万字PostgreSQL经验谈
前言
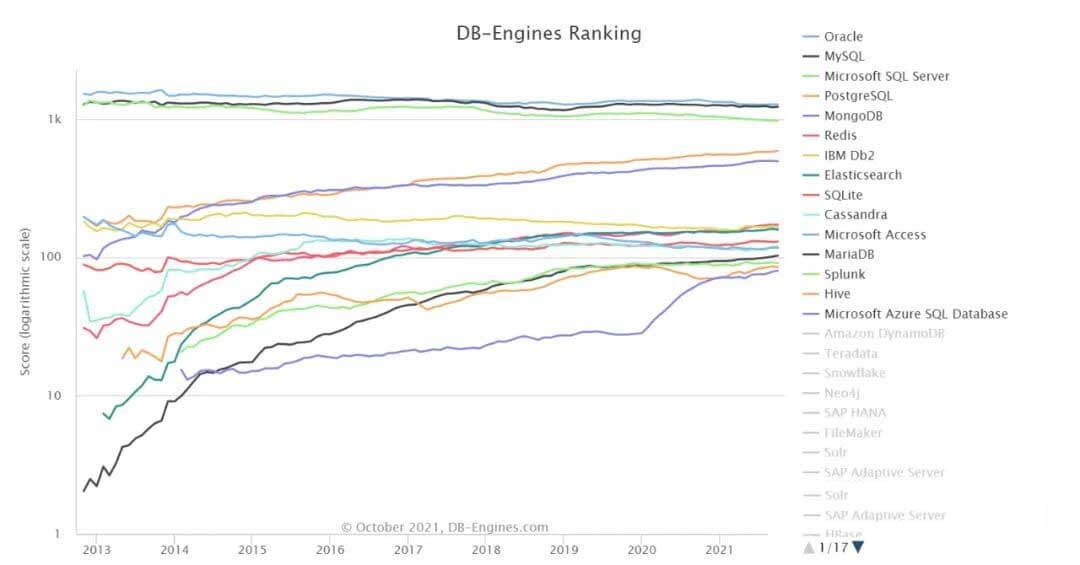
PostgreSQL在中国的发展势头越来越好,作为一个企业级开源数据库,PostgreSQL的目标就是替代商业数据库巨头Oracle,在满足数据库稳定性、可靠性、可用性等企业基本诉求的前提下,满足企业安全、合规、自主可控、成本控制等迫切的需求。在DB-Engines上,可以看到,PostgreSQL的分数稳定上涨中,极有希望再次摘得年度数据库的称号。
笔者接触PostgreSQL也快5个年头了,作为头号粉丝,我个人也十分乐意能将自己的踩坑记录和经验分享出来,助力PostgreSQL在中国更好的发展。这也是此篇的由来,篇幅较长,请耐心阅读,相信一定会对各位有所帮助。
关于进程
相关概念
首先是老生常谈的架构模型,在这点上,PostgreSQL和Oracle是一样的,采用的都是进程模型,而MySQL是线程模型。进程和线程息息相关,又有不同:
•进程是系统资源分配的最小单位•线程是CPU操作和调度的最小单位
进程就好比工厂的车间,它代表CPU所能处理的单个任务。任一时刻,单个CPU总是运行一个进程,其他进程处于非运行状态,等待被调度。

操作系统会将CPU时间划分为一段段的时间片,这些时间片再被轮流分配给各个进程,宏观上看就好像有许多进程在并行跑
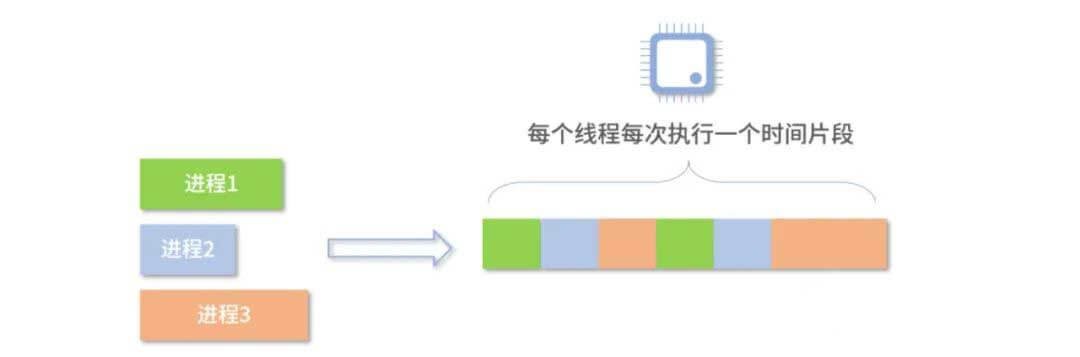
而一个车间里,当然可以有很多工人。他们协同完成一个任务。线程就好比车间里的工人。一个进程可以包括多个线程。

车间的空间是工人们共享的,比如许多房间是每个工人都可以进出的,比如仓库、厕所等。这象征一个进程的内存空间是共享的,每个线程都可以使用这些共享内存。
我们可以看到,线程会共享进程范围内的部分资源,比如内存和文件句柄,但是每个线程也有自己私有的内容,比如程序计数器、栈以及局部变量。而进程之间的资源是独立的,因此一个进程崩溃后,不会对其他进程产生影响,但是一个线程崩溃整个进程都死掉,所以多进程相对而言要比多线程更加健壮,或许这也是PostgreSQL最开始设计的时候所考虑的,但其缺点就是创建的开销大、上下文切换开销大,而且PostgreSQL一个比较大的问题在于,有大量连接或者短连接的情况下,性能堪忧。
相关问题
对于大量连接的情况下,导致性能下降,总共有以下几个原因:
1.固定的连接开销2.元数据的膨胀3.不合理的参数4.快照
连接开销
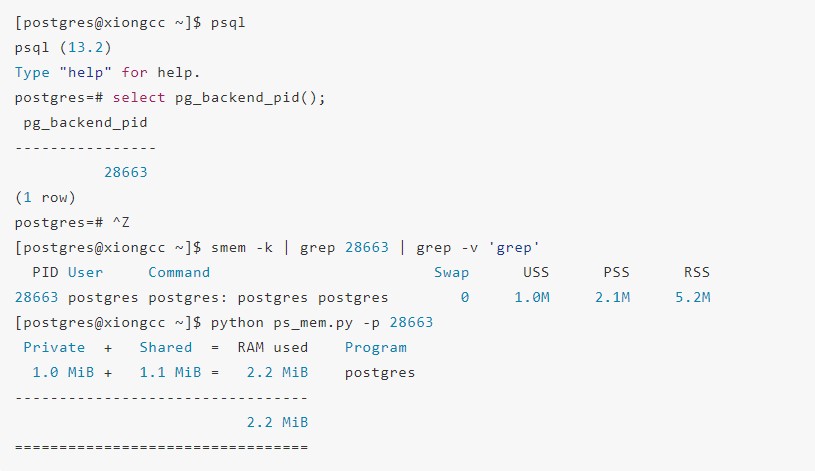
首先连接开销,前文也叙述了,进程的创建开销是比较大的,连接越多,使用的内存数量越多。但是每个连接创建使用到的固定内存(非运行后的内存)其实并不多,可以看到,对于一个连接大约使用到2MB左右的内存,对于开启了大页的环境,这个值会更少,所以固定的连接开销不是问题。
元数据的膨胀
第二个是元数据的膨胀,在生产中,我们经常可以看到,假如有某些生命周期特别长的连接,同时这个连接还访问了很多的表,那么会发现meta cache特别大,PostgreSQL会将访问过的表结构、索引、视图进行缓存等,另外再加上预备语句(非Oracle Cursor sharing),这个也是本地内存,这就会导致内存使用量随着时间的推移,不断上涨。
在v14中,新增了pg_backend_memory_contexts视图用于观察内存:
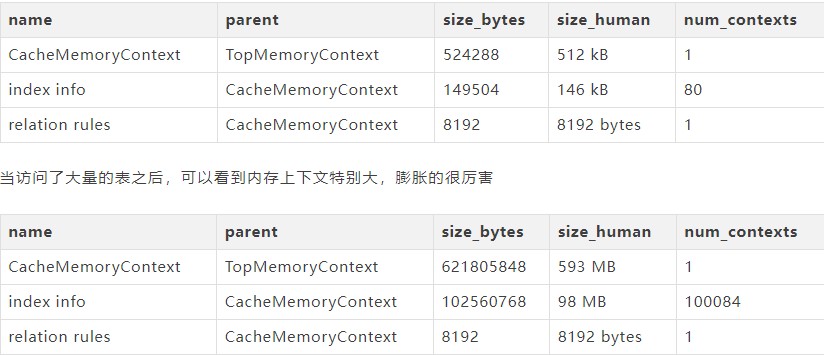
当然这个也不是无解,可以通过连接池来控制连接的生命周期。而且元数据膨胀只是针对于含有大量对象的数据库,不过依然值得改进,尤其是SaaS行业和多租户的场景,每个B端用户都有一套schema,一个会话在整个生命周期内可能访问很多的数据库对象。
在v13开始,PostgreSQL会删除一些很少访问的不变内容的元数据缓存。
不合理的参数
这个就主要是work_mem了,如果有多个用户尝试执行排序操作,则系统将为所有用户分配大小为work_mem * 总排序操作数的空间。请注意对于复杂的查询,可能会同时并发运行好几个排序或散列(hash)操作;每个排序或散列操作都会分配这个参数声明的内存来存储中间数据。同样,好几个正在运行的会话可能会同时进行排序操作,因此使用的总内存量可能是work_mem的很多倍,这还没有算上并行。所以需要合理配置该参数,对于PG系列的分布式数据库,比如Tbase、Antdb、Gbase8s等,往往面对的场景并发都很大,切忌设置特别大,不然很容易就OOM了。
快照
这个我放在最后,不难猜到,快照正是限制PostgreSQL无法承载大量连接的罪魁祸首了。
相关优化
在9月30号,14大版本终于和各位见面了!在14的版本中,一大重量级新特性便是提升了拥有海量连接的吞吐量,不管是active的还是idle的,都有了极大的提升,此处可以参照网上和唐成老师的测试样例:
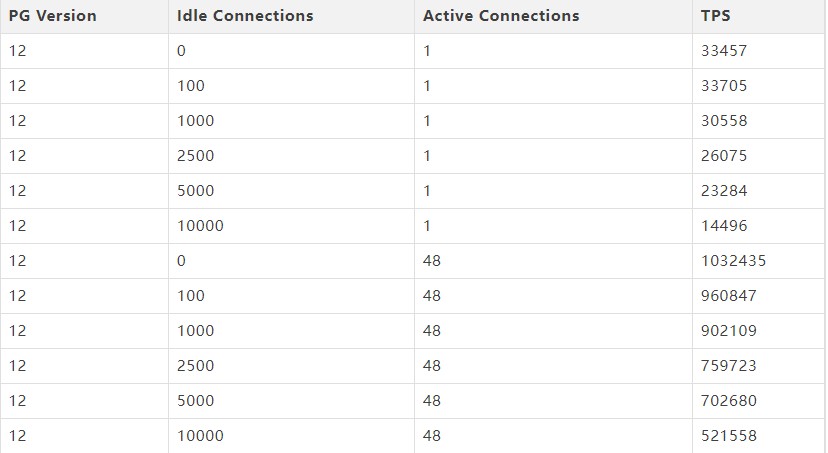
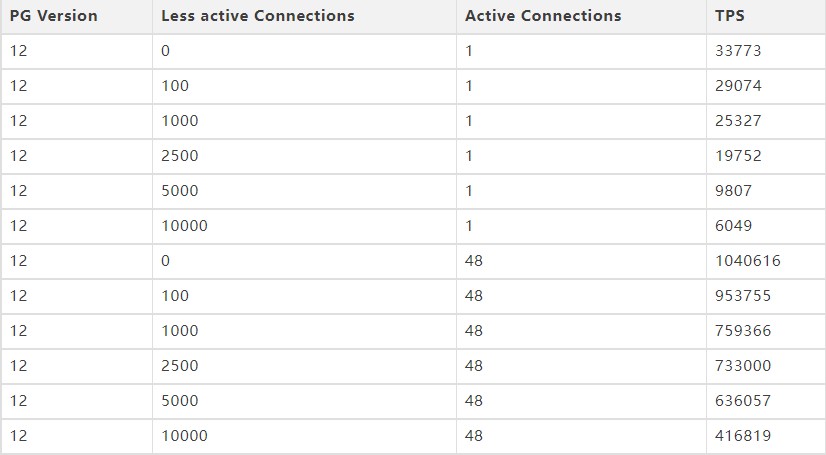
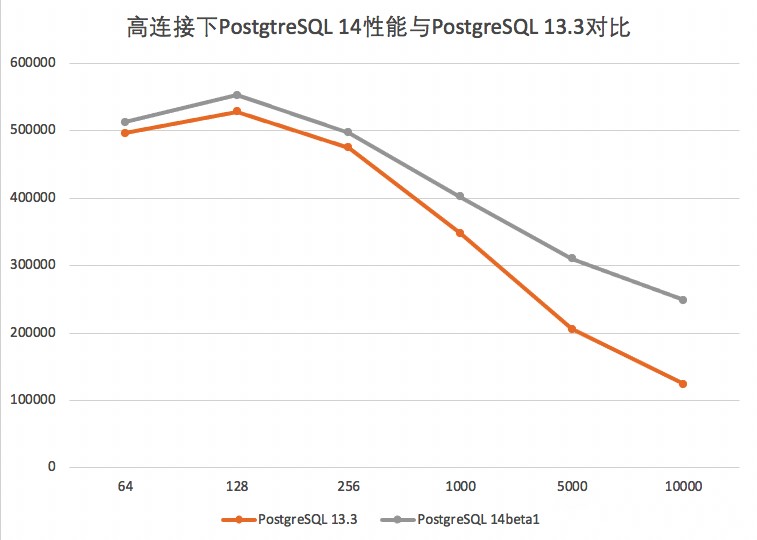
主要优化的逻辑在于GetSnapshotData() 这个函数上,针对GetSnapshotData,社区开发人员一直在不断地进行优化,可以看到,一个GetSnapshotData占了CPU 50%左右的时间
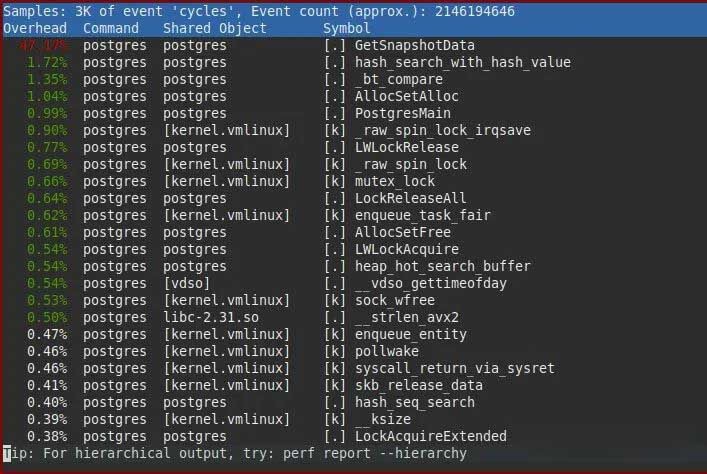
要了解背后的优化原理,还得从基本的实现方式说起。首先我们知道,PostgreSQL是基于快照(snapshot)实现的MVCC
要了解背后的优化原理,还得从基本的实现方式说起。首先我们知道,PostgreSQL是基于快照(snapshot)实现的MVCC
typedef struct SnapshotData
{
…
TransactionId xmin; /* all XID < xmin are visible to me */
TransactionId xmax; /* all XID >= xmax are invisible to me */
…
/*
* For normal MVCC snapshot this contains the all xact IDs that are in
* progress, unless the snapshot was taken during recovery in which case
* it's empty. …
* note: all ids in xip[] satisfy xmin <= xip[i] < xmax
*/
TransactionId *xip;
uint32 xcnt; /* # of xact ids in xip[] */
…
主要有三个关键字段,xip_list
•xmin:最早的状态仍为active的事务txid,所有比它更早的事务(txid<xmin),要么已提交并可见,要么已回滚并生成死元组
•xmax:获取快照时第一个尚未分配的xid,所有txid>=xmax的事务在获取快照时尚未启动,因此其结果对当前事务不可见
•xip_list:指在获取快照时,所有正在运行的事务ID列表,该列表仅包含[xmin,xmax)范围内的活跃事务txid
可以看到,可见性规则的判断依赖xip_list,而对于每一个PostgreSQL的后端进程,在共享内存中都有一个结构体PGPROC用于追踪正在运行的后端进程和事务,PGPROC会跟踪正在运行的事务、信号量,也有正在等待的锁信息等等。
在13版本里,源码如下
struct PGPROC
{
/* proc->links MUST BE FIRST IN STRUCT (see ProcSleep,ProcWakeup,etc) */
SHM_QUEUE links; /* list link if process is in a list */
PGPROC **procgloballist; /* procglobal list that owns this PGPROC */
PGSemaphore sem; /* ONE semaphore to sleep on */
int waitStatus; /* STATUS_WAITING, STATUS_OK or STATUS_ERROR */
Latch procLatch; /* generic latch for process */
LocalTransactionId lxid; /* local id of top-level transaction currently
* being executed by this proc, if running;
* else InvalidLocalTransactionId */
int pid; /* Backend's process ID; 0 if prepared xact */
