Pgbouncer最佳实践
Pgbouncer最佳实践:系列一
PgBouncer作为PostgreSQL数据库的连接池中间件。与其他存在于PostgreSQL的连接池中间件不同,PgBouncer仅作为一个连接池和代理层为PostgreSQL和应用之间提供服务。
Pgbouncer具备例如连接池模式、连接类型、端口重用,应用场景以及用户认证、网络认证等多种重要特性,下面将逐一讲述,并期望为读者提供一份在实施过程中使用的配置指南。
数据库连接池在Pgbouncer中包括会话连接池、事务连接池、语句连接池三种方式。
1、会话连接池
官方解释为最有礼貌的方法。当客户端连接时,服务器连接将在其保持连接的整个过程中分配给它。当客户端断开连接时,服务器连接将重新放入池中。此模式支持所有PostgeSQL功能。
2、事务连接池
服务器连接仅在事务期间分配给客户端。当PgBouncer发现事务已结束时,服务器连接将被放回池中。该模式破坏了PostgreSQL的一些基于会话的功能。仅当应用程序通过协作使用不中断功能时,才可以使用它。有关不兼容的功能。
3、语句连接池
官方解释为最激进的方法。不允许多语句事务。本质上为了在客户端上强制执行“自动提交”模式,主要针对PL/Proxy。
另外支持其他特性包括:
- 高性能,因为Pgbouncer自身不需要查看整个数据包,所以在网络开销上仅为2k(默认情况),对系统的内存要求小。
- 部署灵活:Pgbouncer没有绑定到一台后端服务器。目标数据库可以驻留在不同的主机上。
- 可维护性强:支持大多数配置项的的在线重新配置;并且支持在线重启/升级,而不会断开客户端连接。
- 认证灵活:用户认证支持基于文件的验证方式外,还提供了数据库查询验证;网络连接认证与Postgresql数据库一致,支持多种模式验证。
- 灵活连接数:支持全局、数据库、用户和客户端连接数组合形式设置。
(注:文中未详细描述部分,请参见Pgbouncer[1]的官网相关文档,如配置手册、使用手册、FAQ等官方文档)
前面大致介绍了Pgbouncer的一些特性,详细特性请查阅(Pgbouncer官网),下面将针对使用Pgbouncer时的一些配置注意事项进行说明,为Pgbouncer的使用用户提供一个指引,满足复杂业务需求情况下充分利用Pgbouncer的特性来实现特定业务场景需求。
在对Pgbouncer进行配置的过程中,需要特别关注连接池模式外,还需要明确数据连接数、连接方式,最后则是针对不同业务场景的Pgbouncer部署形式。
首先讨论一下为什么使用连接池[2],使用与不使用之间的性能差异,另外讨论连接池模式的工作流程、细节及一些注意事项进行阐述,最后提供一个适合的连接池建议。
在我们进行Postgresql入门的时候,通常会看到这段介绍“PostgreSQL服务器可以处理来自客户端的多个并发连接。为此,它为每个连接启动(“fork”)新进程,从那时起,客户端和新的服务器进程进行通信,而无需原始postgres进程进行干预。因此,主服务器进程始终在运行,等待客户端连接,而客户端及关联的服务器进程来来往往。”但是,这意味着每个新连接都会分叉一个新进程,保留在内存中,并可能在多个会话中变得过分繁忙。在业务量较小的情况下,这种方式基本可以满足要求,但是当业务量迅速激增,我们可能就需要不断去更改max_connections来满足客户端的需求。当时同样也带来了很大的问题,如频繁的关闭和创建连接造成的内存开销,管理已产生的大量连接等等,最终导致服务器响应缓慢而无法对外提供数据库服务。在这样一个背景下,数据库连接池就被提出来了,对于使用Postgresql数据库来说,一般分为客户端连接池,比如c3p0、druid等等;另外一种则是服务器端连接池,例如pgbouncer、odyssey、pgpoolII等。
