进击大数据系列(二):Hadoop 安装(HDFS+YARN+MapReduce)实战操作
前面介绍了 Hadoop 基本概念与生态 相关的知识点,今天我将详细的为大家介绍 大数据 Hadoop 安装(HDFS+YARN+MapReduce)实战操作
安装 Hadoop(HDFS+YARN)
环境准备
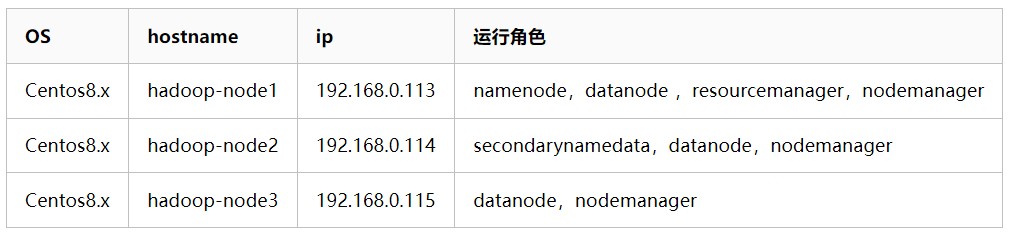
这里准备三台VM虚拟机
下载最新的Hadoop安装包
下载地址:https://dlcdn.apache.org/hadoop/common/
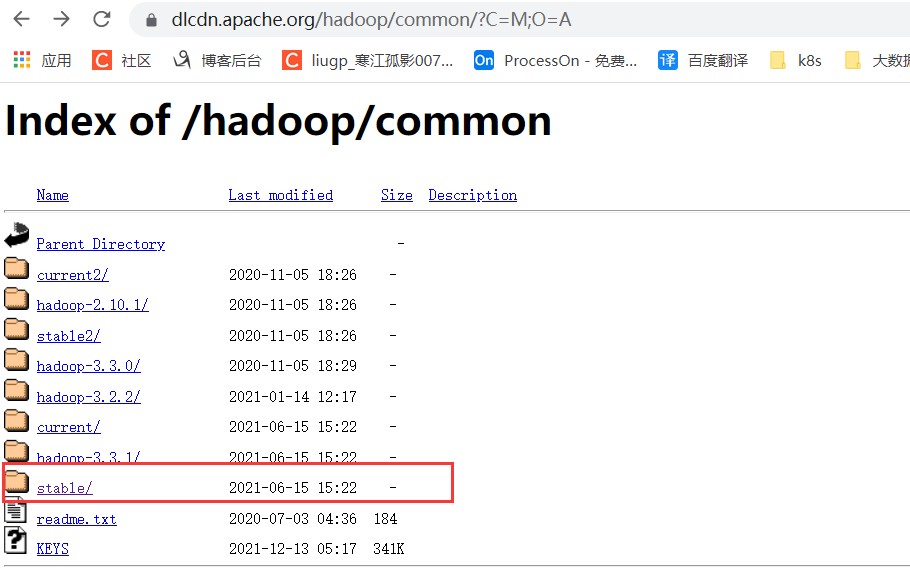
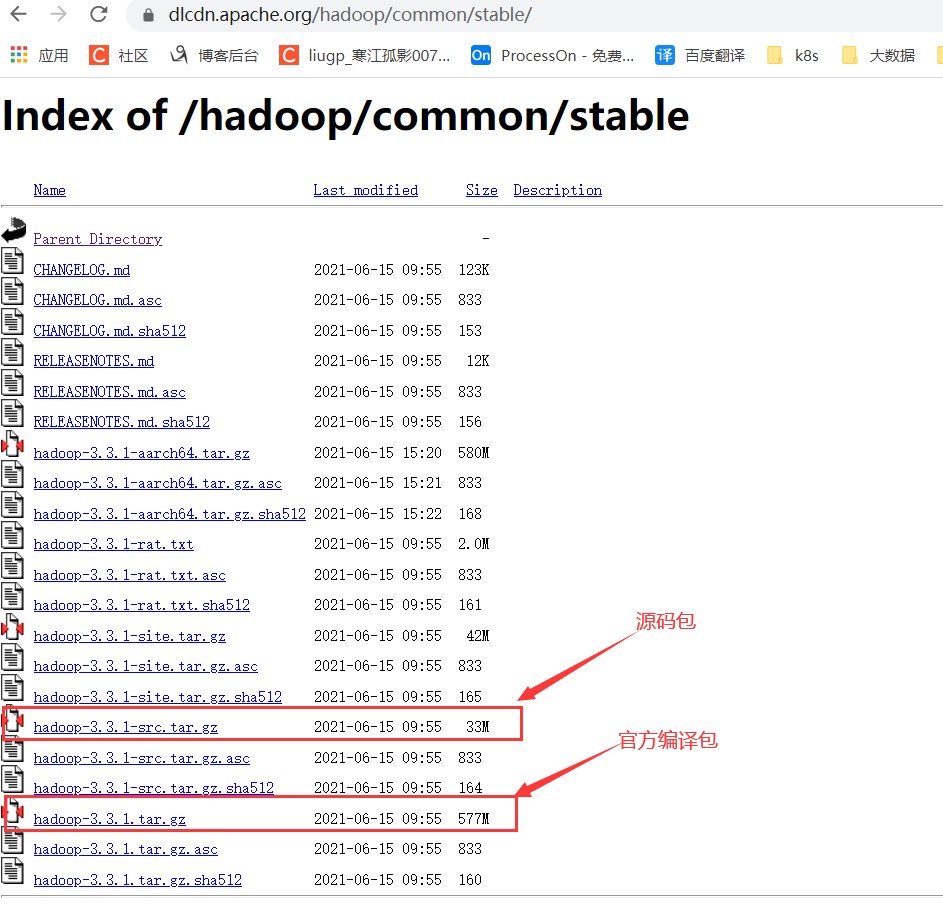
这里下载源码包安装,默认的编译好的文件不支持snappy压缩,因此我们需要自己重新编译。
$ mkdir -p /opt/bigdata/hadoop && cd /opt/bigdata/hadoop
$ wget https://dlcdn.apache.org/hadoop/common/stable/hadoop-3.3.1-src.tar.gz
# 解压
$ tar -zvxf hadoop-3.3.1-src.tar.gz
为什么需要重新编译Hadoop源码?