...
}
/*
* Prior to PostgreSQL 9.2, the fields below were stored as part of the
* PGPROC. However, benchmarking revealed that packing these particular
* members into a separate array as tightly as possible sped up GetSnapshotData
* considerably on systems with many CPU cores, by reducing the number of
* cache lines needing to be fetched. Thus, think very carefully before adding
* anything else here.
*/
typedef struct PGXACT
{
TransactionId xid; /* id of top-level transaction currently being
* executed by this proc, if running and XID
* is assigned; else InvalidTransactionId */
TransactionId xmin; /* minimal running XID as it was when we wereh
* starting our xact, excluding LAZY VACUUM:
* vacuum must not remove tuples deleted by
* xid >= xmin ! */
uint8 vacuumFlags; /* vacuum-related flags, see above */
bool overflowed;
uint8 nxids;
} PGXACT;
在14版本里,源码如下
struct PGPROC
{
/* proc->links MUST BE FIRST IN STRUCT (see ProcSleep,ProcWakeup,etc) */
SHM_QUEUE links; /* list link if process is in a list */
PGPROC **procgloballist; /* procglobal list that owns this PGPROC */
PGSemaphore sem; /* ONE semaphore to sleep on */
ProcWaitStatus waitStatus;
Latch procLatch; /* generic latch for process */
TransactionId xid;/* id of top-level transaction currently being
* executed by this proc, if running and XID
* is assigned; else InvalidTransactionId.
* mirrored in ProcGlobal->xids[pgxactoff] */
TransactionId xmin;/* minimal running XID as it was when we were
* starting our xact, excluding LAZY VACUUM:
* vacuum must not remove tuples deleted by
* xid >= xmin ! */
LocalTransactionId lxid; /* local id of top-level transaction currently
* being executed by this proc, if running;
* else InvalidLocalTransactionId */
int pid; /* Backend's process ID; 0 if prepared xact */
可以从注释中看到,在9.2之前(2011年左右),专门拆出来了一个数据结构PGXACT,用以在多核的环境下提升GetSnapshotData函数的性能。
Move "hot" members of PGPROC into a separate PGXACT array.
This speeds up snapshot-taking and reduces ProcArrayLock contention.
Also, the PGPROC (and PGXACT) structures used by two-phase commit are
now allocated as part of the main array, rather than in a separate
array, and we keep ProcArray sorted in pointer order. These changes
are intended to minimize the number of cache lines that must be pulled
in to take a snapshot, and testing shows a substantial increase in
performance on both read and write workloads at high concurrencies.
Pavan Deolasee, Heikki Linnakangas, Robert Haas
在14的版本里面,针对GetSnapshotData又进行了大量的优化:
1.snapshot scalability: Don’t compute global horizons while building snapshots.
2.snapshot scalability: Move PGXACT->xmin back to PGPROC.
3.snapshot scalability: Move PGXACT->vacuumFlags to ProcGlobal->vacuumFlags.
4.snapshot scalability: Move subxact info to ProcGlobal, remove PGXACT.
5.snapshot scalability: Introduce dense array of in-progress xids.
6.snapshot scalability: cache snapshots using a xact completion counter.
7.Fix race condition in snapshot caching when 2PC is used.
snapshot scalability: Move PGXACT->xmin back to PGPROC.
Now that xmin isn't needed for GetSnapshotData() anymore, it leads to
unnecessary cacheline ping-pong to have it in PGXACT, as it is updated
considerably more frequently than the other PGXACT members.
After the changes in dc7420c2c92, this is a very straight-forward change.
For highly concurrent, snapshot acquisition heavy, workloads this change alone
can significantly increase scalability. E.g. plain pgbench on a smaller 2
socket machine gains 1.07x for read-only pgbench, 1.22x for read-only pgbench
when submitting queries in batches of 100, and 2.85x for batches of 100
'SELECT';. The latter numbers are obviously not to be expected in the
real-world, but micro-benchmark the snapshot computation
scalability (previously spending ~80% of the time in GetSnapshotData()).