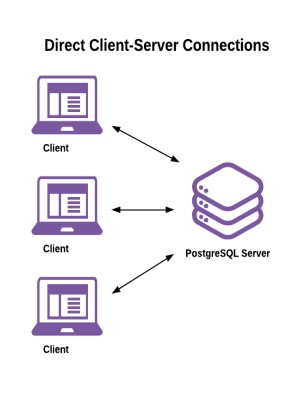
图 1 直连数据库服务器
这是没有连接池的PostgreSQL连接生命周期:
1.客户端通过请求并验证与服务器的连接来开始新会话。
2.服务器fork一个新的系统进程来处理连接和工作会话。会话状态是通过服务器级,数据库级和用户级配置参数的组合进行初始化的。
3.客户通过执行一个或多个事务来完成所需的工作。示例包括:
- 针对关系(表,视图等)执行读写
- 使用SET命令更改会话或事务状态
- 准备并执行预编译语句
4.当客户端断开连接时,会话结束。
5.服务器销毁会话进程。
一个数据库会话包括所有通过单一连接的生命周期所做的工作。数据库会话的时间长度是可变的,并且在客户端和服务器上消耗的资源数量是可变的。
关键点在于:
- 创建,管理和销毁连接过程会花费时间并消耗资源。
- 随着服务器的连接数增加,管理这些连接所需的资源也随之增加。此外,随着客户端在服务器上进行处理,服务器的每个进程内存使用量将继续增长。
- 由于单个会话仅服务于单个客户端,因此客户端可以更改数据库会话的状态,并希望这些更改在后续的事务中继续存在。
一个的连接池位于客户端和服务器之间。客户端连接到池管理器,而池管理器连接到服务器。引入连接池程序会将连接模型更改为客户端代理服务器架构:
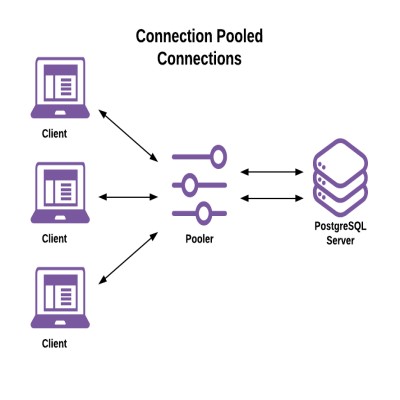
图 2 使用连接池连接数据库
这使客户端连接生存期与服务器连接和进程生存期脱钩。连接池的作用:
- 接受和管理来自客户端的连接
- 建立和维护与服务器的连接
- 将服务器连接分配给客户端连接
特点:
- 单个服务器连接可处理来自不同客户端的会话,事务和语句
- 单个客户端会话的事务和/或语句可在不同的服务器连接上运行
显而易见使用连接池能够降低服务器的内存开销,并且有效复用数据库连接,提供了良好的数据库连接性能管理。
Pgbouncer最佳实践:系列二
连接池选择必须有测试数据作为支撑,才能更好来决定如何选择。通过下面的测试结果,能够更加直观的看到两者之间的差异(相关数据及测试结果来源自Percona[3]):
一般来说,PostgreSQL通过将它的主要操作系统进程“分叉”到每个新连接的子进程中来实现连接处理。在操作系统级别上获得了PostgreSQL中每个连接的资源利用率的完整视图(以下输出来自top命令):
表 1 直连内存占用情况
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 24379 postgres 20 0 346m 148m 122m R 61.7 7.4 0:46.36 postgres: sysbench sysbench ::1(40120) 24381 postgres 20 0 346m 143m 119m R 62.7 7.1 0:46.14 postgres: sysbench sysbench ::1(40124) 24380 postgres 20 0 338m 137m 121m R 57.7 6.8 0:46.04 postgres: sysbench sysbench ::1(40122) 24382 postgres 20 0 338m 129m 115m R 57.4 6.5 0:46.09 postgres: sysbench sysbench ::1(40126)
首先,在时间和内存方面,分叉一个操作系统进程要比为一个现有进程生成一个新线程要昂贵得多。随着时间的推移,考虑变得越来越重要。这可能是为什么在基于PostgreSQL的应用程序的扩展生命周期中早期就需要连接池机制的原因之一。
为了说明连接池可能对PostgreSQL服务器的性能产生的影响,利用在sysbench-tpcc上对PostgreSQL进行的测试,并通过使用PgBouncer作为连接池来部分重复了这些测试。