匹配不同操作系统本地库环境,Hadoop某些操作比如压缩,IO需要调用系统本地库(_.so|_.dll)。
重构源码
源码包目录下有个 BUILDING.txt,因为我这里的操作系统是Centos8,所以选择Centos8的操作步骤,小伙伴们找到自己对应系统的操作步骤执行即可。
$ grep -n -A40 'Building on CentOS 8' BUILDING.txt
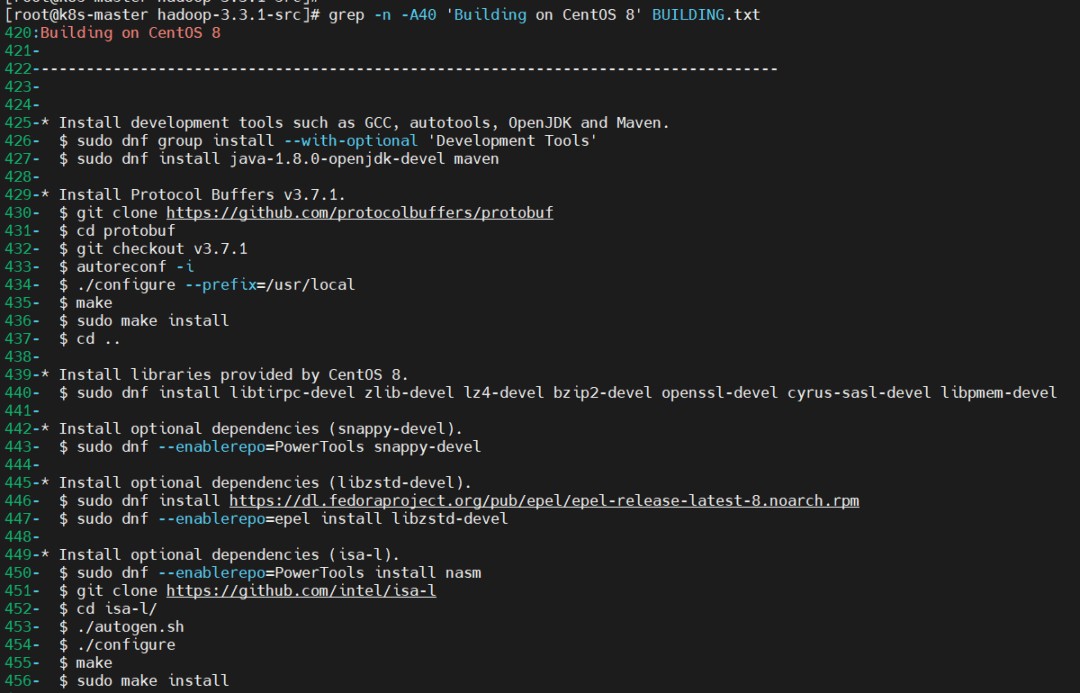
Building on CentOS 8
-----------------------------------------------------------------------
* Install development tools such as GCC, autotools, OpenJDK and Maven.
$ sudo dnf group install --with-optional 'Development Tools'
$ sudo dnf install java-1.8.0-openjdk-devel maven
* Install Protocol Buffers v3.7.1.
$ git clone https://github.com/protocolbuffers/protobuf
$ cd protobuf
$ git checkout v3.7.1
$ autoreconf -i
$ ./configure --prefix=/usr/local
$ make
$ sudo make install
$ cd ..
* Install libraries provided by CentOS 8.
$ sudo dnf install libtirpc-devel zlib-devel lz4-devel bzip2-devel openssl-devel cyrus-sasl-devel libpmem-devel
* Install optional dependencies (snappy-devel).
$ sudo dnf --enablerepo=PowerTools snappy-devel
* Install optional dependencies (libzstd-devel).
$ sudo dnf install https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm
$ sudo dnf --enablerepo=epel install libzstd-devel
* Install optional dependencies (isa-l).
$ sudo dnf --enablerepo=PowerTools install nasm
$ git clone https://github.com/intel/isa-l
$ cd isa-l/
$ ./autogen.sh
$ ./configure
$ make
$ sudo make install
-----------------------------------------------------------------------
将进入Hadoop源码路径,执行maven命令进行Hadoop编译。
$ cd /opt/bigdata/hadoop/hadoop-3.3.1-src
# 编译
$ mvn package -Pdist,native,docs -DskipTests -Dtar
【问题】Failed to execute goal org.apache.maven.plugins:maven-enforcer-plugin:3.0.0-M1:enforce
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 19:49 min
[INFO] Finished at: 2021-12-14T09:36:29+08:00