现在,GetSnapshotData()函数已不再需要xmin
xmin的频繁更新会导致PGXACT结构体在CPU缓存中不必要的ping-pong(不同的进程会在不同的核中执行)。
对于高并发、快照获取繁重的工作负载,仅此更改就可以显著提高可伸缩性。
简单来说,频繁更新xmin,会带来较为严重的CPU缓存一致性的问题,下面是讨论邮件:
你好,
我认为postgres在扩展到更多连接数量方面的问题是该领域的一个严重问题。虽然池可以解决其中的一些问题,但考虑到准备语句、事务状态等问题,我认为在很多情况下这是不够的。它还增加了延迟。
我也不认为一个人不应该拥有超过几十个连接的论点有什么意义。由于客户机需要考虑时间,并且必须发送/接收数据库结果(大多数客户机不使用管道),由于许多应用程序有许多具有独立连接池的应用程序服务器,因此需要比postgres容易处理的更多的连接是非常常见的。
最大的原因是GetSnapshotData()。它很难扩展到更大的连接数。部分原因显然是复杂度O(connections)的关系,但我一直认为它应该更多。我已经看到生产工作负载花费了> 98%的cpu时间在GetSnapshotData()。
经过大量的分析和实验,我发现其主要原因是PGXACT->xmin。即使是最简单的事务在其生命周期内也会修改MyPgXact->xmin多次(exec_bind_message()的IIRC两次(snapshot & release),exec_exec_message()的IIRC两次(snapshot & release),然后作为EOXact处理的一部分再次修改)。这意味着后端在一个系统上执行GetSnapshotData()时,很可能会碰到由另一个cpu /一组cpu / socket拥有的PGXACT cachelines。系统越大,其后果就越严重。
对于xmin,这个问题最为突出(而且更难修复),但PGXACT中的其他字段也存在这个问题。我们很少设置xid、nxids、overflow或vacuumFlags,但会不断设置它们,导致跨节点流量。
第二个最大的问题是,GetSnapshotData()必须通过pgprocnos间接获取每个后端xmin,这对于流水线CPU(即所有的postgres运行)是非常不友好的。基本上在每次循环迭代的末尾都会有一个暂停——这是由于有如此多的缓存丢失而加剧的。
避免不必要地弄脏除xmin之外的所有PGXACT字段的cachelines是相当容易的。因为它需要对其他后端可见。
虽然事后看来这几乎是微不足道的,但我花了很长时间才掌握了这个问题的很大一部分的解决方案:我们实际上不需要查看PGXACT->xmin来计算快照。GetSnapshotData()这样做的唯一原因是,因为它也计算RecentGlobal[Data]Xmin。
但实际上我们并不经常需要它们。它们主要用作heap_page_prune_opt()等的水平。但首先,虽然修剪真的很重要,但它并不是“每时每刻”都在发生。但更重要的是,来自早期事务的RecentGlobalXmin实际上足以满足大多数修剪请求,特别是当读取事务的百分比大于更新事务时(非常常见)。
通过让GetSnapshotData()计算一个我们确定不能修剪的精确上限(基本上是事务的xmin、槽位等),以及一个保守的下限,在这个下限以下我们肯定能够修剪,我们可以允许一些修剪操作发生。如果剪枝请求(或类似的请求)在这些请求之间遇到xid,则可以计算出准确的下界。
这允许避免查看PGXACT->xmin。
为了解决第二个大问题(间接),我们可以将PGXACT的内容紧密打包,就像我们对pgprocnos所做的那样。在所附的系列中,我介绍了xids、vacuumFlags和nsubxids的独立数组。
分开它们的原因是它们以不同的速度变化,大小也不同。在以读为主的工作负载中,大多数后端都不会有xid,因此xids数组几乎是恒定的。只要所有的xid都未被赋值,GetSnapshotData()就不需要查看任何其他内容,因此首先检查xid是明智的。
内容有点多,简单总结一下:
1.当事务要进行查询操作时,需要构建一个快照,快照包括xmin、xmax和xip_list,而事务的信息是保存在PGPROC和PGXACT两个结构体中的,要生成快照,就要遍历PGPROC和PGXACT。
2.在9.2以前,没有PGXACT这个结构体,该结构体中的变量原本都放在PGPROC之中,导致该结构体体积十分庞大和臃肿,并且在获取快照的时候又需要遍历所有的PGPROC数组,所以专门拆除了一个PGXACT结构体出来。
3.在PostgreSQL14中,又对PGXACT进行拆分,将xmin和xid移回了PGPROC,同时GetSnapshotData不再需要获取xmin了,xmin由于频繁更新,在高并发的场景下,不同进程遍历PGXACT会导致Cache ping-pong的问题。主要是这个patch做的事情 https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=dc7420c2c9274a283779ec19718d2d16323640c0。After that commit we do not access ->xmin in GetSnapshotData() anymore. To avoid the cache-line ping-pong, we can move it out of the data used by GetSnapshotData(). That alone provides a substantial improvement in scalability.
多提一嘴,Cache Miss,即CPU Cache ping-pong的问题,在现代大多数处理器中,Cache会被分为很多行(Cache Line),当一行 Cache Line 被从内存拷贝到 Cache 里,Cache 里会为这个 Cache Line 创建一个条目。这个 Cache 条目里既包含了拷贝的内存数据,即 Cache Line,又包含了这行数据在内存里的位置等元数据信息。在多CPU的架构下,就存在缓存一致性的问题,有两种情况可能导致Cache 中的数据过期:
1.DMAC,有其他设备直接更新了主存上的数据
2.同一个Cache line存在多个CPU各自的cache中,其中一个CPU对其进行了更新
所以CPU Miss需要等待数据从内存读到Cache 中,在多CPU的架构下,该结构体在CPU Cache之间会来回ping-pong,影响扩展性。
移走了xmin之后,新增了GlobalVis*相关函数来判断元组是否可清理 (大于OldestXmin的元组,vacuum无法清理) ,同时在PROC_HDR结构体中对PGPROC的xid做镜像。
* 1) GlobalVisSharedRels, which only considers an XID's
* effects visible-to-everyone if neither snapshots in any database, nor a
* replication slot's xmin, nor a replication slot's catalog_xmin might
* still consider XID as running.
*
* 2) GlobalVisCatalogRels, which only considers an XID's
* effects visible-to-everyone if neither snapshots in the current
* database, nor a replication slot's xmin, nor a replication slot's
* catalog_xmin might still consider XID as running.
*
* I.e. the difference to GlobalVisSharedRels is that
* snapshot in other databases are ignored.
*
* 3) GlobalVisDataRels, which only considers an XID's
* effects visible-to-everyone if neither snapshots in the current
* database, nor a replication slot's xmin consider XID as running.
*
* I.e. the difference to GlobalVisCatalogRels is that
* replication slot's catalog_xmin is not taken into account.
*
* 4) GlobalVisTempRels, which only considers the current session, as temp
* tables are not visible to other sessions.
typedef struct PROC_HDR
{
/* Array of PGPROC structures (not including dummies for prepared txns) */
PGPROC *allProcs;
/* Array mirroring PGPROC.xid for each PGPROC currently in the procarray */
TransactionId *xids;
除此之外,对于快照的获取方式也进行了优化,在Read commit的隔离级别之下,每条命令都会重新获取一次快照,假如快照在两次命令期间没有发生变化,那么快照应该是相同的,PostgreSQL增加了快照重用机制,以减少开销。
参考
https://techcommunity.microsoft.com/t5/azure-database-for-postgresql/improving-postgres-connection-scalability-snapshots/ba-p/1806462
http://www.pgsql.tech/article_101_10000104
https://www.postgresql.org/message-id/20200301083601.ews6hz5dduc3w2se%40alap3.anarazel.de
https://techcommunity.microsoft.com/t5/azure-database-for-postgresql/analyzing-the-limits-of-connection-scalability-in-postgres/ba-p/1757266#constant-connection-overhead
https://brandur.org/postgres-connections
https://segmentfault.com/a/1190000039297639
https://www.ruanyifeng.com/blog/2013/04/processes_and_threads.html
关于WAL堆积
笔者见过很多WAL日志堆积导致磁盘打满,数据库宕机的生产案例了,数据库磁盘一旦满了,能进行操作的手段又比较少,所以对于有经验的DBA,一般都会在PGDATA下面创建一个占位符,比如10个G,关键时候删除救命。
所以在PostgreSQL中,这是一个很大的陷阱,我看见过无数小白掉进坑里。
失效复制槽
这个是最常见的情形,不管是逻辑复制、CDC或者是流复制的场景下(显式创建复制槽的话),都会用到复制槽,Replication slots 是从9.4引入的,分为逻辑复制槽、物理复制槽和临时复制槽。复制槽主要提供了一种自动化的方法来确保主库在所有的备库收到WAL日志之前不会移除它们,并且主库也不会移除可能导致恢复冲突的行(需要配合hot_standby_feedback,这样的话备库会定时性发送最老的事务号xmin,主库在vacuum清理死元组的时候会按需保留备库仍然需要的元组),即使备库断开也是如此。
比如我这个场景下,复制槽是false的,没有使用,那么从00000001000000010000003E之后的WAL日志,都会被保留,时间一久就会导致pg_wal目录占据了特别大的空间。
postgres=# select pg_walfile_name(restart_lsn),slot_name,slot_type,active,restart_lsn from pg_replication_slots ;
pg_walfile_name | slot_name | slot_type | active | restart_lsn
--------------------------+-----------+-----------+--------+-------------
00000001000000010000003E | sub1 | logical | f | 1/3E421988
(1 row)
[postgres@xiongcc ~]$ ls -l pgdata/pg_wal/
total 1904636
-rw------- 1 postgres postgres 16777216 Sep 22 17:52 00000001000000010000003E
-rw------- 1 postgres postgres 16777216 Sep 22 17:52 00000001000000010000003F
-rw------- 1 postgres postgres 16777216 Sep 22 17:52 000000010000000100000040
-rw------- 1 postgres postgres 16777216 Sep 22 17:52 000000010000000100000041
-rw------- 1 postgres postgres 16777216 Sep 22 17:52 000000010000000100000042
-rw------- 1 postgres postgres 16777216 Sep 22 17:52 000000010000000100000043
-rw------- 1 postgres postgres 16777216 Sep 22 17:52 000000010000000100000044
-rw------- 1 postgres postgres 16777216 Sep 22 17:52 000000010000000100000045
-rw------- 1 postgres postgres 16777216 Sep 22 17:52 000000010000000100000046
-rw------- 1 postgres postgres 16777216 Sep 22 17:52 000000010000000100000047
-rw------- 1 postgres postgres 16777216 Sep 22 17:52 000000010000000100000048
...
