Postgresql 高可用方案 PGHA
一、Why PGHA 背景
Why do we need PostgreSQL High availability (HA)?
基础软硬件的升级/试用/日常维护给 DB 可用性指标带来挑战
switchover (计划内)和 failover( 故障转移)切换的操作步骤及注意点较多,人工操作效率低且易出错
由于 failover 的随机性,地铁/半夜/假期.....DBA 需安排值班人员值守
DB Instance Crash 的概率虽很低,但如果没有 HA 守护,RD/QA/老板 心里没底,提供的 DB 服务会认为不靠谱......需要的是N个9的服务!
二、PGHA of Qunar 选型
1、流行的开源PGHA方案概况
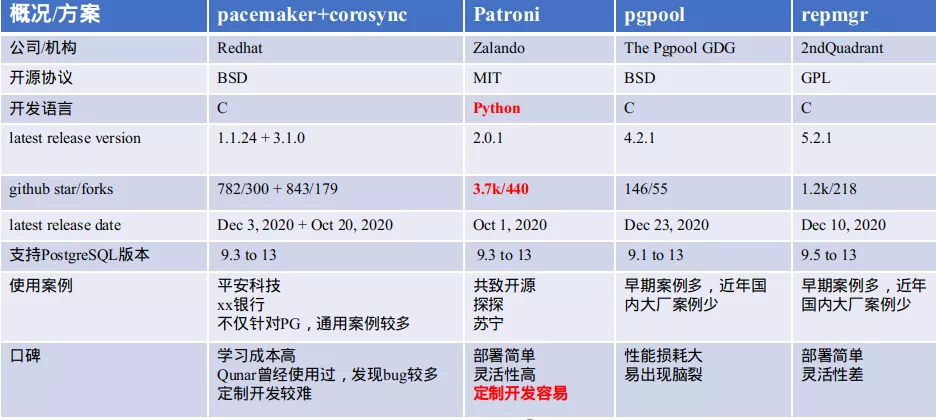
(数据截止2021-1-10)
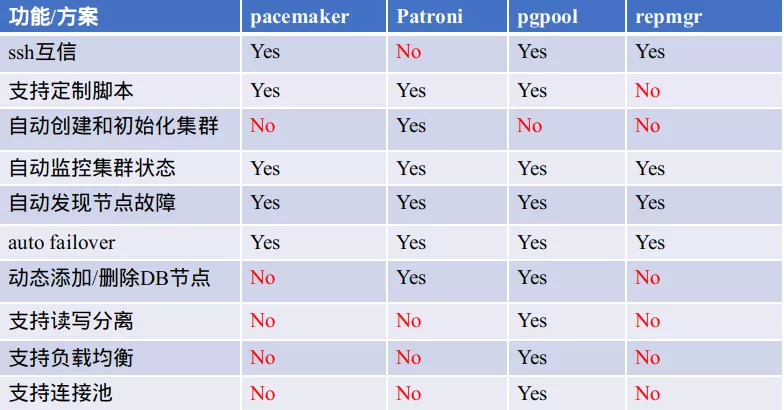
2、流行的开源PGHA功能对比
3、PGHA最终选型
通过对上述诸多参考项对比,在开发语言( Python 在 Qunar 自动化运维体系建设中被广泛应用,而 C 学习和维护成本均较高),活跃度,案例使用量及功能等方面,Patroni 具有明显的优势,最终 Qunar PGDBA 团队选型了 Patroni 。
Patroni 基本架构如下:
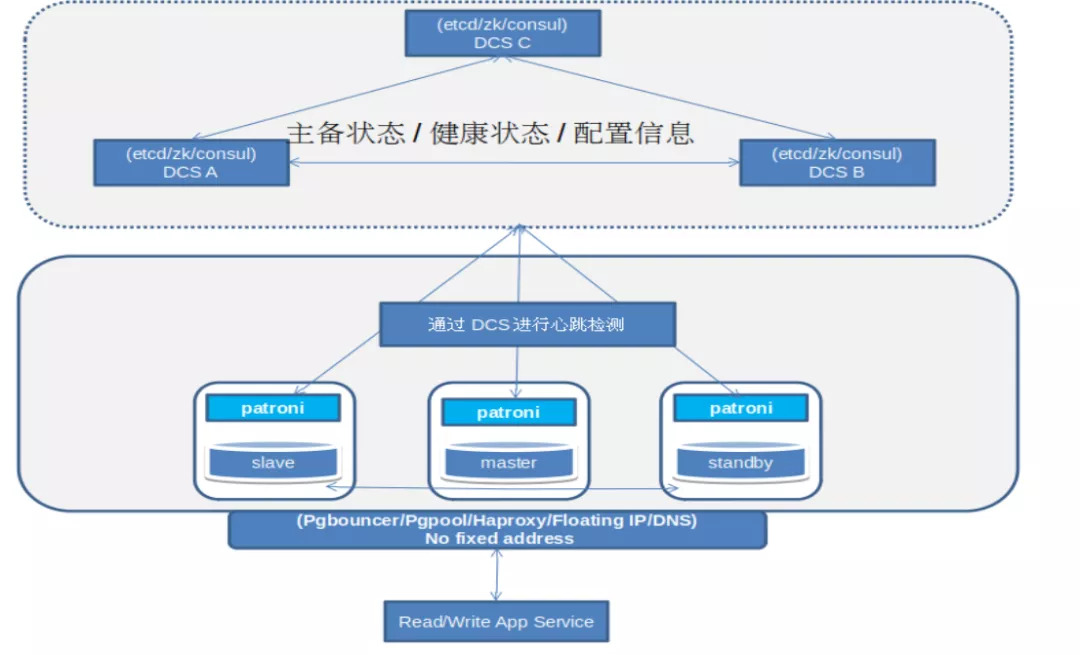
主要优点:
支持同步复制
支持设置切换最小数据差异
自动化程度高不易出现脑裂
可用 pg_rewind 修复脑裂 DB 实例
HA对运维体系的冲击:
Patroni 会全面接管 DB Cluster 所有节点的配置文件,对原生 Cluster 有一定侵入性
Patroni 管理的 DB Cluster 日常运维需通过 HA 来实现
总之,HA 在保证可用性指标的同时,也需要我们随之更新已有的运维体系,同时对 HA 本身也需要一定维护成本,这是很正常的 trade off 。
三、PGHA of Qunar 定制
We call Patroni a “template” because it is far from being a one-size-fits-all or plug-and-play replication system.
1、核心组件选型/定制功能
DCS(Distributed Configuration Storage)选型:zk/etcd/consul?
三种 dcs 各有优劣,个人见解,一般技术选型考虑的主要因素是掌控程度(熟悉程度)和公司技术栈。考虑到 Qunar 的主流技术栈是 Java + zk ,故选择已经有专业人士维护的 zk 。
DCS 部署在 DB 集群各节点本机还是选择在所有集群之外集中式部署?