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-enforcer-plugin:3.0.0-M1:enforce (enforce-banned-dependencies) on project hadoop-client-check-test-invariants: Some Enforcer rules have failed. Look above for specific messages explaining why the rule failed. -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn -rf :hadoop-client-check-test-invariants
【解决】
- 方案一:跳过enforcer的强制约束,在构建的命令加上跳过的指令,如:**-Denforcer.skip=true**
- 方案二:设置规则校验失败不影响构建流程,在构建的命令上加指令,如: -Denforcer.fail=false
具体原因目前还不明确,先使用上面两个方案中的方案一跳过,有兴趣的小伙伴,可以打开DEBUG模式(-X)查看具体报错。
$ mvn package -Pdist,native,docs,src -DskipTests -Dtar -Denforcer.skip=true
所以编译命令
# 当然还有其它选项
$ grep -n -A1 '$ mvn package' BUILDING.txt
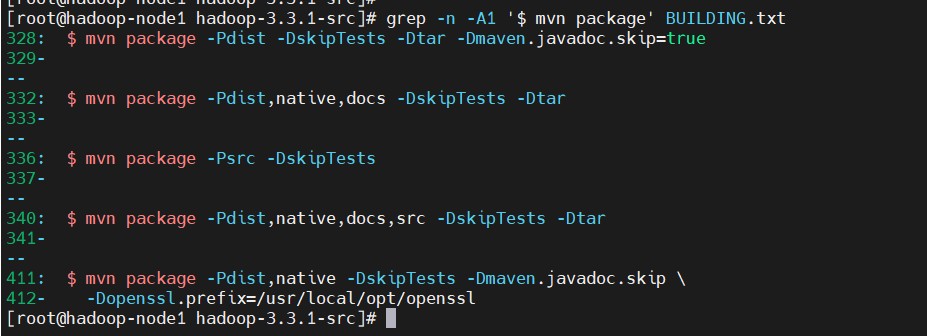
$ mvn package -Pdist -DskipTests -Dtar -Dmaven.javadoc.skip=true
$ mvn package -Pdist,native,docs -DskipTests -Dtar
$ mvn package -Psrc -DskipTests
$ mvn package -Pdist,native,docs,src -DskipTests -Dtar
$ mvn package -Pdist,native -DskipTests -Dmaven.javadoc.skip \
-Dopenssl.prefix=/usr/local/opt/openssl
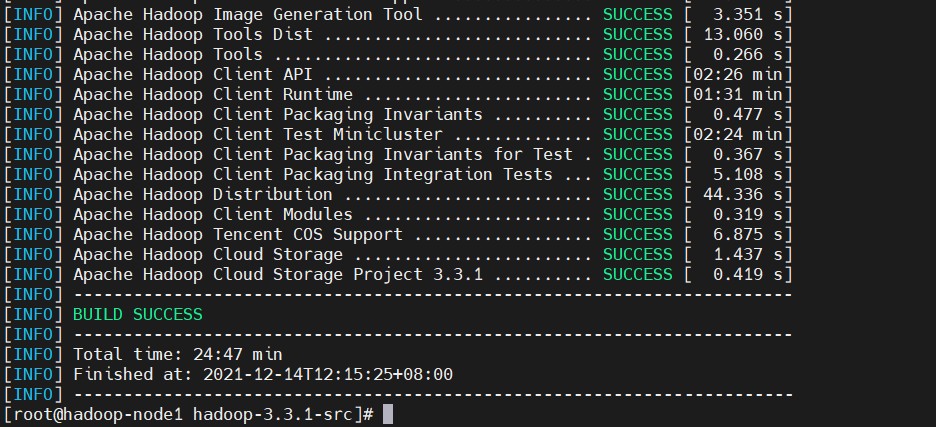
至此~Hadoop源码编译完成,
编译后的文件位于源码路径下 hadoop-dist/target/
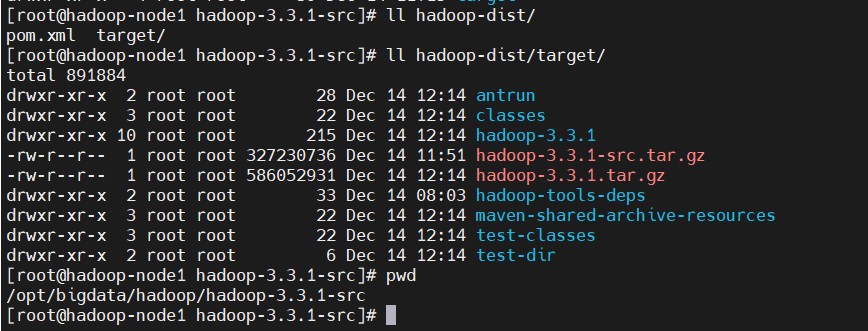
将编译好的二进制包copy出来
$ cp hadoop-dist/target/hadoop-3.3.1.tar.gz /opt/bigdata/hadoop/
$ cd /opt/bigdata/hadoop/
$ ll
进行服务器及Hadoop的初始化配置
修改主机名# 192.168.0.113机器上执行修改主机名和IP的映射关系(所有节点都执行)
$ hostnamectl set-hostname hadoop-node1
# 192.168.0.114机器上执行
$ hostnamectl set-hostname hadoop-node2
# 192.168.0.115机器上执行
$ hostnamectl set-hostname hadoop-node3
$ echo "192.168.0.113 hadoop-node1" >> /etc/hosts关闭防火墙和selinux(所有节点都执行)
$ echo "192.168.0.114 hadoop-node2" >> /etc/hosts
$ echo "192.168.0.115 hadoop-node3" >> /etc/hosts
$ systemctl stop firewalld时间同步(所有节点都执行)
$ systemctl disable firewalld
# 临时关闭(不用重启机器):
$ setenforce 0 ##设置SELinux 成为permissive模式
# 永久关闭修改/etc/selinux/config 文件
将SELINUX=enforcing改为SELINUX=disabled
$ dnf install chrony -y
$ systemctl start chronyd
$ systemctl enable chronyd
/etc/chrony.conf配置文件内容
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
#pool 2.centos.pool.ntp.org iburst (这一行注释掉,增加以下两行)