[postgres@xiongcc ~]$ ls -l pgdata/pg_wal/ | wc -l
120
为此,要对失效的复制槽进行监控,及时处理。
失效的归档
如果开启了归档,那么归档命令成功了,WAL才会被 remove/recycle,所以如果归档命令是失效的,那么 pg_wal 目录会一直增长,对应的现象便是pg_wal目录下存在大量的xxxxx.ready,PostgreSQL不会自动删除 WAL,此目录会持续增长,进而有撑爆磁盘的风险。
另外还有一个潜在的问题,因为restore_command可以是任意的shell命令,你可以备份到远程主机或第三方存储上面,所以对于写流量特别大的场景,WAL日志产生的速度会非常快,再加上FPI全页写以及不合理的参数进一步导致的WAL日志写放大,你会发现备份的速度根本赶不上归档的速度,这个也是一个额外的失效点,需要特别注意。
过小的archive_timeout
如果实例写入量很少,到达 archive_timeout 会触发 WAL 的强制切换。因此如果 archive_timeout 如果太短就会产生很多新的 WAL,从而产生大量归档。
Logical Decoding下的大事务
这个不怎么常见,主要是逻辑复制的场景下,同一条事务的WAL日志可能不是连续的(比如大事务,N久之后再做个写入动作),这个期间其他的WAL record继续连续顺序存放,使得WAL日志不断填充增长。而逻辑解码要求同一事务的逻辑日志要按顺序相邻排列并传送给订阅端,在RecordBuffer里面有一个TXN的唯一标识,用于标识事务。所以,假如开启了一个大事务,得从事务最开始的位点所在WAL日志,一直保留到事务提交时的WAL日志。具体可以参照之前的文章《逻辑复制不为熟知的点》
不合理的参数
这一点其实不太重要,主要是wal_keep_segments和max_wal_size,max_wal_size指定两次之间产生的 WAL 最大量。当然这只是一个软限制,在集群负载高或者一些其他异常情况下可能会超过这个值。当新产生的WAL文件到达后就会出发checkpoint,这个值越大,理论上WAL日志也越多。wal_keep_segments则是控制保留多少个WAL日志,用于控制备库可以失联多久。
关于备份
关于备份,PostgreSQL提供了pg_start_backup和pg_stop_backup这两种API,以及pg_basebackup封装好的工具。pg_start_backup和pg_stop_backup又分为排它备份和非排它备份。
排它备份
当使用基础备份进行恢复的时候,就会从backup_label文件中取出checkpoint_location,基于此开始进行恢复。注意一个隐藏的问题,There is no way to distinguish the data directory of a server crashed while in backup mode from a backup!
If an exclusive backup is in progress, and a crash situation occurs, the presence of the backup_label file means PostgreSQL is not able to determine whether it is starting as a backup or not, and will attempt to recover from the checkpoint location recorded in the file, which may reference WAL files no longer available.
For this reason, non-exclusive backups (supported by the replication protocol since PostgreSQL 9.1, and by pg_start_backup() since PostgreSQL 9.6) are the preferred method of making backups.
PostgreSQL目前无法做到准确的区分,那么就有可能产生两个问题:
1.数据库在执行pg_start_backup之后,crash了,重启之后会从backup_label中标识的checkpoint location进行回放,即使这个期间多次正常的checkpoint,pg_control里面更新了redo location。试想这样一个场景,两天前DBA做了pg_start_backup,但是由于什么原因忘记做了pg_stop_backup或者执行pg_stop_backup的时候报错了,那么backup_label的checkpoint location(redo location)就是两天前的,这个时候,一旦crash,意味着做recovery的时间就会特别长,应用也得一直等着,这个简直是一个巨大的隐患!2.backup_label指向的redo location所在的WAL日志可能被回收了!因为随着正常的checkpoint,会不断的recycle、rename老的WAL日志。
2021-08-05 19:28:43.593 CST,,,26383,,610bcb6b.670f,2,,2021-08-05 19:28:43 CST,,0,LOG,00000,"invalid checkpoint record",,,,,,,,,"","startup"
2021-08-05 19:28:43.593 CST,,,26383,,610bcb6b.670f,3,,2021-08-05 19:28:43 CST,,0,FATAL,XX000,"could not locate required checkpoint record",,"If you are restoring from a backup, touch ""/home/postgres/pgdata/recovery.signal"" and add required recovery options.
If you are not restoring from a backup, try removing the file ""/home/postgres/pgdata/backup_label"".
Be careful: removing ""/home/postgres/pgdata/backup_label"" will result in a corrupt cluster if restoring from a backup.",,,,,,,"","startup"
非排它备份
对于非排它模式,顾名思义,可以同一时间执行多个非排他模式的备份,不过不能在同一会话中执行多次非排它备份。对于非排它的备份,则不会在源目录中生成backup_label文件,这样就不会有前面排它模式备份的困扰了。
但是!非排它模式也有一个麻烦的问题,就是必须要保持会话不能断

所以对于非排它模式的备份,具体步骤是:
1.调用pg_start_backup2.执行cp、scp、rsync等命令进行备份3.调用pg_stop_backup4.将pg_stop_backup返回的内容手动写进backup_label文件中,放到备份文件中
可以看到,非排它的备份,需要我们自己手动创建一个backup_label文件,然后将pg_stop_backup返回的内容写进去,同时确保连接不能断!这是十分关键的一点。
备份工具
较为流行的的有pg_probackup和pg_backrest。
pg_probackup,pg_probackup is a utility to manage backup and recovery of PostgreSQL database clusters. It is designed to perform periodic backups of the PostgreSQL instance that enable you to restore the server in case of a failure.,pg_probackup有一个bug:假如我们修改了pg的segment size为10GB,也就是segment_size,因为pg_probackup的寻址范围最大支持4GB,也就意味着不管你什么文件备份下来最大只有4GB。
pg_backrest,pgBackRest aims to be a reliable, easy-to-use backup and restore solution that can seamlessly scale up to the largest databases and workloads by utilizing algorithms that are optimized for database-specific requirements.
barman,Barman (Backup and Recovery Manager) is an open-source administration tool for disaster recovery of PostgreSQL servers written in Python. It allows your organisation to perform remote backups of multiple servers in business critical environments to reduce risk and help DBAs during the recovery phase.
pg_rman,类似于Oracle的rman的工具,pg_rman is an online backup and restore tool for PostgreSQL.The goal of the pg_rman project is to provide a method for online backup and PITR that is as easy as pg_dump. Also, it maintains a backup catalog per database cluster. Users can maintain old backups including archive logs with one command.,pg_rman有一个很致命的缺点,不支持远程备份,也就意味着备份必须和数据节点跑在一起
还有一些其他的工具可以参考
•Barman - Backup and Recovery Manager for PostgreSQL by 2ndQuadrant.•OmniPITR - Advanced WAL File Management Tools for PostgreSQL.•pg_probackup – A fork of pg_arman, improved by @PostgresPro, supports incremental backups, backups from replica, multithreaded backup and restore, and anonymous backup without archive command.•pgBackRest - Reliable PostgreSQL Backup & Restore.•pg_back - pg_back is a simple backup script•pghoard - Backup and restore tool for cloud object stores (AWS S3, Azure, Google Cloud, OpenStack Swift).•wal-e - Simple Continuous Archiving for PostgreSQL to S3, Azure, or Swift by Heroku.•wal-g - The successor of WAL-E rewritten in Go. Currently supports cloud object storage services by AWS (S3), Google Cloud (GCS), Azure, as well as OpenStack Swift, MinIO, and file system storages. Supports block-level incremental backups, offloading backup tasks to a standby server, provides parallelization and throttling options. In addition to Postgres, WAL-G can be used for MySQL and MongoDB databases.•pitrery - pitrery is a set of Bash scripts to manage Point In Time Recovery (PITR) backups for PostgreSQL.
