执行数据块的读/写操作。
Client
就是客户端
- (1)文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传;
- (2)与NameNode交互,获取文件的位置信息;
- (3)与DataNode交互,读取或者写入数据;
- (4)Client提供一些命令来管理HDFS,比如NameNode格式化;
- (5)Client可以通过一些命令来访问HDFS,比如对HDFS增删查改操作;
Secondary NameNode
并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
- (1)辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode ;
- (2)在紧急情况下,可辅助恢复NameNode。


HDFS 文件块大小
HDFS中的文件在物理上是分块存储(Block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在Hadoop2.x/3.x版本中是128M,1.x版本中是64M。
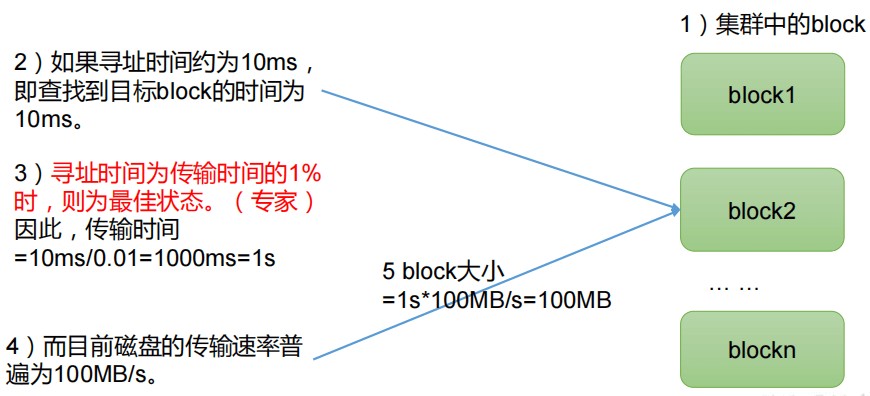
思考:为什么块的大小不能设置太小,也不能设置太大?
- HDFS的块设置太小,会增加寻址时间,程序一直在找块的开始位置;
- 如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。导致程序在处理这块数据时,会非常慢。
总结:HDFS 块的大小设置主要取决于磁盘传输速率。
HDFS 读写操作详解
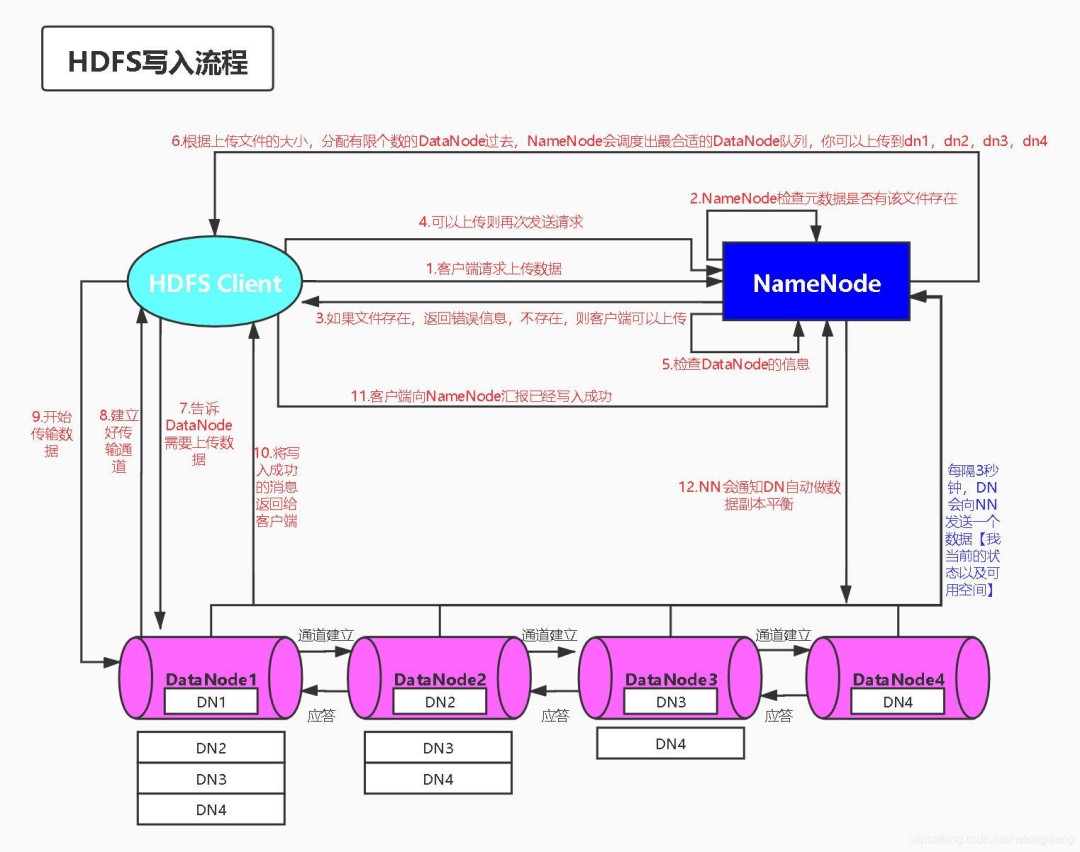
HDFS 写操作
- 客户端写一个文件并不是直接写到HDFS上;
- HDFS客户端接收用户数据,并把内容缓存在本地;
- 当本地缓存收集足够一个HDFS块大小的时候,客户端同NameNode通讯注册一个新的块;
- 注册块成功后,NameNode给客户端返回一个DataNode的列表; – 列表中是该块需要存放的位置,包括冗余备份
- 客户端向列表中的第一个DataNode写入块; 当完成时,第一个DataNode 向列表中的下个DataNode发送写操作,并把数据已收到的确认信息给客户端,同时发送确认信息给NameNode 之后的DataNode重复之上的步骤。当列表中所有DataNode都接收到数据并且由最后一个DataNode校验数据正确性完成后,返回确认信息给客户端
- 收到所有DN的确认信息后,客户端删除本地缓存;
- 客户端继续发送下一个块,重复以上步骤;
- 当所有数据发送完成后,写操作完成。
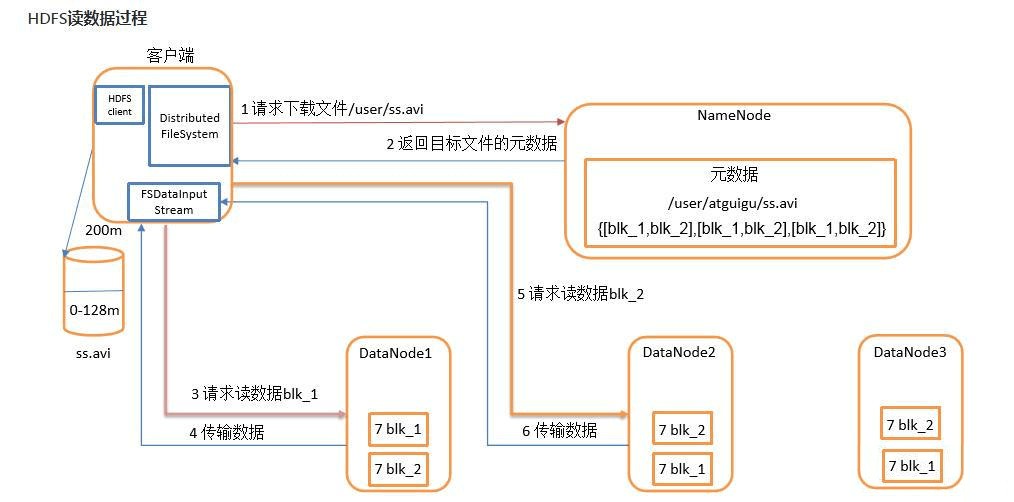
HDFS 读操作
- 客户端与NameNode通讯获取文件的块位置信息,其中包括了块的所有冗余备份的位置信息:DataNode的列表;
- 客户端获取文件位置信息后直接同有文件块的DataNode通讯,读取文件;
- 如果第一个DataNode无法连接,客户端将自动联系下一个DataNode;
- 如果块数据的校验值出错,则客户端需要向NameNode报告,并自动联系下一个DataNode。
HDFS追加写操作
- 客户端与NameNode通讯,获得文件的写保护锁及文件最后一个块的位置(DataNode列表)
- 客户端挑选一个DataNode作为主写入节点,并对其余节点上的该数据块加锁