server ntp.aliyun.com iburst
server cn.ntp.org.cn iburst
重新加载配置并测试
$ systemctl restart chronyd.service配置ssh免密(在hadoop-node1上执行)
$ chronyc sources -v
# 1、在hadoop-node1上执行如下命令生成公私密钥:
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_dsa
# 2、然后将master公钥id_dsa复制到hadoop-node1|hadoop-node2|hadoop-node3进行公钥认证。
$ ssh-copy-id -i /root/.ssh/id_dsa.pub hadoop-node1
$ ssh-copy-id -i /root/.ssh/id_dsa.pub hadoop-node2
$ ssh-copy-id -i /root/.ssh/id_dsa.pub hadoop-node3
$ ssh hadoop-node1
$ exit
$ ssh hadoop-node2
$ exit
$ ssh hadoop-node3
$ exit
# 软件安装路径安装JDK(所有节点都执行)
$ mkdir -p /opt/bigdata/hadoop/server
# 数据存储路径
$ mkdir -p /opt/bigdata/hadoop/data
# 安装包存放路径
$ mkdir -p /opt/bigdata/hadoop/software
官网下载:https://www.oracle.com/java/technologies/downloads/
$ cd /opt/bigdata/hadoop/software
$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/bigdata/hadoop/server/
# 在文件加入环境变量/etc/profile
export JAVA_HOME=/opt/bigdata/hadoop/server/jdk1.8.0_212
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
# source加载
$ source /etc/profile
# 查看jdk版本
$ java -version
开始安装 Hadoop
解压上面我编译好的安装包$ cd /opt/bigdata/hadoop/software
$ tar -zxvf hadoop-3.3.1.tar.gz -C /opt/bigdata/hadoop/server/
$ cd /opt/bigdata/hadoop/server/
$ cd hadoop-3.3.1/
$ ls -lh
bin #hadoop最基本的管理脚本和使用脚本的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用hadoop修改配置文件
etc #hadoop配置文件所在的目录
include #对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些文件均是用c++定义,通常用于c++程序访问HDFS或者编写MapReduce程序。
lib #该目录包含了hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用。
libexec #各个服务队用的shell配置文件所在的免疫力,可用于配置日志输出,启动参数(比如JVM参数)等基本信息。
sbin #hadoop管理脚本所在的目录,主要包含HDFS和YARN中各类服务的启动、关闭脚本。
share #hadoop 各个模块编译后的jar包所在的目录。官方示例也在其中
配置文件目录:
/opt/bigdata/hadoop/server/hadoop-3.3.1/etc/hadoop
官方文档:https://hadoop.apache.org/docs/r3.3.1/
- 修改hadoop-env.sh
# 在hadoop-env.sh文件末尾追加
export JAVA_HOME=/opt/bigdata/hadoop/server/jdk1.8.0_212