关于锁
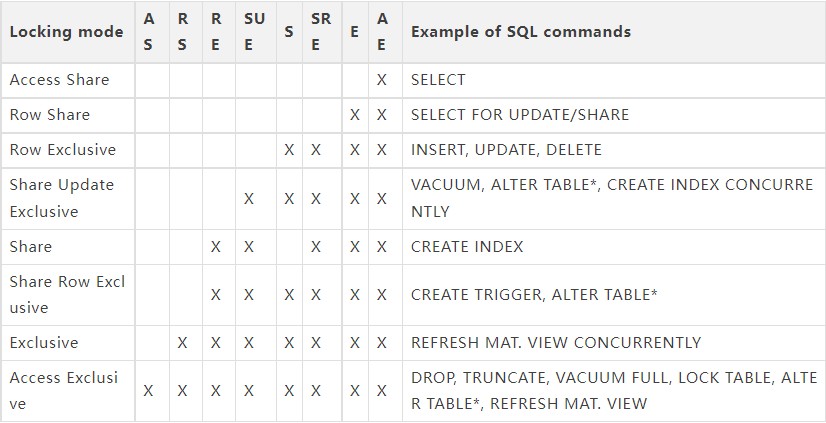
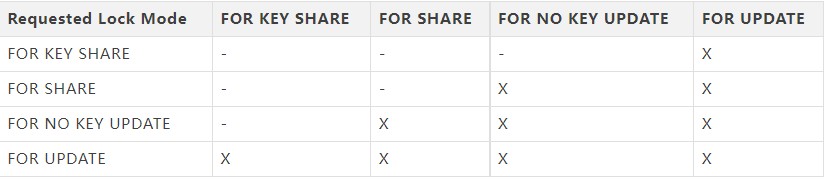
最为常见的就是表级锁和行级锁了,有些表级锁较难记忆,可以直接参照矩阵图。关于锁的详细总结可以参照之前的文章《一文搞懂PostgreSQL中的锁》。
另外还需要了解到的是,PostgreSQL对于锁也进行了大量的优化,比如缓存、主锁表、本地锁表等,还有Fast-path机制。为了避免所有的事务都去频繁访问pg_locks带来的性能影响,PostgreSQL还引入了Fast Path机制,对应pg_locks系统表里的fastpath字段。Access Share、Row Exclusive、Row Share这几个锁是互不冲突的,而且是数据库内绝大多数操作都是DML的操作,这几个锁可以被称之为"弱锁",而高于Row Exclusive的锁我们称之为"强锁",弱锁和弱锁互不冲突,这样我们就可以将弱锁保存到本地会话,避免频繁访问pg_locks,提升性能。
简而言之,Fast path用以减少那些需要经常获取和释放但又很少出现冲突的锁类型的获取/释放负载。另外每个进程还会维护一个本地的哈希表,用于记录一些已经存在的锁的信息,这样对于同一个进程来说,如果需要多次申请同一个锁,就无须再做冲突检测。
表级锁
行级锁
锁的查看
关于锁的查看,我们可以结合pg_locks、pg_stat_activity和pg_blocking_pids()进行查看。
postgres=# SELECT blocked_locks.pid AS blocked_pid,
blocked_activity.usename AS blocked_user,
blocking_locks.pid AS blocking_pid,
blocking_activity.usename AS blocking_user,
blocked_activity.query AS blocked_statement,
blocking_activity.query AS current_statement_in_blocking_process
FROM pg_catalog.pg_locks blocked_locks
JOIN pg_catalog.pg_stat_activity blocked_activity ON blocked_activity.pid = blocked_locks.pid
JOIN pg_catalog.pg_locks blocking_locks
ON blocking_locks.locktype = blocked_locks.locktype
AND blocking_locks.database IS NOT DISTINCT FROM blocked_locks.database
AND blocking_locks.relation IS NOT DISTINCT FROM blocked_locks.relation
AND blocking_locks.page IS NOT DISTINCT FROM blocked_locks.page
AND blocking_locks.tuple IS NOT DISTINCT FROM blocked_locks.tuple
AND blocking_locks.virtualxid IS NOT DISTINCT FROM blocked_locks.virtualxid
AND blocking_locks.transactionid IS NOT DISTINCT FROM blocked_locks.transactionid
AND blocking_locks.classid IS NOT DISTINCT FROM blocked_locks.classid
AND blocking_locks.objid IS NOT DISTINCT FROM blocked_locks.objid
AND blocking_locks.objsubid IS NOT DISTINCT FROM blocked_locks.objsubid
AND blocking_locks.pid != blocked_locks.pid
JOIN pg_catalog.pg_stat_activity blocking_activity ON blocking_activity.pid = blocking_locks.pid
WHERE NOT blocked_locks.granted;
blocked_pid | blocked_user | blocking_pid | blocking_user | blocked_statement |current_statement_in_blocking_process
-------------+--------------+--------------+---------------+-----------------+---------------
27592 | postgres | 27574 | postgres | update test_lock set id = 100 where id = 1; | update test_lock set id = 100 where id = 1;
with
t_wait as
(
select a.mode,a.locktype,a.database,a.relation,a.page,a.tuple,a.classid,a.granted,
a.objid,a.objsubid,a.pid,a.virtualtransaction,a.virtualxid,a.transactionid,a.fastpath,
b.state,b.query,b.xact_start,b.query_start,b.usename,b.datname,b.client_addr,b.client_port,b.application_name
from pg_locks a,pg_stat_activity b where a.pid=b.pid and not a.granted
),
t_run as
(
select a.mode,a.locktype,a.database,a.relation,a.page,a.tuple,a.classid,a.granted,
a.objid,a.objsubid,a.pid,a.virtualtransaction,a.virtualxid,a.transactionid,a.fastpath,
b.state,b.query,b.xact_start,b.query_start,b.usename,b.datname,b.client_addr,b.client_port,b.application_name
from pg_locks a,pg_stat_activity b where a.pid=b.pid and a.granted
),
t_overlap as
(
select r.* from t_wait w join t_run r on
(
r.locktype is not distinct from w.locktype and
r.database is not distinct from w.database and
r.relation is not distinct from w.relation and
r.page is not distinct from w.page and
r.tuple is not distinct from w.tuple and
r.virtualxid is not distinct from w.virtualxid and
r.transactionid is not distinct from w.transactionid and
r.classid is not distinct from w.classid and
r.objid is not distinct from w.objid and
r.objsubid is not distinct from w.objsubid and
r.pid <> w.pid
)
),
t_unionall as
(
select r.* from t_overlap r
union all
select w.* from t_wait w
)
select locktype,datname,relation::regclass,page,tuple,virtualxid,transactionid::text,classid::regclass,objid,objsubid,
string_agg(
'Pid: '||case when pid is null then 'NULL' else pid::text end||chr(10)||
'Lock_Granted: '||case when granted is null then 'NULL' else granted::text end||' , Mode: '||case when mode is null then 'NULL' else mode::text end||' , FastPath: '||case when fastpath is null then 'NULL' else fastpath::text end||' , VirtualTransaction: '||case when virtualtransaction is null then 'NULL' else virtualtransaction::text end||' , Session_State: '||case when state is null then 'NULL' else state::text end||chr(10)||
'Username: '||case when usename is null then 'NULL' else usename::text end||' , Database: '||case when datname is null then 'NULL' else datname::text end||' , Client_Addr: '||case when client_addr is null then 'NULL' else client_addr::text end||' , Client_Port: '||case when client_port is null then 'NULL' else client_port::text end||' , Application_Name: '||case when application_name is null then 'NULL' else application_name::text end||chr(10)||
'Xact_Start: '||case when xact_start is null then 'NULL' else xact_start::text end||' , Query_Start: '||case when query_start is null then 'NULL' else query_start::text end||' , Xact_Elapse: '||case when (now()-xact_start) is null then 'NULL' else (now()-xact_start)::text end||' , Query_Elapse: '||case when (now()-query_start) is null then 'NULL' else (now()-query_start)::text end||chr(10)||
'SQL (Current SQL in Transaction): '||chr(10)||
case when query is null then 'NULL' else query::text end,
chr(10)||'--------'||chr(10)
order by
( case mode
when 'INVALID' then 0
when 'AccessShareLock' then 1
when 'RowShareLock' then 2
when 'RowExclusiveLock' then 3
when 'ShareUpdateExclusiveLock' then 4
when 'ShareLock' then 5