当第一次运行测试时,目标是针对PostgreSQL的sysbench-tpcc工作负载优化PostgreSQL,该工作负载运行56个并发客户端(线程),并且服务器具有相同数量的可用CPU,运行时间定为30分钟。这次的目标是更改并发客户端的数量(56、150、300和600),以查看服务器如何应对连接的扩展。
使用事务池进行测试,因为sysbench-tpcc的工作量由几个短语句和单语句事务组成。下表为完整使用的配置文件,命名为pgbouncer.ini:
表 2 pgbouncer.ini文件
[databases] sbtest = host=127.0.0.1 port=5432 dbname=sbtest [pgbouncer] listen_port = 6543 listen_addr = 127.0.0.1 auth_type = md5 auth_file = userslist.txt logfile = pgbouncer.log pidfile = pgbouncer.pid admin_users = postgres pool_mode = transaction default_pool_size=56 max_client_conn=600
除了pool_mode以外,其他最重要的变量是:
- default_pool_size:每个用户/数据库对允许多少个服务器连接。
- max_client_conn:允许的最大客户端连接数
userslist.txt通过指定文件AUTH_FILE只包含用于连接到PostgreSQL的用户和口令的信息;该文件中的密码可以是纯文本密码,也可以是使用MD5或SCRAM加密的密码,具体取决于要使用的身份验证方法。
定义用户的另一种方法是让PgBouncer在需要时直接查询PostgreSQL后端。这是通过配置参数设置的auth_user,可以在全局或每个数据库中设置。设置此选项后,PgBouncer使用该用户连接到PostgreSQL后端,并运行该设置定义的查询auth_query以查找用户和密码。如果auth_user本身需要用于该连接的密码,则需要在user.txt中进行设置。关于相关细节请参见Pgbouncer官网。
使用以下命令将PgBouncer作为守护程序启动:
$pgbouncer -d pgbouncer.ini
除了仅运行基准测试30分钟并每次更改并发线程数之外,线程数=56。下面的示例来自第一次运行:
$ ./tpcc.lua --pgsql-user=postgres --pgsql-db=sbtest --time=1800 --threads=56 --report-interval=1 --tables=10 --scale=100 --use_fk=0 --trx_level=RC --pgsql-password=****** --db-driver=pgsql run > /var/lib/postgresql/Nando/56t.txt
对于使用连接池的测试,调整连接选项,以便与PgBouncer而不是PostgreSQL直接连接。请注意,它仍然是本地连接:
./tpcc.lua --pgsql-user=postgres --pgsql-db=sbtest --time=1800 --threads=56 --report-interval=1 --tables=10 --scale=100 --use_fk=0 --trx_level=RC --pgsql-password=****** --pgsql-port=6543 --db-driver=pgsql run > /var/lib/postgresql/Nando/P056t.txt
每次执行sysbench-tpcc之后,使用以下命令清除操作系统缓存:
$ sudo sh -c 'echo 3 >/proc/sys/vm/drop_caches'
在default_pool_size=56的情况下,结果如下:
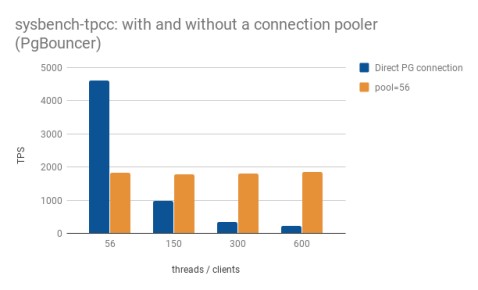
sysbench-tpcc的TPS:比较与PostgreSQL的直接连接和将PgBouncer作为连接池
在只有56个并发客户端的情况下运行sysbench-tpcc时,使用到PostgreSQL的直接连接可以提供比使用PgBouncer时高2.5倍的吞吐量(TPS表示每秒事务)。在这种情况下,使用连接池会极大地影响性能。在如此小的规模下,连接池没有任何收益,只有开销。
但是,当使用150个并发客户端运行基准测试时,我们开始看到使用连接池的好处。显然测试TPS值明显高于直连方式。
即使并发客户端数量增加一倍然后四倍,PgBouncer仍可以保持这样的吞吐量,在这种情况下,所发生的是没有立即充满大量请求到服务器,而是全部停止在PgBouncer外面。一旦释放了其池中的一个连接,PgBouncer仅允许下一个请求继续进行到PostgreSQL。
该策略对于sysbench-tpcc似乎非常有效。对于其他工作负载,平衡点可能位于其他地方。
对于上述测试,在PgBouncer上将default_pool_size设置为等于此服务器上可用的CPU内核数(56)。为了探索此参数的调整,我使用较大的连接池(150、300、600)和较小的连接池(14)重复了这些测试。结果如下:
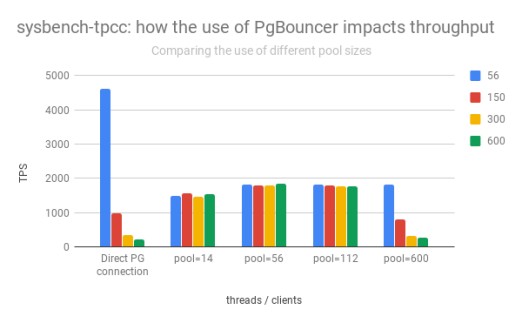
PgBouncer的使用如何影响sysbench-tpcc的吞吐量:首先比较不同池大小的使用
使用较小的连接池(14),其大小仅为可用CPU数量的1/4,仍然产生几乎相同的结果。说明充分利用PgBouncer进行连接处理已经有开始有效果。
将连接池池中的连接数加倍并没有任何实际的区别。但是一旦将该数字推断为600,此时并发线程数大于可用CPU数,吞吐量就变得与不使用连接池时的吞吐量相当。即使运行的并发线程数与池中可用的连接数(600)相同,也是这样。可以预料的是在PostgreSQL有一个实际的限制。
首先,将连接池大小设置为等于服务器中可用CPU的数量,似乎是个好主意。大约有150个左右的连接池可能有一个硬限制。下表是针对不同视图总结了获得的结果的表格:
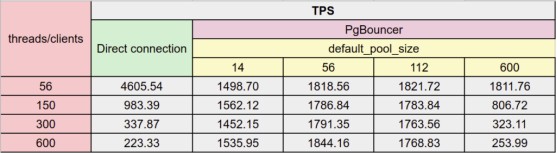
从上述的测试过程可以了解到,使用连接池可以充分提高数据库的处理效率。
Pgbouncer最佳实践:系列三
PgBouncer具有三种可用的池模式:事务池,会话池和语句池:
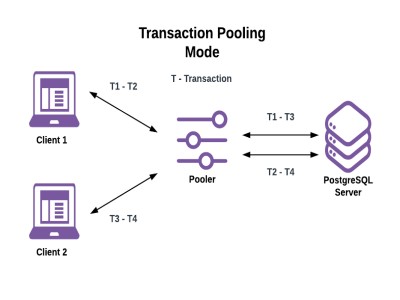
事务连接池
数据库客户端很少在不间断的情况下执行连续的事务。而是通常在事务之间执行非数据库工作。这意味着服务器连接在等待新工作到达时会花费大量时间空闲。
事务池模式试图减少服务器连接的空闲时间,如下所示:
- 池程序在开始事务时将服务器连接分配给客户端。
- 客户端的事务完成后,池程序将释放连接分配。
注意事项:
- 如果客户端运行多个事务,则每个事务可以在不同的服务器连接上执行。
- 单个服务器连接可以在其生命周期内运行由不同客户端发出的事务。
图 6 事务连接池
与服务器所允许的连接相比,允许活动客户端的数量要多得多。尽管取决于给定的工作负载,但经常会看到10倍或更多的活动客户端连接与服务器连接比率。
这确实带来了一个重要的警告:客户端不再期望对数据库会话状态所做的更改在同一客户端进行的连续事务中继续存在,因为这些事务可能在不同的服务器连接上运行。此外,如果客户端进行会话状态更改,它们可能并且很可能会影响其他客户端。
以下是一些使用上面的事务池示例:
- 如果客户端1在T1中的第一个服务器连接上将会话设置为只读,而客户端2的T3是写事务,则T3将失败,因为它在现在的只读服务器连接上运行。
- 如果客户端1运行PREPARE a1 AS ...在T1上运行EXECUTE a1 ...,在T2上,则T2将失败,因为预编译语句对于运行T1的服务器连接是本地的。
- 如果客户端2在T3中创建了一个临时表并尝试在T4中使用它,则T4将失败,因为该临时表对于运行T3的服务器连接是本地的。
有关使用事务池时不支持的会话状态功能和操作的完整列表,请参见PgBouncer的列表
会话连接池
分配给客户端的服务器连接在客户端连接的整个生命周期内持续。这看起来好像根本不使用连接池一样,但是有一个重要的区别:当分配的客户端断开连接时,服务器连接不会被破坏。当客户端断开连接时,池管理器将:
- 清除客户端所做的任何会话状态更改。
- 将服务器连接返回到池中,以供其他客户端使用。
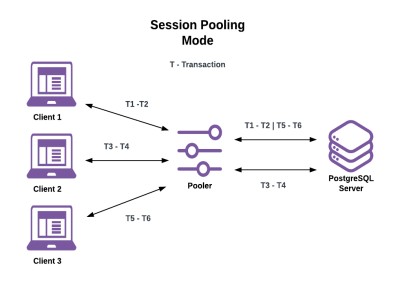
图 7 会话连接池
语句连接池
在此,服务器连接分配仅在单个语句的持续时间内持续。这具有与事务池模式相同的会话状态限制,同时还破坏了事务语义。
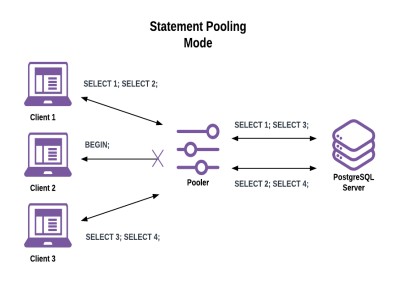
图 8 语句连接池
这使得所有客户端连接的行为就像在“自动提交”模式下一样。如果客户端尝试开始多语句事务,则合并程序将返回错误。尽管这是
表 3 连接池模式对比
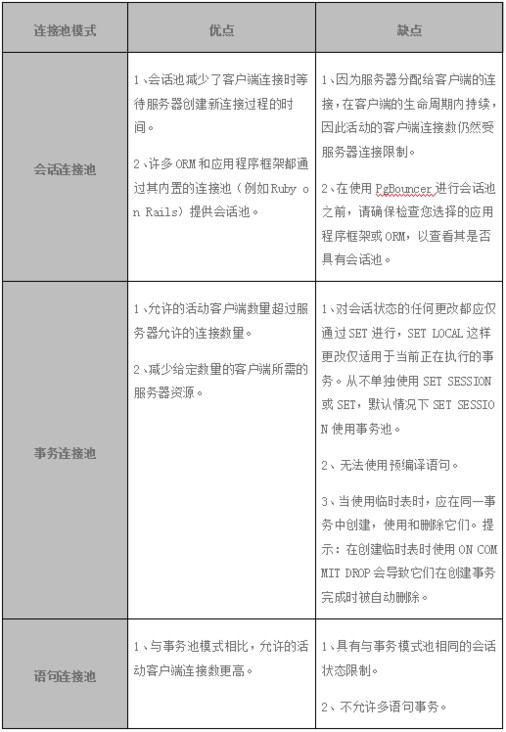
从上述对比情况来看,在连接池的选择上,需要依据业务环境特点来进行选择,默认情况下推荐使用事务连接池,它兼顾了执行事务的特性,尤其多语句的支持,并且不会像会话连接池那样,尝尝处于等待状态。当然事务模式并不支持预编译语句。而根据具体业务场景的特殊需要,有些时候需要客户端与服务器端保持连接,或者支持预编译语句,这样只能选择会话池模式。还有一些特例情况,某些业务场景只是单语句执行,那么语句池模式可能更适合。因此对比这三种模式,可以发现从对客户端操作的支持程度来讲,会话池支持度最高,其次是事务池,最后是语句池模式。但是从支持的连接数来讲,可能刚好是相反的顺序。
表 4 SQL特性对照表
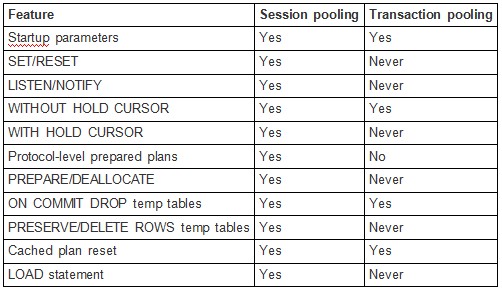
上表为会话连接池和事务连接池的SQL特性对比情况,可以通过对比具体业务场景与SQL特性的符合度,来对连接池模式进行选型。
下面列举了一些示例场景:
- 有些只运行快速查询,因此在没有事务的情况下可以共享一个会话来处理上百个并发查询。
- 一些角色成员对于会话级并发是安全的,并且总是使用事务。因此,他们可以安全地共享数百个并发事务的多个会话。
- 有些角色过于复杂,无法与其他人共享会话。因此,您对它们使用会话池模式可以避免当所有“插槽”都已占用时连接错误。
- 不要使用它代替HAProxy或其他负载均衡器。尽管pgbouncer具有一些可配置的功能来解决负载均衡器要解决的问题,例如dns_max_ttl,并且可以为其设置DNS配置,但是大多数产品环境都使用HAProxy或其他用于HA的负载均衡器。这是因为HAProxy确实擅长以循环方式在服务器之间实现负载平衡,而不是pgbouncer。尽管pgbouncer对于postgres连接池更好,但最好使用一个小型守护程序来完美地执行一项任务,而不是使用较大的守护程序来完成两项任务,那样效果更糟。
在对于连接数的建议值来讲,上文也给出了一个大致的结果,就是一般情况下设置为CPU核数的3-4倍左右,当然这个不是绝对值,应该是在与业务场景类似的硬件环境中充分进行测试后,才能够得出具体的数值。