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
- 修改core-site.xml 核心模块配置
在<configuration></configuration>中间添加如下内容
<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-node1:8082</value>
</property>
<!-- 设置Hadoop本地保存数据路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/bigdata/hadoop/data/hadoop-3.3.1</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 聚合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.hosts</name>
<value>*</value>
</property>
<!-- 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
- hdfs-site.xml hdfs文件系统模块配置
在<configuration></configuration>中间添加如下内容
<!-- 设置SNN进程运行机器位置信息 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-node2:9868</value>
</property>
<!-- 必须将dfs.webhdfs.enabled属性设置为true,否则就不能使用webhdfs的LISTSTATUS、LISTFILESTATUS等需要列出文件、文件夹状态的命令,因为这些信息都是由namenode来保存的。 -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
- 修改mapred.xml MapReduce模块配置
在<configuration></configuration>中间添加如下内容
<!-- 设置MR程序默认运行模式,yarn集群模式,local本地模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-node1:10020</value>
</property>
<!-- MR程序历史服务web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-node1:19888</value>
</property>
<!-- yarn环境变量 -->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- map环境变量 -->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- reduce环境变量 -->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
- 修改yarn-site.xml yarn模块配置
在<configuration></configuration>中间添加如下内容
<!-- 设置YARN集群主角色运行集群位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop-node1:19888/jobhistory/logs</value>
</property>
<!-- 设置yarn历史日志保存时间 7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604880</value>
</property>
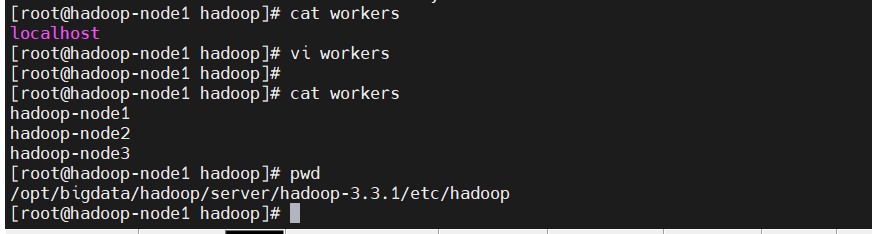
- 修改workers
将下面内容覆盖文件,默认只有localhost
hadoop-node1
hadoop-node2
hadoop-node3
$ cd /opt/bigdata/hadoop/server/将hadoop添加到环境变量(所有节点)
$ scp -r hadoop-3.3.1 hadoop-node2:/opt/bigdata/hadoop/server/