when 'ShareRowExclusiveLock' then 6
when 'ExclusiveLock' then 7
when 'AccessExclusiveLock' then 8
else 0
end ) desc,
(case when granted then 0 else 1 end)
) as lock_conflict
from t_unionall
group by
locktype,datname,relation,page,tuple,virtualxid,transactionid::text,classid,objid,objsubid ;
关于流复制
常见的坑
流复制比较常见的坑是一主一从强同步的场景下,假如强同步的备机宕机了,主库是不能写入的,同步模式不会自动降级,需要依靠第三方工具进行判断和监控,或者使用一主多备quorum的方式来防止备库异常对主库的影响。openGauss中支持了最大可用模式,开启该参数后在主从连接正常的情况下处于同步模式,如果备机断连会立刻切为异步模式,如果备机再次启动会自动连接并切为同步模式。但这个设计其实有点奇怪,如果出现问题立即降级,那么与异步模式就没有区别了,当故障时主库降级了,这时再切换就会丢失数据了,这显然不是同步复制的初衷。如果允许丢数据,直接使用异步复制就可以了,如果需要不丢数据,使用同步模式,如果要坏一个备库也不让主库hang,那么就做两个备库的同步模式。
复制冲突
还有就是流复制的冲突,通常会将一些执行时间较长的分析任务、统计SQL跑在备库上。在备库上执行长时间的查询,由于涉及的记录有可能在主库上被更新或删除,主库上对更新或删除数据的老版本进行vacuum后,从库上也会执行这个操作,从而与从库上的当前查询产生冲突。除此之外,还有其他很多的冲突,常见的如下:
1.快照复制冲突:这是最常见的复制冲突。如果VACUUM处理一个表并且删除了死元组,可能会发生快照冲突。这一删除的动作也会在备用服务器上重放。备用服务器上的查询可能已经在主服务器上的VACUUM发生之前启动(它有一个较早的快照),因此它仍然可以看到应该删除的元组。这变会构成快照冲突。2.锁复制冲突:在备用服务器上,对正在执行查询的表上,获得了ACCESS EXCLUSIVE的排他锁。因此,必须在备用服务器上回放主服务器上的任何获取ACCESS EXCLUSIVE锁的操作(与ACCESS SHARE冲突),以防止发生表上不兼容的操作。PostgreSQL在诸如DROP TABLE,TRUNCATE和大多数ALTER TABLE等操作会获取与SELECT相冲突的锁,如果备用服务器在正在查询使用的表上回放这样的锁,就会发生锁冲突。3.Buffer pin replication conflicts:One way to reduce the need for VACUUM is to use HOT updates. Then any query on the primary that accesses a page with dead heap-only tuples and can get an exclusive lock on it will prune the HOT chains. PostgreSQL always holds such page locks for a short time, so there is no conflict with processing on the primary. There are other causes for page locks, but this is perhaps the most frequent one.When the standby server should replay such an exclusive page lock and a query is using the page (“has the page pinned” in PostgreSQL jargon), you get a buffer pin replication conflict. Pages can be pinned for a while, for example during a sequential scan of a table on the outer side of a nested loop join.HOT chain pruning can of course also lead to snapshot replication conflicts.
罕见的冲突如下:
1.死锁复制冲突:A query on the standby blocks while using the shared buffer that is needed to replay WAL from the primary. PostgreSQL will cancel such a query immediately.在备用数据库上的查询使用到了回放WAL所需的共享缓冲区。PostgreSQL将立即取消此类查询。2.表空间复制冲突:表空间位于备用服务器上的temp_tablespaces中,并且查询中具有临时文件。当主数据库出现DROP TABLESPACE时,会发生冲突。在这种情况下,PostgreSQL会取消备用数据库上的所有查询。3.数据库复制冲突:如果备用数据库在数据库上具有活动会话,则复制DROP DATABASE会导致冲突。在这种情况下,PostgreSQL会终止备用数据库上的的所有连接。
无法规避的冲突:VACUUM截断锁
当VACUUM完成对表的处理,并且表末尾的页面变为空时,它将尝试在表上获得一个简短的ACCESS EXCLUSIVE锁。如果成功,它将截断空白页并立即释放锁。尽管这样的锁不会扰乱主数据库上的处理,但会导致备用数据库上的复制冲突。从PostgreSQL v12开始,您可以针对单个表的禁用此功能ALTER TABLE some_table SET(vacuum_truncate = off);
高可用方案
参照李海龙在2020PostgreSQL大会上的分享
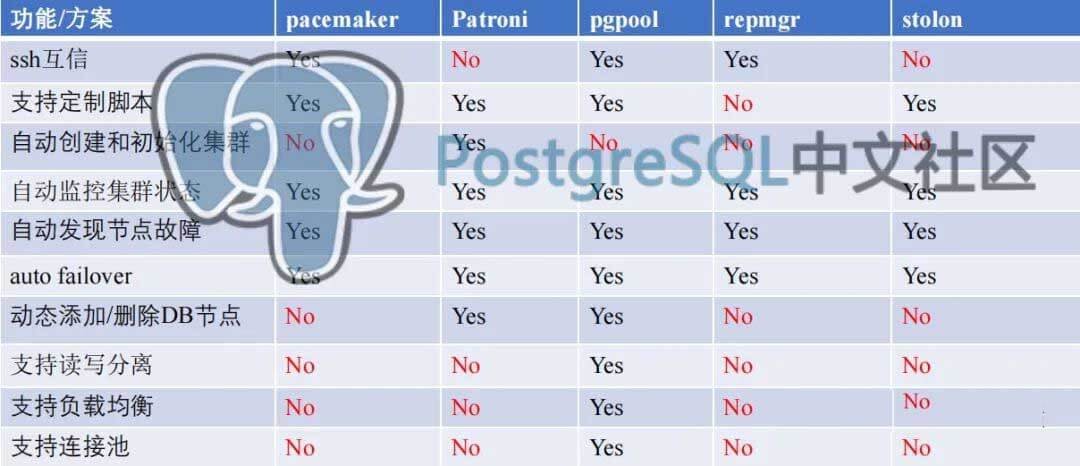
1.pg_keeper:仅用于将standby切换为master, 或者自动降级2.patroni:目前最为流行的方案,也是最强大的开源HA,依赖ETCD,在新版本中可以脱离ETCD,和新版本中的Kafka脱离Zookeeper类似,For HA you will have to run either three Patroni nodes or two nodes with Patroni and one node with patroni_raft_controller3.pgpool-II:支持读写分离、负载均衡、连接池等,是一套解决方案,不过较早之前的版本容易脑裂,配置繁琐4.stolon:Stolon是一个cloud native的PostgreSQL高可用管理工具。它之所以是cloud native的是因为它可以在为容器内部的PostgreSQL提供高可用(Kubernetes 集成),而且还支持其他种类的基础设施(比如:cloud IaaS,旧风格的基础设施等)5.repmgr:较为轻量,不依赖其他额外软件,节点信息内嵌在本地PostgreSQL库中6.pacemaker + corosync7.PAF( PostgreSQL Automatic Failover )8.EcoX:闭源,基于Zookpeer,强大的仲裁管理和自动化9.DRBD + LVM
关于逻辑复制
逻辑复制和流复制各自的应用领域不同:
1.流复制只能做到整个cluster的复制,逻辑复制则更加灵活,可以做到表级同步,另外cybertc提供了一个patial replication的插件walbouncer,可以对WAL日志进行过滤,允许进行部分数据库的复制,而不是整个实例:https://www.cybertec-postgresql.com/en/products/walbouncer-partial-replication/2.流复制的standby备库是只读的,不能写入,而逻辑复制读写都可以。3.逻辑复制支持在不同版本数据库之间进行逻辑复制,所以可以利用来进行跨版本升级。4.支持异构架构之前的同步,比如Linux -> Windows
复制冲突
因此备库可写,且本质上是回放的SQL,所以订阅端和发布端的表结构可以不一致,订阅端是发布端的超集且二进制兼容即可,因此会带来一系列的冲突,有些冲突需要手动处理,有些PostgreSQL会帮着处理
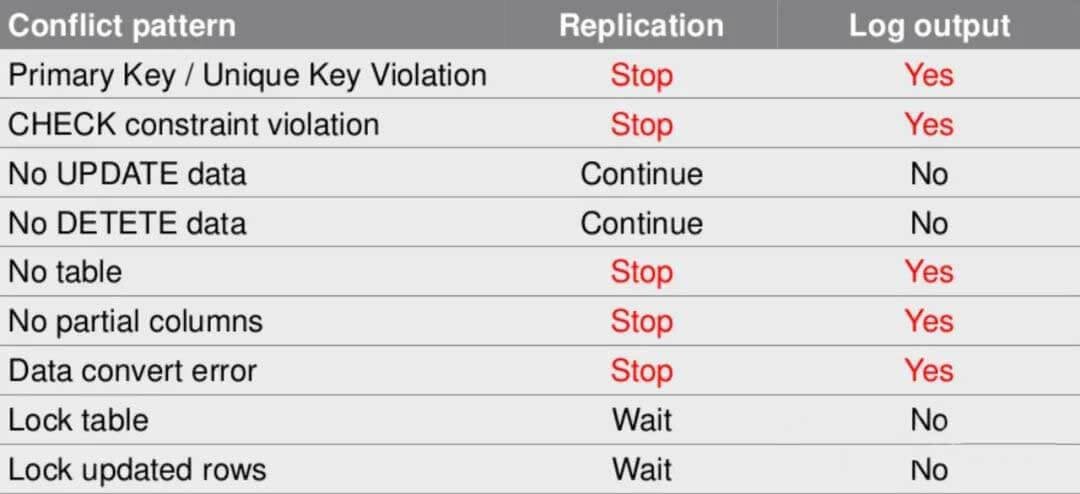
双向复制
互为发布与订阅是可行的,但前提是两边的表集合不相交即可。但一旦出现表的交集,就会出现WAL无限循环,直到将数据库搞死。
另外对于同一个实例的发布订阅,需要注意的一点是,复制槽需要手动创建,不然会卡住。
限制项
1.schema和DDL不会被同步,truncate是可以同步的,所以需要在订阅端创建表,包含要同步的字段。不过我们可以使用插件pgl_ddl_deploy或者pglogical实现DDL的同步,也可以使用触发器的方式记录在某个表中,然后发给订阅端。建议先在订阅端执行DDL
2.truncate的时候,需要注意订阅端是否有依赖关系,比如外键,如果有一些不在订阅集中的表通过外键引用订阅集中被TRUNCATE的表,那么TRUNCATE操作就会失败。
3.序列也不会被同步,它是直接复制的SQL语句,并没有真正的在订阅侧再次调用序列,如果订阅者被当成只读库使用,那么通常没事。然而如果打算进行某种形式的切换或Failover到订阅者数据库,那么需要将序列号更新为最新的值,要么通过从发布者复制当前数据(也许可以使用pg_dump -t *seq*),要么从表本身的数据内容确定一个足够高的值(例如max(id)+1000000)。否则如果在新库执行获取序列号作为身份的操作时,很可能会产生冲突。
4.对于INSERT ... ON CONFLICT,发布端将发布该命令实际产生的操作。因此,根据结果,它可能会发布为INSERT或UPDATE,也可能根本不发布。
5.大对象、物化视图、外部表、索引、unlogged table等都不会被同步,只会发布表,包括分区表,默认情况下,变更是按照分区表的叶子分区触发的,这意味着发布上的每一个分区子表都需要在订阅上存在(当然,订阅者上的这个分区子表不一定是一个分区子表,也可能本身就是一个分区母表,或者一个普通表)。发布可以声明要不要使用分区根表上的复制标识取代分区叶表上的复制标识,这是13提供的新功能,可以在创建发布时通过publish_via_partition_root 选项指定。
6.对于以前的版本,假如遇到大事务,延迟会很大,因为只有在提交时,所有更改才会同时发送到下游。对于大型事务,进行网络传输的时间可能很长,这将导致应用延迟。在PostgreSQL v14版本里,对于长事务逻辑复制进行了优化,增加了streaming接口,逻辑复制支持流式decoder和发送,无需等待事务结束,大幅度降低大事务、长事务的复制延迟。同时对预备事务也进行了支持7.要让触发器能正常工作,我们还需要设置ALTER TABLE ENABLE ALWAYS 或者REPLICA TRIGGER语句。也就是ENABLE REPLICA TRIGGER trigger_name。另外只有FOR EACH ROW触发器能执行,而FOR EACH STATEMENT则只会在初始化数据的时候执行。8.逻辑复制不能在standby实例上创建,因为standby是只读的,不能创建逻辑复制插槽,因此逻辑解码插件也无法在standby实例上执行。9.COPY ... FROM commands are published as INSERT operations.
关于数据库年龄
这个可以参考我之前的文章《深入理解PostgreSQL的冻结炸弹》,主要是PostgreSQL的实现方式,为了保证MVCC的一致性,得不断做Freeze的维护操作。关于数据库连接遇到过两个生产BUG
BUG I
在实际生产中碰到一次,10.2的库,vacuum freeze报错:
postgres=> vacuum freeze pg_catalog.pg_authid; ERROR: found xmin 2088747257from before relfrozenxid 2810153180
10.2、9.6.7、9.5.11、9.4.16以后到修复版本之间的版本的都会存在相关问题。
10.5、9.6.10、9.5.14、9.4.19 对这个问题进行了修复。
bugfix patch如下:
https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=817f9f9a8a1932a0cd8c6bc5c9d3e77f6a80e659
可以通过以下任意方式进行修复:
1.重启数据库,重启后会重新读入新数据内容到relcache中,相当于刷新relcache。2.删除global目录下的pg_internal.init,这个文件就是存储的relcache的内容,有新的连接连入会创建新的pg_internal.init文件
问题的根因就是 vacuum 是读到的 relfrozexid 来自 relcache 的,更新 catalog 中的 relfrozexid 不会去刷新 relcache, 导致一直读到的是错误的 relfrozexid, 所以出现 vacuum freeze 报错的问题。
BUG II
删除表的时候报错
ERROR: uncommitted xmin 393410960from before xid cutoff 393413059 needs to be frozen代码逻辑
if (TransactionIdPrecedes(xid, cutoff_xid))
{
if (!TransactionIdDidCommit(xid))
ereport(ERROR,
(errcode(ERRCODE_DATA_CORRUPTED),
errmsg_internal("uncommitted xmin %u from before xid cutoff %u needs to be frozen",
xid, cutoff_xid)));
frz->t_infomask |= HEAP_XMIN_FROZEN;
changed = true;
xmin_frozen = true;
}
原因要么是infomask标志位错了,要么是CLOG错了。实际生产中碰到过一次,去库里看txid_status显示是abort的,但是根据xmin去查表,却查了出来,abort是不可见的,需要手动删除有问题的数据行
关于MVCC
MVCC的实现方式就不再阐述,PostgreSQL独特的实现方式会带来表膨胀的危害,到达某一个点后,需要执行一个高额代价的vacuum full(或者cluster等可以重组表的命令),但vacuum full又是AccessExclusiveLock,8级锁,会阻塞一切访问,意味着在完成清理重组之前,都无法访问该表。可以参照我之前的文章《揭开表膨胀的神秘面纱》
pg_repack
为此我们可以使用pg_repack进行重组,不过pg_repack也有自己的问题
1.pg_repack 需要多次获取重量级的 AccessExclusive 锁,不过是短暂性的。2.在高并发的情况下,几乎不可能拿到AccessExclusive锁。3.如果 pg_repack 在 wait-time 期间无法获得 AcessExclusive 锁,默认情况下,它会尝试杀掉冲突的语句4.如果总等待时间超过 wait-time 的两倍,它可能会杀掉会话。这可能会导致不良的结果和意外中断。5.pg_repack 的默认值可能不适用于关键系统。使用 --no-kill-backend 选项使其更加温和。6.不允许针对正在进行 pg_repack 的表使用 DDL,任何尝试这样做的会话都可能会被杀掉。7.重整开始之前,最好取消掉所有正在进行的Vacuum任务。8.对索引做重整之前,最好能手动清理掉可能正在使用该索引的查询9.如果出现异常的情况(譬如中途强制退出),有可能会留下未清理的垃圾,需要手工清理。10.当完成重整,进行重命名替换时,会产生巨量的WAL,有可能会导致复制延迟,而且无法取消。11.重整特别大的表时,需要预留至少与该表及其索引相同大小的磁盘空间,需要特别小心,手动检查。12.如果遇到写入速度非常快的,最后阶段reply log的时候,干瞪眼
关于插件
目前PostgreSQL还没有官方的插件市场,所以
•第三方插件的质量、功能或BUG修复速度都难以保证•插件没有公共的或官方的商业化平台、市场规模难以搞大
插件的种类是十分之多的。虽然通过插件,可以不断完善PostgreSQL的功能,但是插件,相对是个黑盒,势必也会引入一些新的问题,所以在引入一款插件之前,足够的调研和实验是必须的。
pg_show_plans
pg_show_plans我之前曾提过一个BUG,后面修复了,之前的版本会导致事务ID消耗迅速(只读查询也会消耗永久事务ID),导致年龄很快就达到了阈值,后来作者进行了修复。也就是Suzuki大师 ~ 可以参照我之前的两篇文章
另外对于逻辑复制与CDC的场景,pg_show_plans会和逻辑复制槽有冲突,需要手动临时规避:
postgres=# SELECT pg_create_logical_replication_slot('myslot', 'pgoutput');
ERROR: cannot create logical replication slot in transaction that has performed writes
postgres=# SELECT pg_create_logical_replication_slot('myslot', 'wal2json');
ERROR: cannot create logical replication slot in transaction that has performed writes
postgres=# SELECT pg_create_logical_replication_slot('myslot', 'wal2mongo');
ERROR: cannot create logical replication slot in transaction that has performed writes
postgres=# set pg_show_plans.enable = off;
SET
postgres=# SELECT pg_create_logical_replication_slot('myslot', 'pgoutput');
pg_create_logical_replication_slot
------------------------------------
(myslot,0/1572F90)
(1 row)
postgres=# SET pg_show_plans.enable = on;
SET
pg_pathman
社区核心成员之一oleg所在的公司postgrespro,开发了一款分区表功能的插件,不需要动用catalog,可以很方便的增加分区表的功能。pg_pathman 是一个 PostgreSQL 高性能表分区插件。可通过内建函数挂载、摘除和分区。直到v12,原生分区表的性能才得到大幅度提升,可以与pg_pathman持平,PG12内存使用量降低、plan更快、TPS更快,对于以前的版本建议使用pg_pathman。
pg_pathman与传统的继承分区表做法有一个不同的地方,分区的定义存放在一张元数据表中,表的信息会cache在内存中,同时使用HOOK来实现RELATION的替换,所以效率非常高。要注意可能的问题:pg_pathman进程初始化时会加载所有pathman分区表配置信息到该进程私有内存空间,分区数量越多,进程的私有内存越大。不过随着原生分区表功能的不断增强,pg_pathman可能不再维护了。
pg_pathman应该笔者遇到BUG最多的插件之一,参照如下:
1.pg_pathman的range分区,已知在筛选条件中如果对于分区字段右值套用了函数表达式,或者类型转换函数to_date(),to_timestamp()等,那么不会筛选出对应的分区表,会扫描所有的分区表;但是支持::date或者::timestamp这种类型转换,就可以走分区裁剪,可以参考:《PostgreSQL运维案例--记使用pg_pathman的range分区踩到的坑》2.约束名过长63字符,导致查询报错,参考:《Pathman的一个小案例》3.ERROR:unrecognized node type: 211,和auto_explain插件冲突,某些情况下也会触发4.之前的记录《不同用户的执行计划居然会不一样?》 ——原生分区表5.heal segfault introduced in 11.7 and 12.2,使用的版本是11.7到12.2之前的版本,会出现段错误,append_rel_array动态申请空间的操作存在野指针,pg_pathman需要升级至1.5.11,详见 https://github.com/postgrespro/pg_pathman/releases/tag/1.5.11
pg_stat_monitor
这款插件是由 Percona 维护的一个独立开源项目,https://github.com/percona/pg_stat_monitor#setup,pg_stat_monitor提供了类似AWR的定期采集的功能,同时还可以观察执行计划、消耗多少CPU、SQL的直方图、简易审计等等,同时还可以看到具体的参数值,不再是$1 $2这种占位符了。相较pg_stat_kcache和pg_stat_statements的功能要多很多。
不过实测对性能影响较大,吞吐量只有未安装时的30%左右。
关于统计信息
PostgreSQL对于单列选择性的估算比较准确,而对于多列的情况则会出现不准确的情况,因为PostgreSQL默认使用独立属性,直接以多个字段选择性相乘的方法计算多个字段条件的选择性。为此我们可以使用create statistics的方式,告诉PostgreSQL多列之间的关系。
另外可以提升default_statistics_target,会让规划器做出更准确的估计(特别是对那些有不规则数据分布的列), 其代价是在pg_statistic中消耗了更多空间,并且需要略微多一些的时间来计算估计数值。
另外探探的KEN师傅也发过一篇有趣的优化Case,数据不均匀带来的执行计划偏差《一个有趣的SQL优化案例》
这里推荐几个可视化工具:
https://explain.depesz.com/
https://explain.dalibo.com/plan#
https://tatiyants.com/pev/#/plans/new
关于2PC
当然了,之前也有写,这里简单提及一下
1.2pc一定要及时commit或者回滚,危害很多,表膨胀、持锁、年龄回收等,并且在pg_stat_activity里面的表象是pid = 0,十分具有迷惑性2.基于流复制的备库,2PC事务也会复制过去3.生产中,结合pg_prepared_xacts定制监控,对于长时间不提交的prepared transaction,及时告警。
关于权限
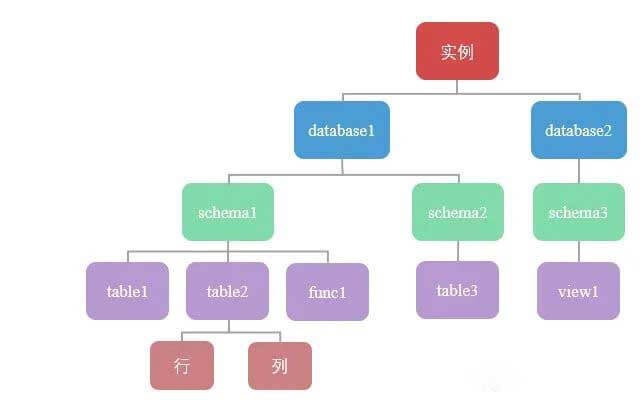
PostgreSQL里面的权限有点"复杂",不同于MySQL,PostgreSQL是不能直接跨Database查询的。
每个实例下允许创建多个数据库(database),每个数据库下允许创建多个模式(schema),每个模式下允许创建多个对象,比如表、函数、视图、索引等,每个表又可以依据行和列两个维度进行衡量,从而形成如下的逻辑
依据上述逻辑分布构建如下图所示的权限体系,每一层都有自己的权限控制。
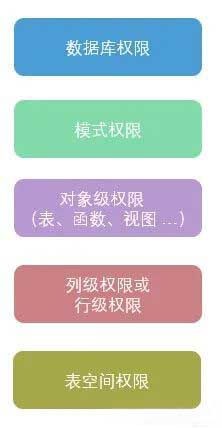
比如用户想要成功查看数据表某一行的数据,那么他需要具备能够登录数据库(LOGIN)这一系统权限,表所在数据库的连接权限(CONNECT),表所在模式的使用权限(USAGE)和数据表本身的查看权限(SELECT),同时还要满足对这一行数据的行级访问控制条件(row level security)。
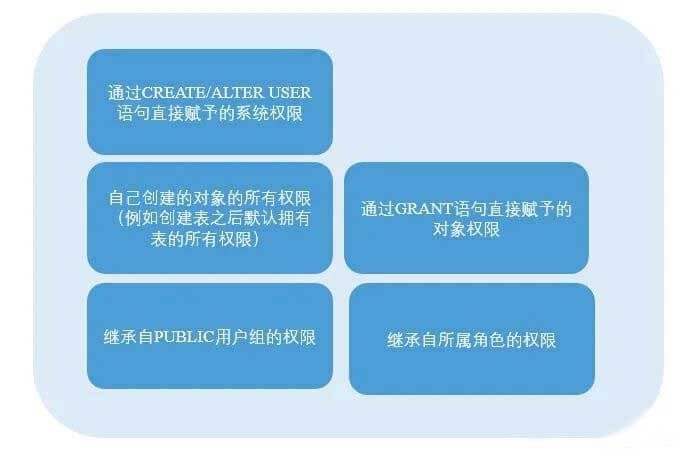
一个用户拥有的权限是如下的并集
关于误删数据
另外一个常见的问题是,数据误删了我该怎么搞?其实在PostgreSQL中,还是有很多方法可以抢救的。本质上都是基于MVCC的方式来实现的,这里就不再赘述,感兴趣的读者找一下之前的文章。
关于分布式数据库
总的来说,分布式数据库大多可以分为两种架构风格,一种是 NewSQL,它的代表系统是 Google Spanner,Spanner 论文发表后,开始涌现出许多优秀的开源分布式数据库,其中具有代表性的有:CockroachDB、TiDB、YugabyteDB 和最近开源的 OceanBase 等等。另一种是从单体数据库中间件基础上演进出来的,被称为 Prxoy 风格,比较典型的便是PostgreSQL-XC,基于PGXC系列的有很多,TBase、AntDB、Gbase8s、Guass200/300等。
Google 的分布式数据库 Spanner 论文中有一句话我觉得十分经典:
We believe it is better to have application programmers deal with performance problems due to overuse of transactions as bottlenecks arise, rather than always coding around the lack of transactions.