还有一点需要注意的是连接Pgbouncer的连接方式,网络连接和unix socket连接方式,较网络连接,unix socket方式可能更加节省网络通信的开销,因此如果pgbouncer和数据库在一台机器部署,可以优选该方式;如果处于不同服务器上,则选择网络连接。
Pgbouncer最佳实践:系列四
最后再来说一下关于Pgbouncer的部署形式,包括单应用场景、多应用场景、集群场景还有多实例场景,这些方式都是依据不同的业务场景,没有孰优孰劣,符合的才是对的。其中单应用和多应用场景来源于官方。
单应用场景:
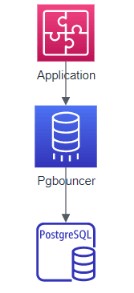
图 9 单应用多连接场景结构图
单应用场景主要具体为短连接较多的场景,频繁进行数据库的连接操作,但操作时间较短,均为短连接,所以将pgbouncer于应用服务器部署在同一台服务器,减少应用服务器和pgbouncer之间的开销。
配置文件
[databases] test1 = test = [pgbouncer] listen_port = 6688 listen_addr = 192.168.165.3 auth_type = md5 auth_file = /home/postgres/pgbouncer/bin/userlist.txt logfile = /home/postgres/pgbouncer/pgbouncer1.log pidfile =/home/postgres/pgbouncer/pgbouncer1.pid unix_socket_dir = /tmp ;;unix_socket_mode = 0777 admin_users = wzb stats_users = wzb pool_mode = session max_client_conn=1000 default_pool_size=30
导出数据库中用户名及密码到userslist.txt
userslist.txt,格式为用户名 密码
"testuser" "md54d15115d8bebd3188c1ae09c4a9848af" "testuser1" "md5f8386abbae413786661ee5a5cfb5593c" "wzb" "md53d57c4bc9a647385e6916efd0b44db46"
启动Pgbouncer
pgbouncer -d pgbouncer.ini
客户端连接方式
psql -dtest1 -Utestuser1 -p6688
多应用场景:
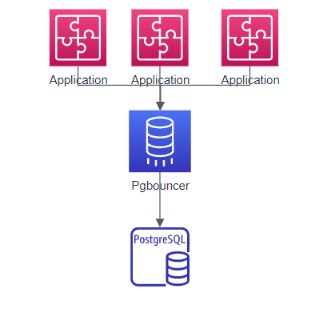
图 10多应用场景结构图
多应用场景,一般指多个应用服务器连接数据库,因此可以选择将pgbouncer与数据库服务部署在同一台服务器上,减少pgbouncer和数据库之间的开销。
配置PgBouncer.ini文件
[databases] a1 = host=127.0.0.1 port=5432 dbname=test a2 = host=127.0.0.1 port=5432 dbname=test1 [pgbouncer] listen_port = 6688 listen_addr = * auth_type = md5 auth_file = /home/postgres/pgbouncer/bin/userlist.txt logfile = /home/postgres/pgbouncer/pgbouncer.log pidfile =/home/postgres/pgbouncer/pgbouncer.pid admin_users = wzb stats_users = wzb pool_mode = session max_client_conn=1000 default_pool_size=30
导出数据库中用户名及密码到userslist.txt
userslist.txt,格式为用户名 密码
