SQL中GROUP BY的这些使用诀窍,你都学“废”了吗?
1. GROUP BY 功能概述
2. GROUP BY 过滤分组(HAVING)
3. HAVING和WHERE 可同时出现在GROUP BY 里
4. GROUP BY 和ORDER BY 协同使用
一、GROUP BY 功能概述
GROUP BY的功能是对数据库中的记录按照某种规则或是属性(列)进行分组。即分门别类的过程。比如当前数据库中有test表。其表结构字段如下:
//name-姓名 sex-性别 age-年龄 address-住址
CREATE TABLE Test(id serial primary key, name varchar(20), sex char, age smallint, address varchar(20));
INSERT INTO Test(name,sex,age,address) VALUES('小明', '男', 26, '杭州');
INSERT INTO Test(name,sex,age,address) VALUES('小花', '女', 24, '四川');
INSERT INTO Test(name,sex,age,address) VALUES('小强', '男', 29, '湖南');
INSERT INTO Test(name,sex,age,address) VALUES('小刚', '男', 19, '贵州');
INSERT INTO Test(name,sex,age,address) VALUES('小燕', '女', 27, '重庆');
INSERT INTO Test(name,sex,age,address) VALUES('小燕', '女', 18, '山西');
然后向该表test中插入上面的5个记录。如下图所示。
test表中记录信息

若是以name进行分组,则将会以name为基准,统计该test表中所有的名字,并且过滤掉重复的name,即多个重复的名字只显示一个。因为是分组,那么这个重复的“小燕”-name肯定归属于同一个组(name)中,虽然他们不是同一个人,但是属于同一组(name)

test对name进行分组
现在以name(姓名)进行分组,并统计每一个组的人数。如下所示。可以看到,name为小燕的组的人数共有两人,从test表记录也可以看到2个名为“小燕”的记录。
INSERT INTO Test(name,sex,age,address) VALUES('小燕', '女', 27, '重庆');
INSERT INTO Test(name,sex,age,address) VALUES('小燕', '女', 18, '山西');

GROUP BY 中注意事项
(1)GROUP BY 必须出现在WHERE子句之后,ORDER BY 子句之前;
(2)GROUP BY 语句后面可以包含任意数目的列,但是这些任意数据的列需要和SELECT 后面的列数量(顺序可以不一致)保持一致。
二、GROUP BY过滤分组(HAVING)
在SQL中,较为频繁的使用WHERE语句来对检索的记录(行)进行过滤。而在使用GROUP BY的时候,就不能使用WHERE来进行分组的过滤了。因为WHERE的过滤功能是针对行,而不是分组。事实上,WHERE是没有分组的概念的。因此,对于分组的过滤,SQL特意提供了另外的一个关键字 HAVING,用以过滤分组的功能。
HAVING和WHERE的区别
(1)WHERE过滤行,HAVING过滤分组;
(2)WHERE在数据分组前进行过滤,HAVING在数据分组之后进行过滤。WHERE排除后的行不会出现在分组之中。
以name进行分组,并且过滤掉name组中总人数小于2的分组。因为当前满足分组大于等于2的分组只有一组(“小燕”)。因此其他组会被过滤掉。如下图所示。

test对name进行分组并过滤掉分组内总数小于2的组
三、HAVING和WHERE可同时出现在GROUP BY中
HAVING子句和WHERE子句可以同时出现在GROUP BY 语句中。比如现在需要筛选出test表中name是“xiaoqiang”并且分组的总数(聚簇)不小于2的记录信息。
SELECT name, COUNT(*) AS name_num FROM test WHERE name = '小强' GROUP BY name HAVING COUNT(*) >=2;

test表对name进行分组,并同时使用WHERE和HAVING
因为当前test表记录中没有满足name(名字)是“小强”并且分组后该组内人数大于等于2的记录数据,因此其统计结构为0。
四、GROUP BY 和ORDER BY协同使用
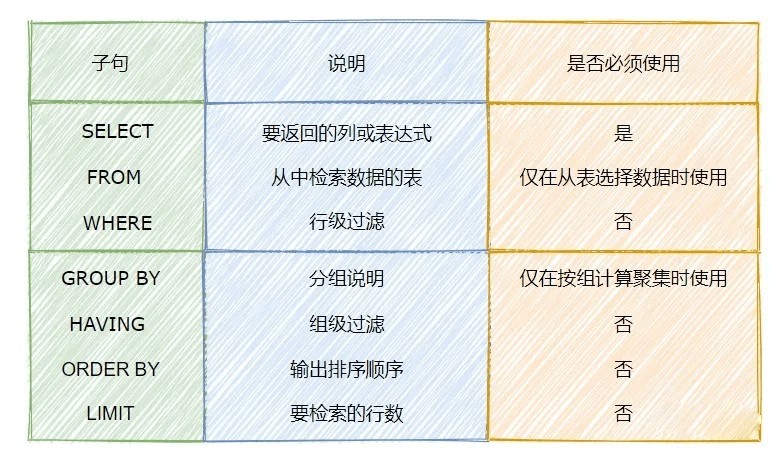
GROUP BY会对每个分组中的数据进行聚簇操作。但是输出的数据不保证有序,即按照该分组字段从大到小,或是从小到大的顺序去输出并展示。因此若想对GROUP BY分组后的数据以某种规则(字段-升序/降序),则可以使用ORDER BY 来实现该功能。注意:ORDER BY 出现在GROUP BY之后。SELECT中各子句的顺序如下图所示。
- 发表于 2021-07-26 13:19
- 阅读 ( 37 )