- 开始写入数据。与普通写入流程类似,依次更新各个DataNode上的数据。更新时间戳和校验和
- 最后一个块写满,并且所有备份块都完成写入后,向NameNode申请下一个数据块。
HDFS 搭建(3.0.0 单机版)
根据官网的说明,选择的是最新的文抵挡版本hadoop-3.3.0.tar.gz。
免密登录
举例A机器要免密登录B机器。则首先需要把A机器的公钥id_rsa.pub 传送给B机器,B机器将A机器的公钥内容放置本机的文件authorized_keys中。然后就可以在A机器上使用命令 “ssh 机器名”进行访问了。
涉及到的命令如下:
#hostname用于显示或者设置该主机的名字
[root@cuiyaonan2000 soft] hostname 机器名字
#生成本机的公钥与私钥
[root@cuiyaonan2000 soft] ssh-keygen -t rsa
#转移到公钥私钥目录
[root@cuiyaonan2000 soft] cd ~/.ssh/
#生成authorized_keys 文件用于存储公钥内容
[root@cuiyaonan2000 soft] touch authorized_keys
#修改权限
[root@cuiyaonan2000 soft] chmod 600 authorized_keys
#将其它主机的公钥内容 追加到authorized_keys 中
[root@cuiyaonan2000 soft] cat id_rsa.pub >> authorized_keys提前的准备
根据官网:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html 的要求我们可以看到起详细的需求。
如下是为Hadoop配置环境变量,jdk就不包含在内了。
#下载hadoop,建议使用迅雷下载,比较大有500m左右
[root@cuiyaonan2000 soft] wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/hadoop-3.3.0.tar.gz
#解压hadoop
[root@cuiyaonan2000 soft] tar -zxvf hadoop-3.3.0.tar.gz
#编辑profile文件
[root@cuiyaonan2000 soft] vi /etc/profile
#增加如下的内容
export HADOOP_HOME=/soft/hadoop/hadoop-3.3.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-DJava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
[root@cuiyaonan2000 soft] source /etc/profile
#查看hadoop 是否配置成功
[root@cuiyaonan2000 soft] hadoop version修改配置文件(这些配置文件全都在etc/hadoop 中)
hadoop-env.sh进入目录:hadoop-3.3.0/etc/hadoop 修改 hadoop-env.sh 文件 ,增加内容 export JAVA_HOME=/soft/jdk/jdk1.8.0_271。
core-site.xml进入目录:hadoop-3.3.0/etc/hadoop 修改 core-site.xml 文件,并在<configuration>中增加如下的内容。
如下的hadoop.tmp.dir的配置要注意。