"testuser" "md54d15115d8bebd3188c1ae09c4a9848af" "testuser1" "md5f8386abbae413786661ee5a5cfb5593c" "wzb" "md53d57c4bc9a647385e6916efd0b44db46"
启动Pgbouncer
pgbouncer -d pgbouncer.ini
连接后端数据库
$ psql -p 6688 -U testuser a1
$ psql -p 6688 -U testuser1 a2
连接pgbouncer数据库
psql -p 6688 pgbouncer -U wzb
pgbouncer=# show help;
NOTICE: Console usage
DETAIL:
SHOW HELP|CONFIG|DATABASES|POOLS|CLIENTS|SERVERS|USERS|VERSION SHOW FDS|SOCKETS|ACTIVE_SOCKETS|LISTS|MEM SHOW DNS_HOSTS|DNS_ZONES SHOW STATS|STATS_TOTALS|STATS_AVERAGES|TOTALS SET key = arg RELOAD PAUSE [<db>] RESUME [<db>] DISABLE <db> ENABLE <db> RECONNECT [<db>] KILL <db> SUSPEND SHUTDOWN
SHOW
pgbouncer=# show clients;
type| C user| pgbouncer database| pgbouncer state| active addr| unix port| 6432 local_addr| unix local_port| 6432 connect_time| 2020-10-09 20:41:32 CST request_time| 2020-10-09 20:41:32 CST wait| 5 wait_us| 483185 close_needed| 0 ptr| 0x9ec340 link| remote_pid| 23567 tls |
pgbouncer=# show pools;
database| pgbouncer user| pgbouncer cl_active| 1 cl_waiting| 0 sv_active|0 sv_idle|0 sv_used|0 sv_tested|0 sv_login|0 maxwait|0 maxwait_us|0 pool_mode| transaction
集群场景(读写分离):
读写分离场景下pgbouncer的配置与前面配置基本一致,主要区别于要针对读和写进行分别部署pgbouncer,因为pgbouncer本身只是数据库连接池,不具备负载均衡,或高可用,IP漂移等特性,需要结合其他成熟产品进行组合使用。
多实例场景:
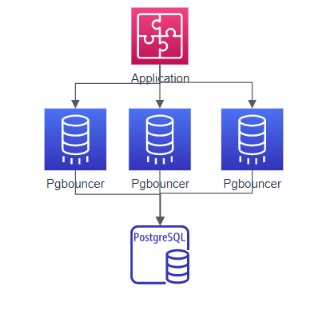
图 11 多实例场景结构图
多实例场景主要利用linux系统端口重用技术,这个特性依靠Linux内核上的支持(Linux3.6以上版本),并结合pgbouncer自身支持(设置so_reuseport=1)结合起来形成多实例场景下的pgbouncer使用,可以认为是pgbouncer的高可靠或者高可用,在某一个实例进程故障的情况下,其他实例集成仍然可以处理来自外部的数据库连接请求。从操作系统层面来看,属于多进程共享同一个端口。
实例配置1