$ scp -r hadoop-3.3.1 hadoop-node3:/opt/bigdata/hadoop/server/
$ vi /etc/profile
export HADOOP_HOME=/opt/bigdata/hadoop/server/hadoop-3.3.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
# 加载
$ source /etc/profile
更多关于大数据 Hadoop系列的学习文章,请参阅:进击大数据系列,本系列持续更新中。
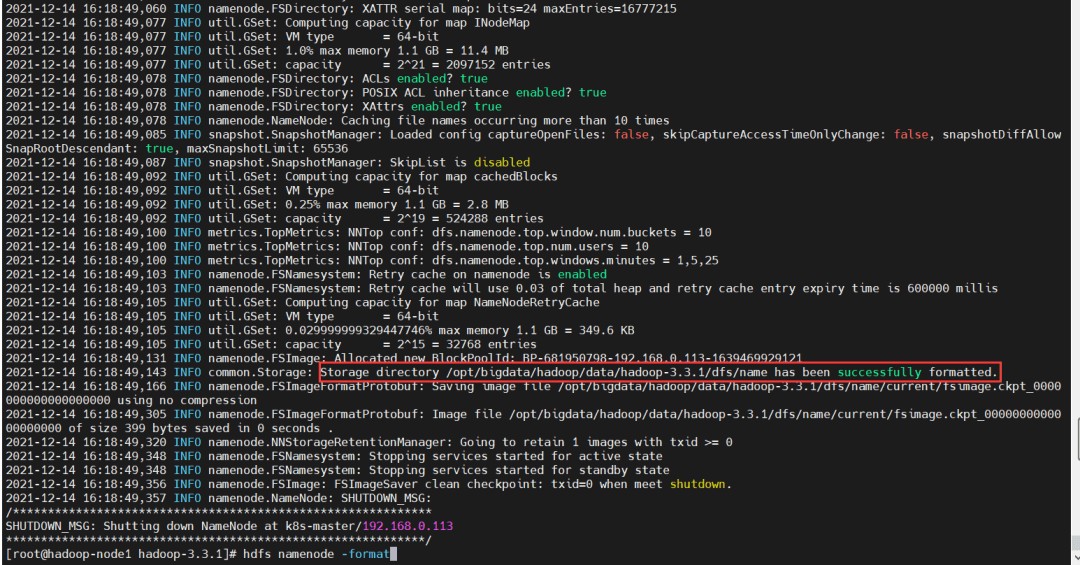
Hadoop集群启动(hadoop-node1上执行)(首次启动)格式化namenode(只能执行一次)
- 首次启动HDFS时,必须对其进行格式化操作
- format本质上初始化工作,进行HDFS清理和准备工作
$ hdfs namenode -format
每台机器每次手动启动关闭一个角色进程,可以精确控制每个进程启停,避免群起群停
HDFS集群启动
$ hdfs --daemon start|stop namenode|datanode|secondarynamenode
YARN集群启动
$ yarn --daemon start|stop resourcemanager|nodemanager通过shell脚本一键启动
在hadoop-node1上,使用软件自带的shell脚本一键启动。前提:配置好机器之间的SSH免密登录和works文件
- HDFS集群启停
$ start-dfs.sh
$ stop-dfs.sh #这里不执行
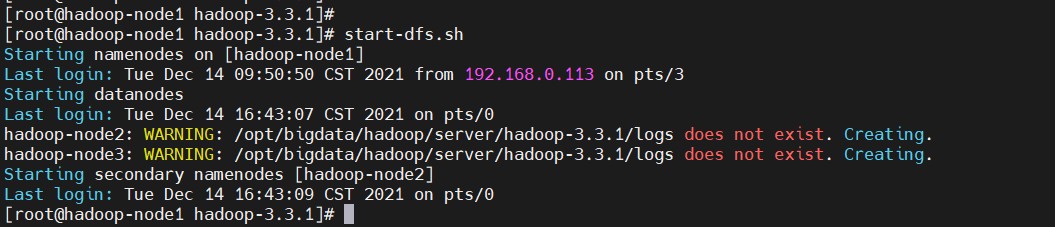
检查java进程
$ jps

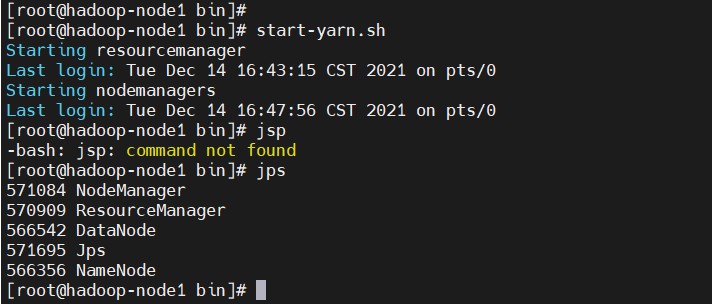
- YARN集群启停
$ start-yarn.sh
$ stop-yarn.sh # 这里不执行
# 查看java进程
$ jps
通过日志检查,日志路径:/opt/bigdata/hadoop/server/hadoop-3.3.1/logs
$ cd /opt/bigdata/hadoop/server/hadoop-3.3.1/logs
$ ll
- Hadoop集群启停(HDFS+YARN)
$ start-all.sh通过web页面访问
$ stop-all.sh
【注意】在window C:\Windows\System32\drivers\etc\hosts文件配置域名映射,hosts文件中增加如下内容:
192.168.0.113 hadoop-node1
192.168.0.114 hadoop-node2
192.168.0.115 hadoop-node3
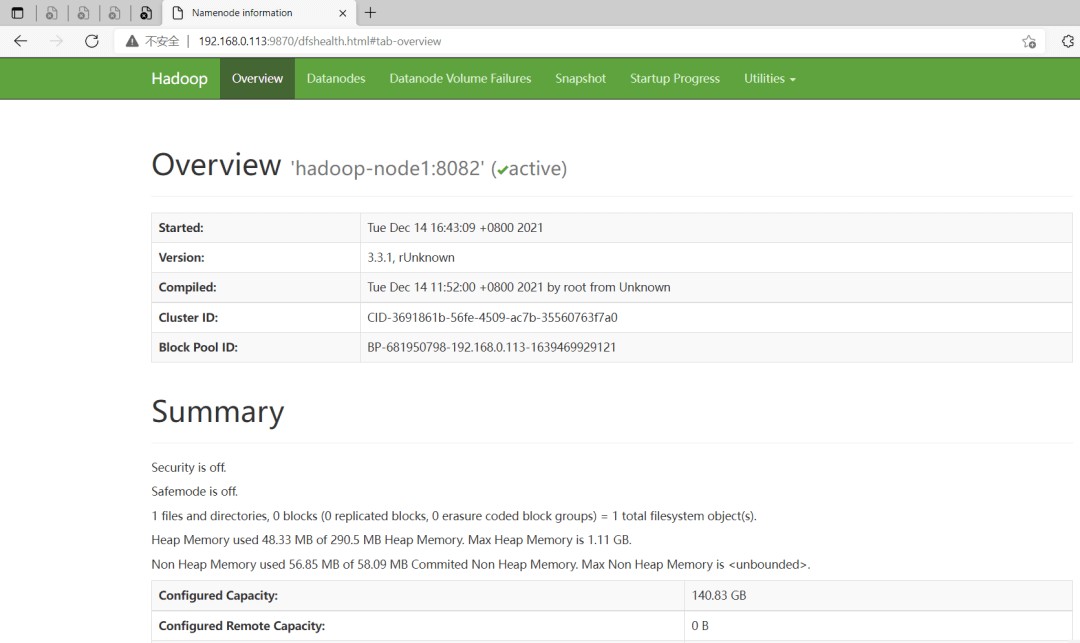
HDFS集群
地址:http://namenode_host:9870
这里地址为:http://192.168.0.113:9870
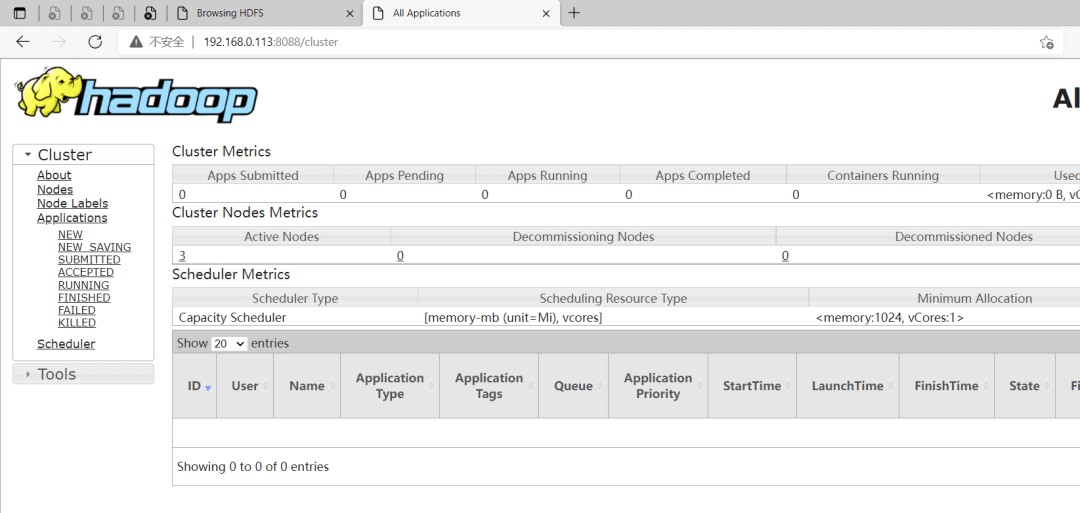
YARN集群
地址:http://resourcemanager_host:8088
这里地址为:http://192.168.0.113:8088
到此为止,hadoop和yarn集群就已经部署完了~
Hadoop 实战操作
HDFS 实战操作
命令介绍# 访问本地文件系统查看配置
$ hadoop fs -ls file:///
# 默认不带协议就是访问hdfs文件系统
$ hadoop fs -ls /
$ cd /opt/bigdata/hadoop/server/hadoop-3.3.1/etc/hadoop
$ grep -C5 'fs.defaultFS' core-site.xml
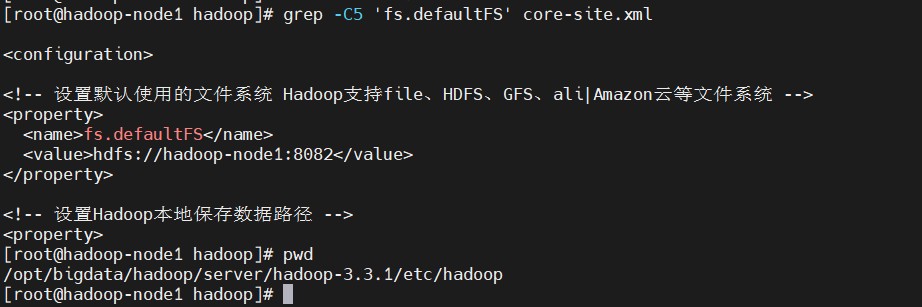
# 这里加上hdfs协议与不带协议等价
$ hadoop fs -ls hdfs://hadoop-node1:8082/

【温馨提示】所以默认不带协议就是访问HDFS文件系统。
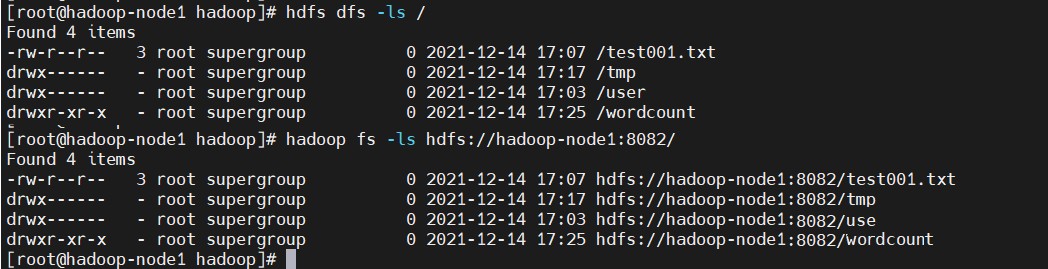
老版本的使用方式$ hdfs dfs -ls /