<!--
hdfs-site.xml
1.配置默认采用的文件系统。
(由于存储层和运算层松耦合,要为它们指定使用hadoop原生的分布式文件系统hdfs。
value填入的是uri,参数是 分布式集群中主节点的地址 : 指定端口号)
2.其中localhost可以换成机器名称
-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000/</value>
</property>
<!--
配置hadoop的公共目录
(指定hadoop进程运行中产生的数据存放的工作目录,NameNode、DataNode等就在本地工作目录下建子目录存放数据。但事实上在生产系统里,NameNode、DataNode等进程都应单独配置目录,而且配置的应该是磁盘挂载点,以方便挂载更多的磁盘扩展容量)
-->
<property>
<name>hadoop.tmp.dir</name>
<value>/soft/data_hadoop</value>
</property>##设置文件拆分成blocks副本备份的数量
mapred-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
#设置NameNode数据存储目录
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/soft/namenode</value>
</property>
#设置DataNode数据存储目录
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/soft/datanode</value>
</property>
#这里在不加的话 hdfs的网站访问不了
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
#这里可以考虑取消写入权限限制否则只能通过命令hadoop fs -chmod 777 /soft/hadoop/warehouse/student 来增加针对某个目录的写权限
<property>
<name>dfs.permissions</name>
<value>false</value>
</property><!--
yarn-site.xml
指定MapReduce程序应该放在哪个资源调度集群上运行。若不指定为yarn,那么MapReduce程序就只会在本地运行而非在整个集群中运行。
-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property><!-- 1.指定yarn集群中的老大(就是本机) -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<!-- 2.配置yarn集群中的重节点,指定map产生的中间结果传递给reduce采用的机制是shuffle
-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 这个就是配置yarn的管理界面 -->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>mzdapip:8088</value>
<description>配置外网只需要替换外网ip为真实ip,否则默认为 localhost:8088</description>
</property>启动Hadoop(命令都在sbin文件夹下)