[databases] a2 = host=127.0.0.1 port=5432 dbname=test1 pool_size=50 ;;a1 = host=127.0.0.1 port=5432 dbname=test pool_size=30 [pgbouncer] listen_port = 6688 listen_addr = 192.168.165.3 auth_type = md5 auth_file = /home/postgres/pgbouncer/bin/userlist.txt logfile = /home/postgres/pgbouncer/pgbouncer1.log pidfile =/home/postgres/pgbouncer/pgbouncer1.pid unix_socket_dir = /tmp/pg1 #unix_socket_mode = 0777 admin_users = wzb stats_users = wzb pool_mode = session max_client_conn=1000 default_pool_size=30 so_reuseport = 1
实例配置2
[databases] a2 = host=127.0.0.1 port=5432 dbname=test1 pool_size=50 ;;a1 = host=127.0.0.1 port=5432 dbname=test pool_size=30 [pgbouncer] listen_port = 6688 listen_addr = 192.168.165.3 auth_type = md5 auth_file = /home/postgres/pgbouncer/bin/userlist.txt logfile = /home/postgres/pgbouncer/pgbouncer2.log pidfile =/home/postgres/pgbouncer/pgbouncer2.pid unix_socket_dir = /tmp/pg2 #unix_socket_mode = 0777 admin_users = wzb stats_users = wzb pool_mode = session max_client_conn=1000 default_pool_size=30 so_reuseport = 1
导出数据库中用户名及密码到userslist.txt
userslist.txt,格式为用户名 密码
"testuser" "md54d15115d8bebd3188c1ae09c4a9848af" "testuser1" "md5f8386abbae413786661ee5a5cfb5593c" "wzb" "md53d57c4bc9a647385e6916efd0b44db46"
启动多实例
./pgbouncer pgbouncer.ini
./pgbouncer pgbouncer1.ini
参考
[1]Pgbouncer官网
[2]PgBouncer Configuration
[3]Tuning PostgreSQL for sysbench-tpcc
[4]understanding-user-management-in-pgbouncer
[5]performance-best-practices-for-using-azure-database-for-postgresql-connection-pooling
[6]guide-using-pgbouncer
[7]azure-database-for-postgresql/connection-handling-best-practice-with-postgresql
[8]steps-to-install-and-setup-pgbouncer-connection-pooling-proxy
[9]pg-phriday-securing-pgbouncer
- 发表于 2022-02-27 23:17
- 阅读 ( 41 )