$ hdfs dfs -ls hdfs://hadoop-node1:8082/
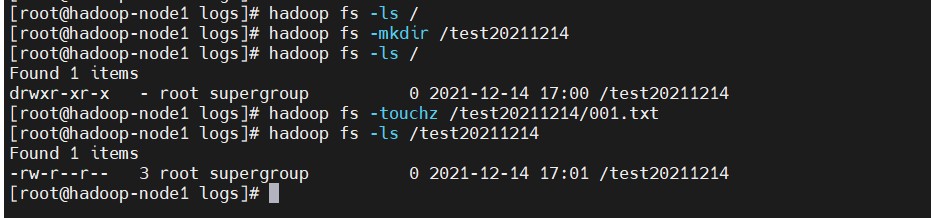
1、创建和删除文件
# 查看
$ hadoop fs -ls /
# 创建目录
$ hadoop fs -mkdir /test20211214
$ hadoop fs -ls /
# 创建文件
$ hadoop fs -touchz /test20211214/001.txt
$ hadoop fs -ls /test20211214
2、web端查看
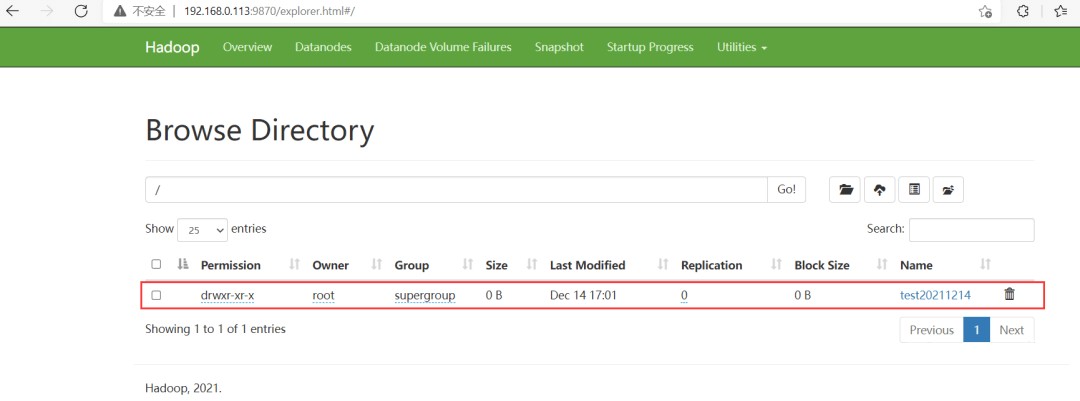
# 删除文件
$ hadoop fs -rm /test20211214/001.txt
# 删除目录
$ hadoop fs -rm -r /test20211214
3、推送文件到hdfs
$ touch test001.txt
$ hadoop fs -put test001.txt /
$ hadoop fs -ls /

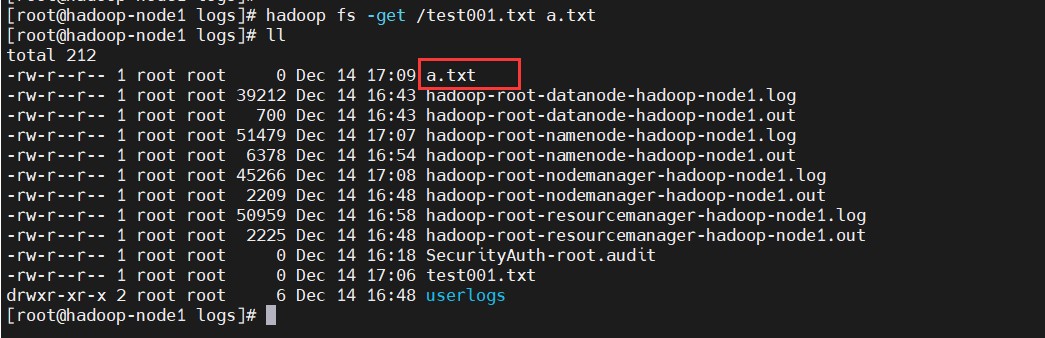
4、从hdfs上拉取文件
# 把test001.txt拉取下来,并改名为a.txt
$ hadoop fs -get /test001.txt a.txt
MapReduce+YARN 实战操作
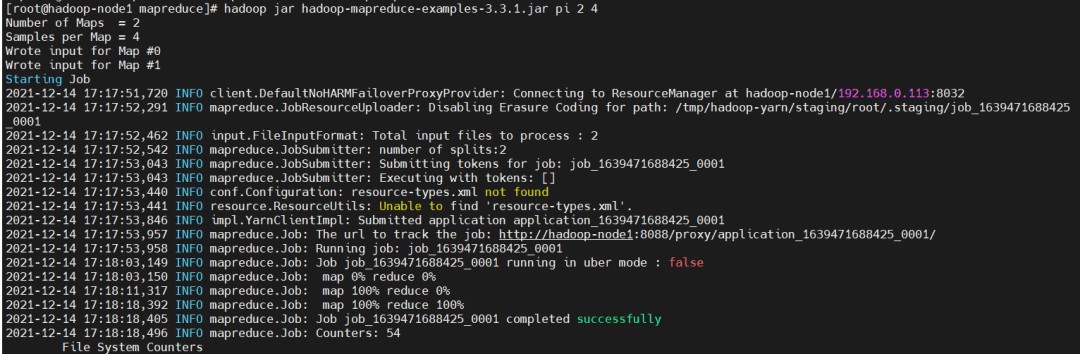
执行Hadoop官方自带的MapReduce案例,评估圆周率Π的值$ cd /opt/bigdata/hadoop/server/hadoop-3.3.1/share/hadoop/mapreduce
$ hadoop jar hadoop-mapreduce-examples-3.3.1.jar pi 2
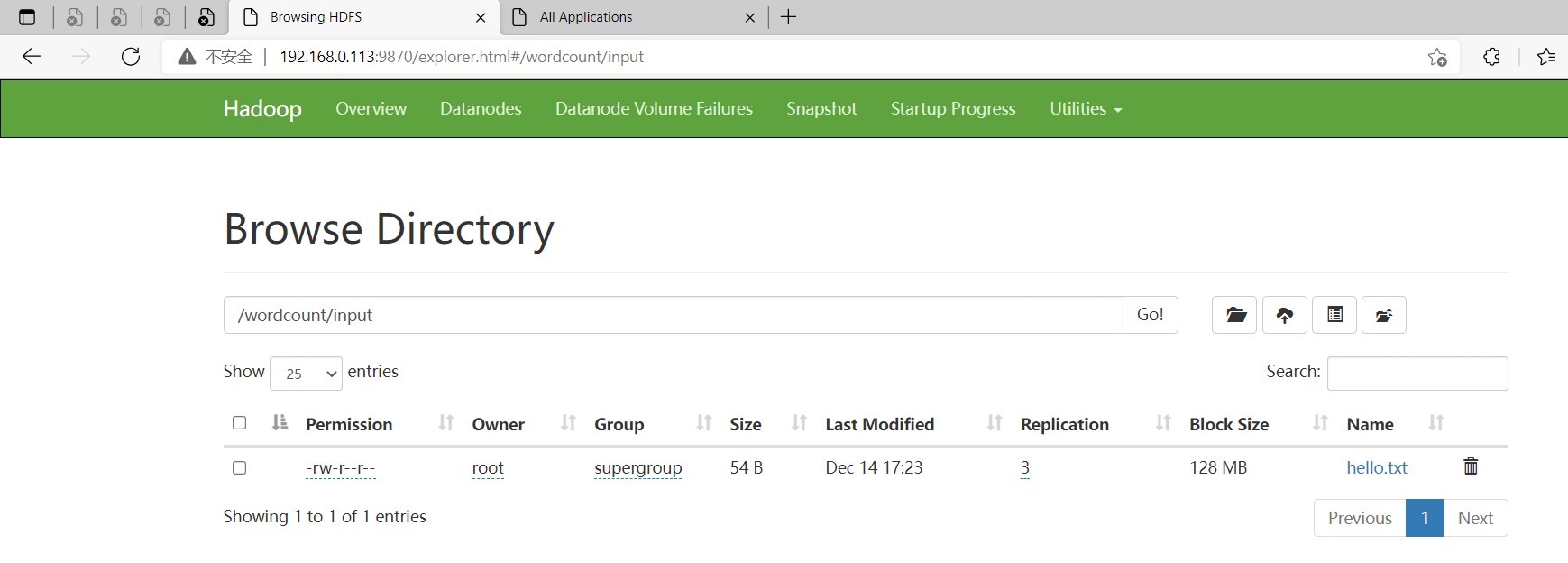
创建hello.txt,文件内容如下:
hello hadoop yarn world
hello yarn hadoop
hello world
在hdfs创建存放文件目录
$ hadoop fs -mkdir -p /wordcount/input
# 把文件上传到hdfs
$ hadoop fs -put hello.txt /wordcount/input/
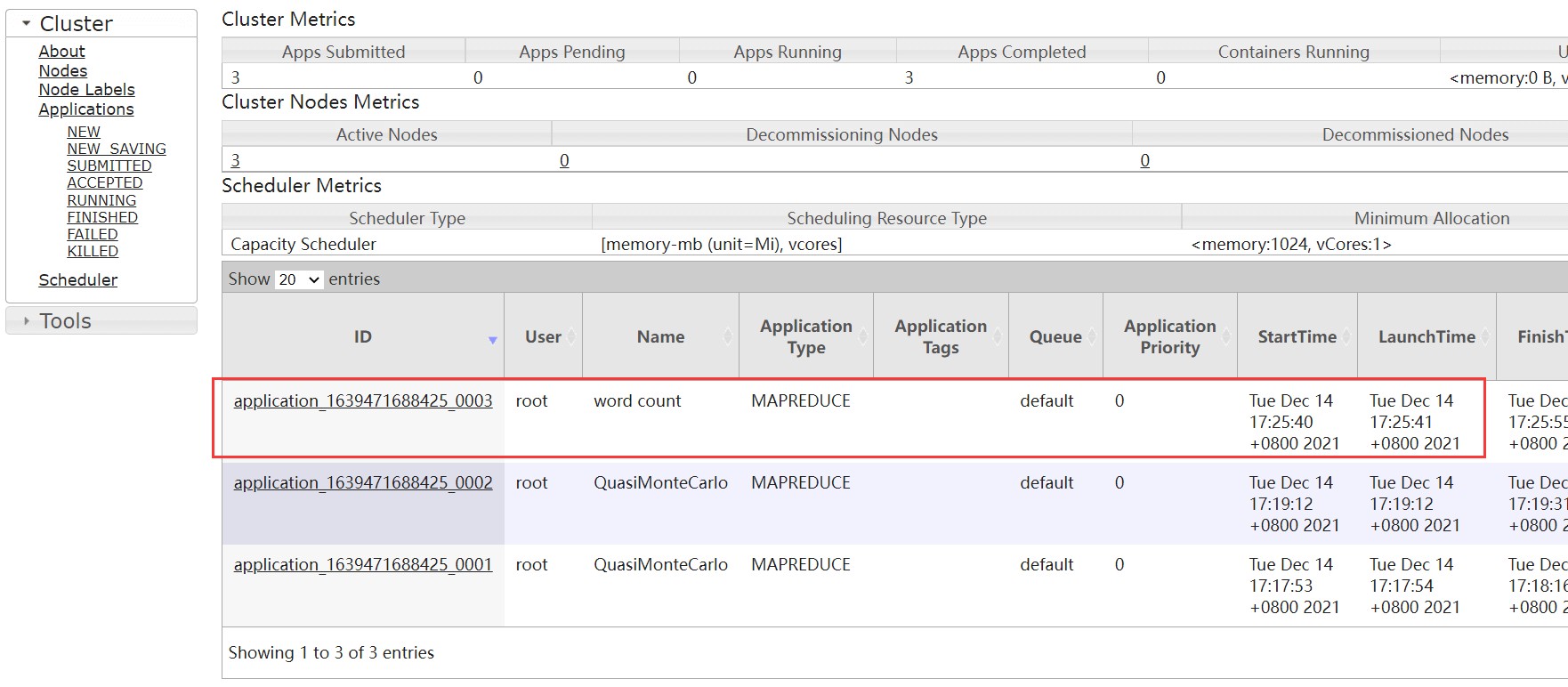
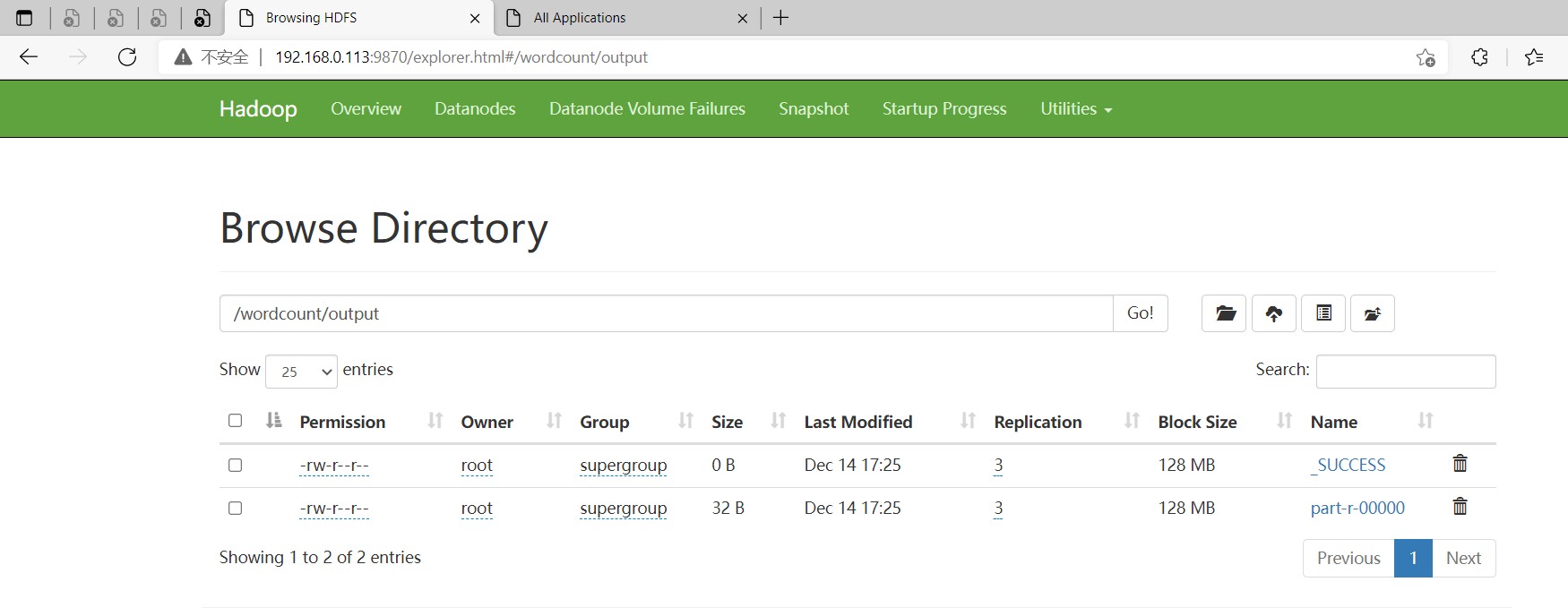
执行
$ cd /opt/bigdata/hadoop/server/hadoop-3.3.1/share/hadoop/mapreduce
$ hadoop jar hadoop-mapreduce-examples-3.3.1.jar wordcount /wordcount/input /wordcount/output
Yarn的常用命令
使用语法:yarn application [options] #打印报告,申请和杀死任务
-appStates <States> #与-list一起使用,可根据输入的逗号分隔的应用程序状态列表来过滤应用程序。有效的应用程序状态可以是以下之一:ALL,NEW,NEW_SAVING,SUBMITTED,ACCEPTED,RUNNING,FINISHED,FAILED,KILLED简单示例
-appTypes <Types> #与-list一起使用,可以根据输入的逗号分隔的应用程序类型列表来过滤应用程序。
-list #列出RM中的应用程序。支持使用-appTypes来根据应用程序类型过滤应用程序,并支持使用-appStates来根据应用程序状态过滤应用程序。
-kill <ApplicationId> #终止应用程序。
-status <ApplicationId> #打印应用程序的状态。
# 列出在运行的应用程序
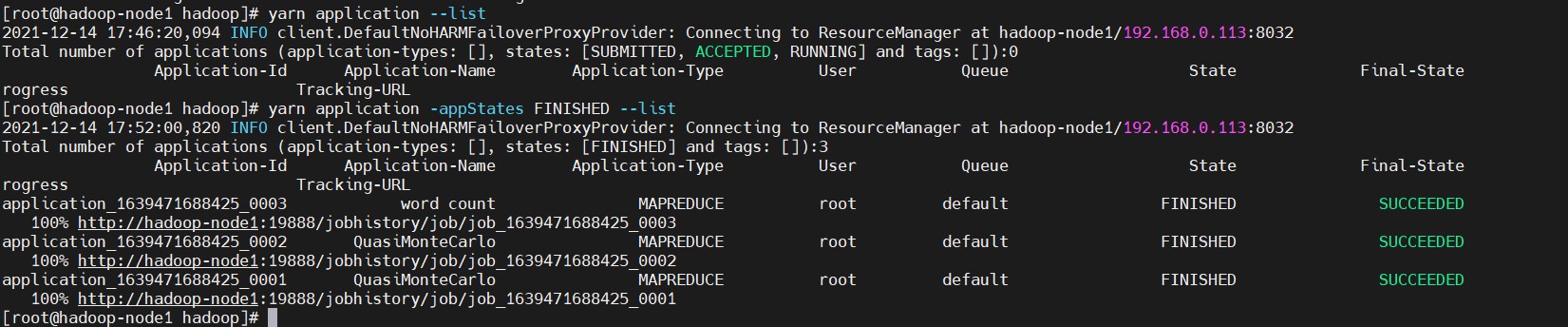
$ yarn application --list
# 列出FINISHED的应用程序
$ yarn application -appStates FINISHED --list
更多操作命令,可以自行查看帮助。
$ yarn -help
[root@hadoop-node1 hadoop]# yarn -help