格式化HDFS中的数据(从命令上看是清除namenode上存储的数据)必须在启动的时候先执行namenode 的格式化。否则会有问题。
[root@cuiyaonan2000 soft] hadoop namenode -format
启动hdfs和yarnstart-dfs.sh
#启动dfs,对应的关闭是stop-dfs.sh启动后可以访问管理界面:http://10.1.80.187:50070/dfshealth.html#tab-overview
start-yarn.sh
#启动yarn,对应的关闭是stop-yarn.sh启动后可以访问管理界面:http://10.1.80.187:8088/cluster
yarn-daemon.sh start resourcemanager
#启动yarn管理节点
yarn-daemon.sh start nodemanager
#启动yarn运算节点
start-all.sh
#一键全部启动如果遇到如下的问题
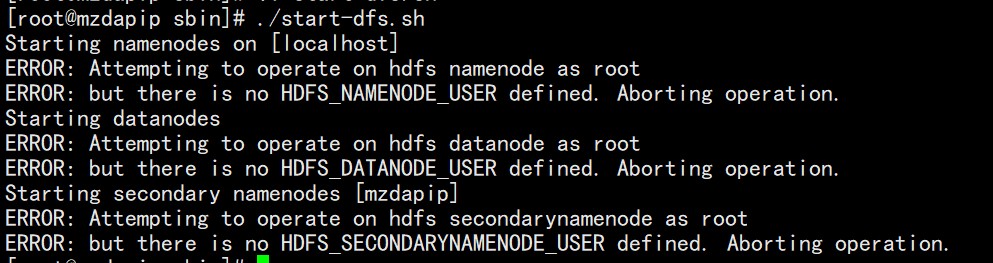
对于start-dfs.sh和stop-dfs.sh文件,添加下列参数:
HDFS_DATANODE_USER=rootHADOOP_SECURE_DN_USER=hdfsHDFS_NAMENODE_USER=rootHDFS_SECONDARYNAMENODE_USER=root
对于start-yarn.sh和stop-yarn.sh文件,添加下列参数:
#!/usr/bin/env bashYARN_RESOURCEMANAGER_USER=rootHADOOP_SECURE_DN_USER=yarnYARN_NODEMANAGER_USER=root
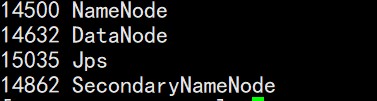
成功启动dfs的进程截图如下所示:
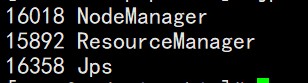
成功启动yarn的进程截图如下所示:
HDFS 分布式集群(3.0.0 搭建)
修改配置文件(这些配置文件全都在etc/hadoop 中)
core-site.xml
<!--
1.配置默认采用的文件系统。
(由于存储层和运算层松耦合,要为它们指定使用hadoop原生的分布式文件系统hdfs。
value填入的是uri,参数是 分布式集群中主节点的地址 : 指定端口号)
2.其中localhost可以换成机器名称
-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000/</value>
</property>
<!--
配置hadoop的公共目录
(指定hadoop进程运行中产生的数据存放的工作目录,NameNode、DataNode等就在本地工作目录下建子目录存放数据。但事实上在生产系统里,NameNode、DataNode等进程都应单独配置目录,而且配置的应该是磁盘挂载点,以方便挂载更多的磁盘扩展容量)
-->
<property>
<name>hadoop.tmp.dir</name>
<value>/soft/data_hadoop</value>
</property>
hdfs-site.xm
这里就是将原来的内容进行增删,单机的话是同时存在 DataNode 和 NameNode 的.现在是多机。所以现在2者并不需要并存,那是否预示着如果存在dfs.datanode.data.dir就表示有datanode,没有就不会创建datanode????