考虑到集中式的统一集群便于维护和所有 DB Cluter 统一使用,故选择集中式 zk 集群。
原生方案在预防集群脑裂方面存在不足之处,如何最大限度防止脑裂?
原生方案在主从切换时防止脑裂的主要方式是使用 watchdog 进行机器重启,但不同 OS ,不同 kernel ,甚至不同硬件机型上的 watchdog 配置和实现存在差异,不一定 100% 可将机器重启,且本身触发 watchdog 关机需要一定时间,不一定 100% 在抢到 Leader key 的从库 promote 为主库之前将机器重启!
所以在 watchdog “自杀”主库所在 Server 不一定成功或及时的情况下,Qunar 定制开发了 OS Console Power Reset(断电重启)功能,从库 promote 为主库之前,首先对原主库所在 Server 强制无条件执行 power reset 进行“他杀”, Console 管理口走的是 DB 应用之外的机房单独的管理网络且 Power Reset 速度较 watchdog 重启机器更快,最为靠谱!
Application 和 DB Cluster层的高可用如何选型?
Pgbouncer/Pgpool/Haproxy/Floating IP/DNS 选择哪一个?基于大多数Qunar 的 DB Cluster 已配有 Virtual ip 的现状,且 Vip 对各种语言开发的 Application兼容性好,决定使用Float Vip的方案,相比使用 Pgbouncer/Pgpool/Haproxy ,架构简单易于维护。
原生方案有Master Failover, 但无Slave Failover!
大多数集群上的应用都做了读写分离,从库也有使用,所以 Master Vip 和 Slave Vip 均需要定制开发 vip 自动漂移相关功能。
Master 和 Slave 之间由于网络抖动导致主从通信异常会出现什么情况?
Slave Vip 发生频繁漂移的情况,会导致过频的杀掉应用连接, 所以 API timeout (默认2s)时间也需要可定制。
原生方案在集群初始化 HA 时,各个节点需强制重启,影响应用
此时,zk 里尚未注册 DB 集群数据,原生方案为保证 DB 实例参数符合 yml 配置文件里的参数要求,各个节点需强制重启,尤其是主库,对应用存在较大影响,需进行定制优化。
最终定制实现: 上线 PGHA 主库不需要重启, 从库如果保证 recovery.conf 的参数符合 yml 文件的设置的参数, 亦不会发生重启。
如果zk本身服务挂掉或网络抖动导致zk无法访问,会出现什么情况???
原生方案在处理 DCS 本身的故障时不完善,为避免脑裂会出现 DB Cluster 无 Master 的情况,需定制开发 zk 故障处理功能!
- 发表于 2021-12-06 16:03
- 阅读 ( 33 )