Usage: yarn [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS]
or yarn [OPTIONS] CLASSNAME [CLASSNAME OPTIONS]
where CLASSNAME is a user-provided Java class
OPTIONS is none or any of:
--buildpaths attempt to add class files from build tree
--config dir Hadoop config directory
--daemon (start|status|stop) operate on a daemon
--debug turn on shell script debug mode
--help usage information
--hostnames list[,of,host,names] hosts to use in worker mode
--hosts filename list of hosts to use in worker mode
--loglevel level set the log4j level for this command
--workers turn on worker mode
SUBCOMMAND is one of:
Admin Commands:
daemonlog get/set the log level for each daemon
node prints node report(s)
rmadmin admin tools
scmadmin SharedCacheManager admin tools
Client Commands:
app|application prints application(s) report/kill application/manage long running application
applicationattempt prints applicationattempt(s) report
classpath prints the class path needed to get the hadoop jar and the required libraries
cluster prints cluster information
container prints container(s) report
envvars display computed Hadoop environment variables
fs2cs converts Fair Scheduler configuration to Capacity Scheduler (EXPERIMENTAL)
jar <jar> run a jar file
logs dump container logs
nodeattributes node attributes cli client
queue prints queue information
schedulerconf Updates scheduler configuration
timelinereader run the timeline reader server
top view cluster information
version print the version
Daemon Commands:
nodemanager run a nodemanager on each worker
proxyserver run the web app proxy server
registrydns run the registry DNS server
resourcemanager run the ResourceManager
router run the Router daemon
sharedcachemanager run the SharedCacheManager daemon
timelineserver run the timeline server
SUBCOMMAND may print help when invoked w/o parameters or with -h.
这里只是简单的dmeo案例演示操作……
- 发表于 2023-07-22 20:28
- 阅读 ( 478 )