<property>
<!-- 主节点地址 -->
<name>dfs.namenode.http-address</name>
<value>mzdapip:50070</value>
</property>
##设置文件拆分成blocks副本备份的数量
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
#设置NameNode数据存储目录
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/soft/namenode</value>
</property>
#设置DataNode数据存储目录
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/soft/datanode</value>
</property>
#这里在不加的话 hdfs的网站访问不了
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
mapred-site.xml----注意这里增加主机的指向
<!--
指定MapReduce程序应该放在哪个资源调度集群上运行。若不指定为yarn,那么MapReduce程序就只会在本地运行而非在整个集群中运行。
-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>mzdapip:54311</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>mzdapip:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>mzdapip:19888</value>
</property>
yarn-site.xml
#指定yarn的ResourceManager管理界面的地址,不配的话,Active Node始终为0
#这里必须添加
<property>
<name>yarn.resourcemanager.hostname</name>
<value>mzdapip</value>
</property>
<!-- 2.配置yarn集群中的重节点,指定map产生的中间结果传递给reduce采用的机制是shuffle
-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 这个就是配置yarn的管理界面 -->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>mzdapip:8088</value>
<description>配置外网只需要替换外网ip为真实ip,否则默认为 localhost:8088</description>
</property>
workers
从主节点上启动,会去启动这里面包含的子节点。这里增加工作节点的ip或者机器名,如:
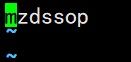
并且主节点上只会启动如下的服务:
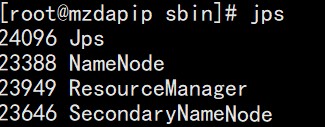
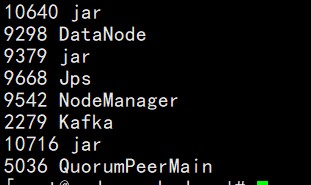
子节点上启动的服务如下所示:只有DataNode,NodeManager
启动
无论有多少台服务器,他们的hadoop存放的绝对路径必须一致,否则不能从主节点上去启动其它的服务。
HDFS 命令行
cat
- 用途:显示一个或多个文件内容到控制台
- 使用方法:hadoop fs -cat URI [URI …]
- 例子:
− hadoop fs -cat hdfs://host1:port1/file1
hdfs://host2:port2/file2
− hadoop fs -cat file:///file3
/user/hadoop/file4
put/copyFromLocal
- 用途:将本地一个或多个文件导入HDFS。以上两个命令唯一的不同时copyFromLocal的源只能是本地文件,而put可以读取stdin的数据
- 使用方法:hadoop fs -put/copyFromLocal UR
- 例子:
− hadoop fs -put localfile.txt /user/hadoop/hadoopfile.txt
− hadoop fs -put localfile1 localfile2 /user/hadoop/hadoopdir
− hadoop fs -put localfile hdfs://host:port/hadoop
get/copyToLocal
- 用途:将HDFS中的一个或多个文件导出到本地文件系统
- 使用方法: hadoop fs -get/copyToLocal [-ignorecrc] [-crc] URI < localsrc>
- 例子:
− hadoop fs -get /user/hadoop/hadoopfile localfile
− hadoop fs -get hdfs://host:port/user/hadoop/file localfile
ls
- 用途:列出文件夹目录信息,lsr 递归显示文件
- 使用方法: hadoop fs -ls/lsr -h UR
fsck
- 用途:检查dfs的文件的健康状况; 只能运行在 master 上
- 使用方法:hadoop fsck [GENERIC_OPTIONS] [- move | -delete | -openforwrite] [-files [-blocks [-locations | -racks]]
- 发表于 2023-07-25 15:22
- 阅读 ( 465 )