分布式数据库不是银弹,绝大多数场景下的的数据量和负载水平,单机PostgreSQL完全足以。
TiDB
TiDB是一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP)的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。目标是为用户提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解决方案。TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。在墨天轮的排行榜上,牢牢占据第一位。
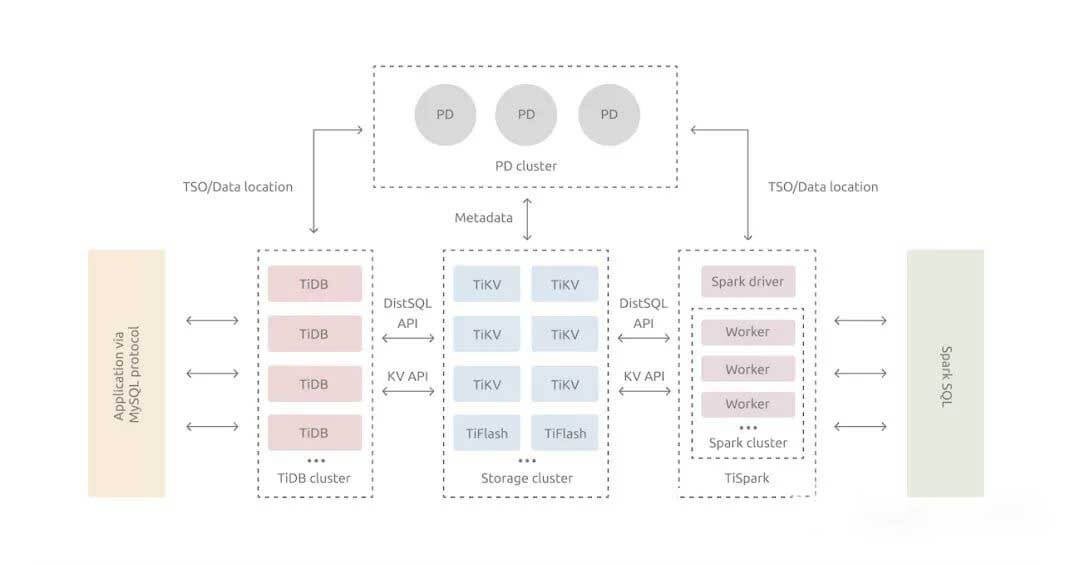
TIDB 采用分层架构,有三种角色:
•TIDB:作为 SQL 引擎。•TiKV:作为底层分布式键值存储。•PD:承担元数据管理和全局时钟的职责。
TiDB 的衍生项目:
•Ti-Binlog、Ti-CDC 支持数据导出。•Ti-Operator 更方便地实现容器云部署。•Chaos Mesh 支持混沌工程。
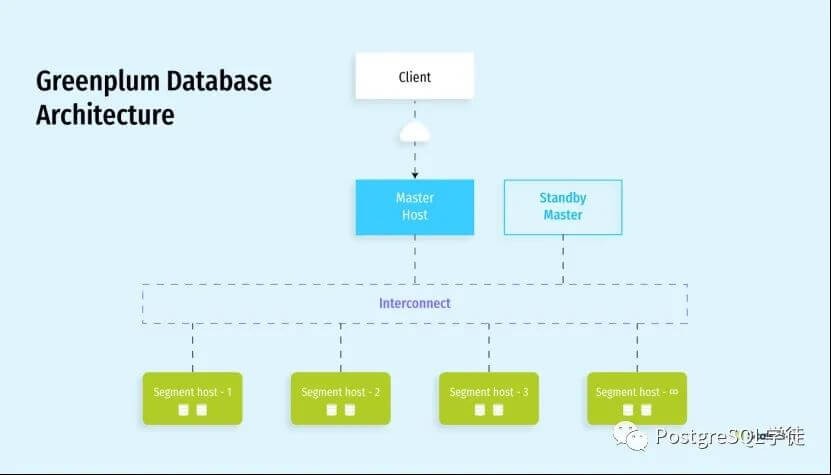
Greenplum
Greenplum最早是在大约在2002年左右出现的,基本上和Hadoop是同一时期。从用户角度来看,Greenplum是一个完备的关系数据库管理系统(RDBMS)。从物理层面,它内含多个 PostgreSQL 实例,这些实例可以单独访问。为了实现多个独立的 PostgreSQL实例的分工和合作,呈现给用户一个逻辑的数据库,Greenplum 在不同层面对数据存储、计算、通信和管理进行了分布式集群化处理。Greenplum 虽然是一个集群,然而对用户而言,它封装了所有分布式的细节,为用户提供了单个逻辑数据库。这种封装极大的解放了开发人员和运维人员。Greenplum6已经将内核升级到了9.6,Greenplum7会将内核升级到12,大大提升TP能力,称为一款HTAP(Hybrid Transaction and Analytical Process)的数据库。以下简称为GPDB。
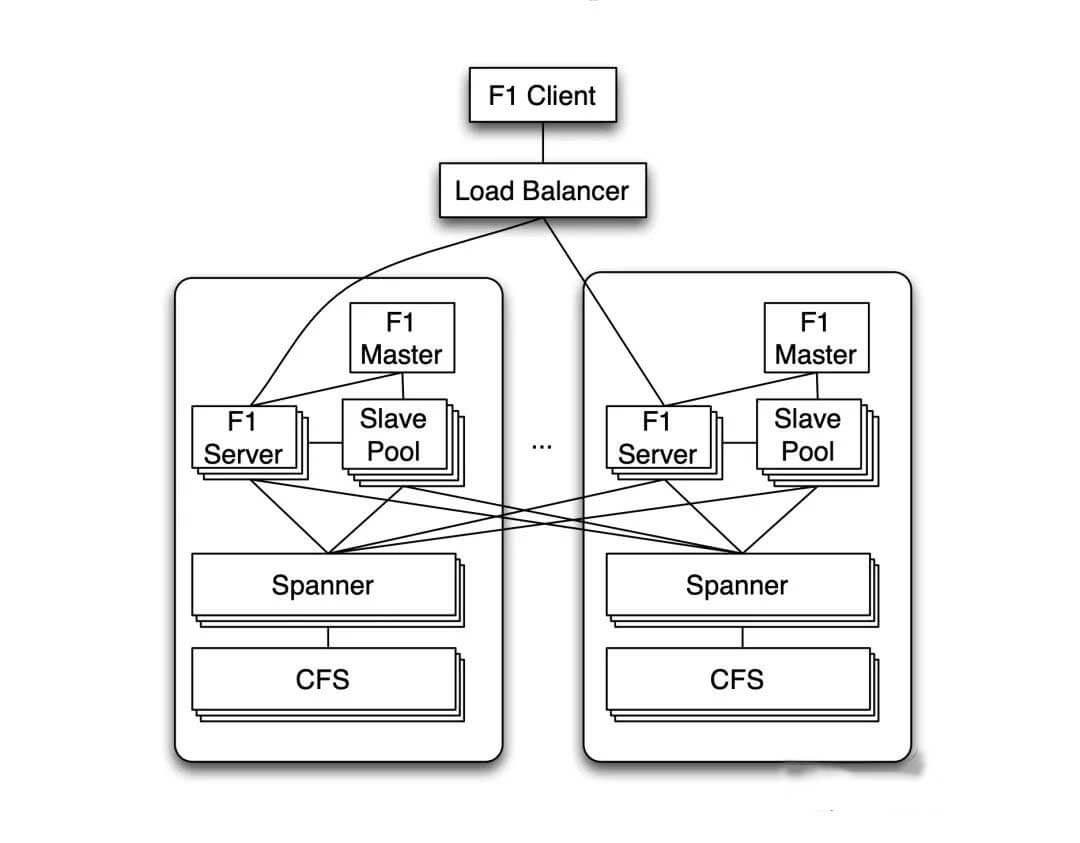
Google Spanner
Spanner是谷歌公司研发的、可扩展的、多版本、全球分布式、同步复制数据库。它支持外部一致性的分布式事务。F1 主要作为 SQL 引擎,Spanner 主要负责事务一致性、复制机制、可扩展存储等。
CockroachDB
CockroachDB 是一个分布式的K/V数据仓库,支持ACID事务,多版本值存储是其首要特性。主要的设计目标是全球一致性和可靠性,从蟑螂的命名上是就能看出这点。蟑螂数据库能处理磁盘、物理机器、机架甚至数据中心失效情况下最小延迟的服务中断;整个失效过程无需人工干预。蟑螂的节点是均衡的,其设计目标是同质部署(只有一个二进制包)且最小配置。
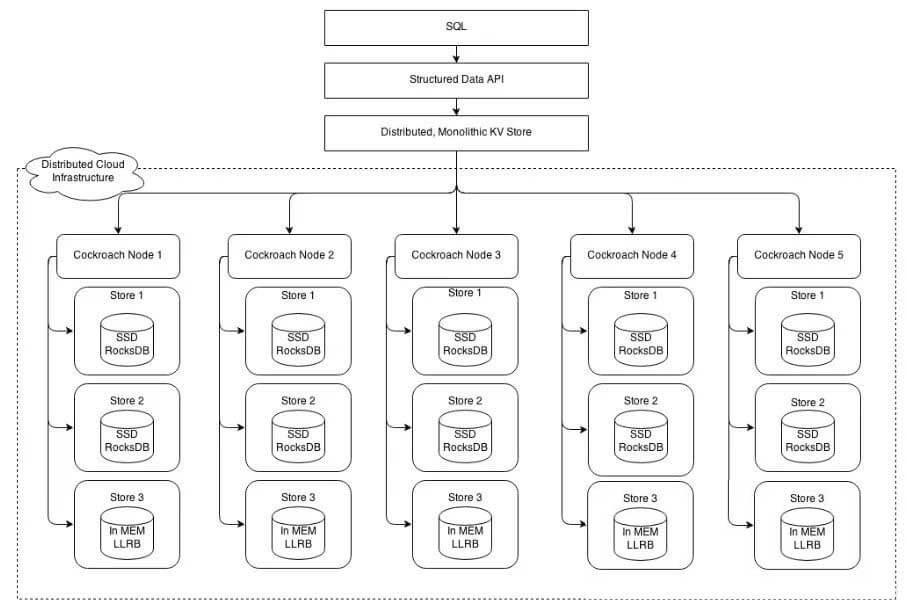
CockroachDB 和 TiDB、YugabyteDB 都公开声称设计灵感来自 Spanner,所以往往会被认为是同构的产品。
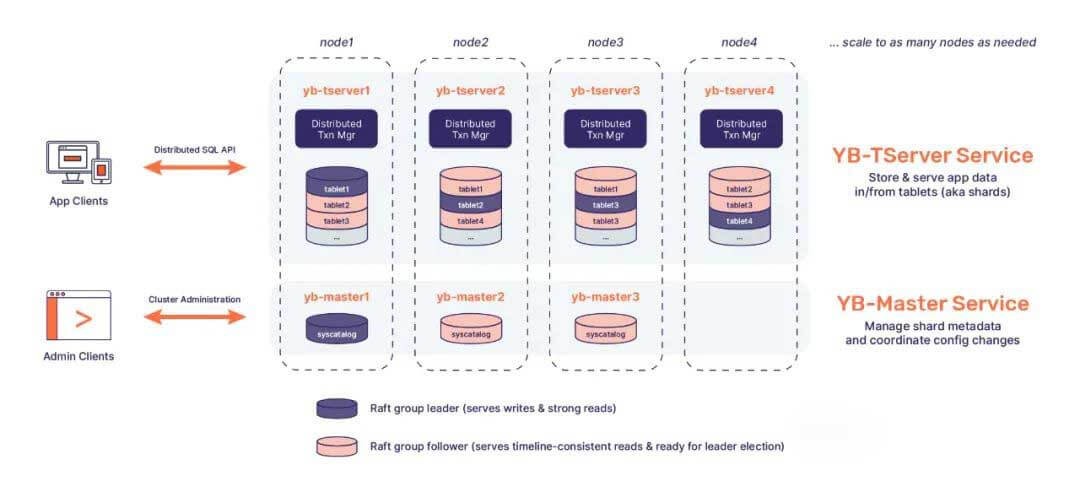
YugabyteDB
YugabyteDB是一个高性能、云原生的分布式SQL数据库,在架构上和 CockroachDB 有很多相似之处,比如支持全球化部署,采用混合逻辑时钟(HLC),基于 Percolator 的事务模型,兼容 PostgreSQL 协议。
YugabyteDB最适合云原生的OLTP应用(实时性、企业级业务),这些应用需要绝对的数据库一致性并且至少需要如下特性中的一点:可扩展性、高容错性或全局分布式部署。在国内,据笔者所知,MemfireDB是基于YugabyteDB做的。
Citus
Citus是一款基于PostgreSQL的开源分布式数据库,自动继承了PostgreSQL强大的SQL支持能力和应用生态,和其他类似的基于PostgreSQL的分布式方案,比如GreenPlum,PostgreSQL-XL相比,Citus最大的不同在于Citus仅仅是一个PostgreSQL扩展而不是一个独立的代码分支。因此,Citus可以用很小的代价和更快的速度紧跟PostgreSQL的版本演进,同时又能最大程度的保证数据库的稳定性和兼容性。Citus在苏宁有大规模的应用。
小结
以上种种便是运维PostgreSQL的过程中经常会碰到的问题了,祝各位消化吸收,从小工到大工,人人都是极客。
- 发表于 2022-04-26 18:58
- 阅读 ( 145 )
