Redis 超详细自动管理Cluster集群工具上手 redis-trib.rb (多图,手把手)
安装介绍
redis-trib.rb是一款由Redis官方提供的集群管理工具,能够大量减少集群搭建的时间。
除此之外,还能够简化集群的检查、槽迁徙、负载均衡等常见的运维操作,但是使用前必须要安装ruby环境。
1)使用yum进行安装ruby:
yum install -y rubygems
另外,在新版Redis中,redis-trib.rb工具的功能都被集成在了redis-cli里,但依然需要ruby环境
搭建前戏
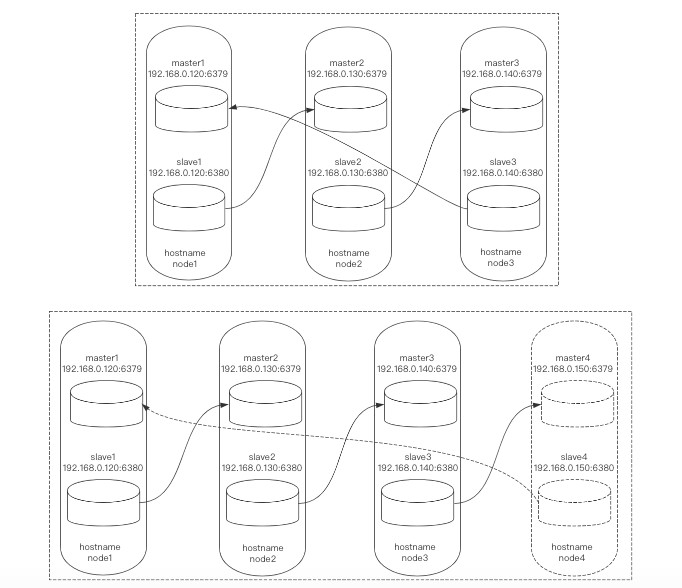
地址规划
首先我们准备2主2从的3台多实例服务器,利用redis-trib.rb工具搭建1个6节点3分片的集群(集群最少6节点)。
然后再使用redis-trib.rb工具增加1台多实例服务器,组成8节点4分片的集群。
之后再使用redis-trib.rb工具下线1台多实例服务器,变为6节点3分片的集群。
地址规划与架构图如下:
在每个节点hosts文件中加入以下内容;
$ vim /etc/hosts
192.168.0.120 node1
192.168.0.130 node2
192.168.0.140 node3
192.168.0.150 node4
!由于该工具具有难以发现的小bug,必定出现以下问题:
- 主从关系自动构建不准确,需要手动重新搭建主从关系,如果主从构建不合理,一旦发生灾难情况后果不堪设想
集群准备
为所有节点下载Redis:
$ cd ~
$ wget https://download.redis.io/releases/redis-6.2.1.tar.gz
集群搭建
启动集群
每个节点上执行以下2条命令进行服务启动:
$ redis-server /usr/local/redis_cluster/redis_6379/conf/redis.cnf
$ redis-server /usr/local/redis_cluster/redis_6380/conf/redis.cnf
自动化
现在我们有2个部分还没有做,1是对集群进行分槽工作,2是构建主从关系。
通过redis-trib.rb工具,这个步骤将变得异常简单,由于我的ruby是装在node1上,所以只需要在node1执行下面一句话即可。
$ cd /usr/local/redis_cluster/redis-6.2.1/src/
# 旧版Redis这里以脚本名开头 redis-trib.rb 跟上后面参数即可
$ redis-cli --cluster create 192.168.0.120:6379 192.168.0.140:6380 192.168.0.130:6379 192.168.0.120:6380 192.168.0.140:6379 192.168.0.130:6380 --cluster-replicas 1
参数释义:
- --cluster-replicas:指定的副本数,其实这一条命令的语法规则是如果副本数为1,第一个ip:port与它后面的1个ip:port建立1主1从关系,如果副本数是2,第一个ip:port与它后面的2个ip:port建立1主2从关系,以此类推
执行完这条命令后,输入yes,会看到以下信息:
$ redis-cli --cluster create 192.168.0.120:6379 192.168.0.140:6380 192.168.0.130:6379 192.168.0.120:6380 192.168.0.140:6379 192.168.0.130:6380 --cluster-replicas 1
# 主从相关
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 192.168.0.140:6379 to 192.168.0.120:6379
Adding replica 192.168.0.130:6380 to 192.168.0.140:6380
Adding replica 192.168.0.120:6380 to 192.168.0.130:6379
M: c71b52f728ab58fedb6e05a525ce00b453fd2f6b 192.168.0.120:6379
slots:[0-5460] (5461 slots) master
M: 6a627cedaa4576b1580806ae0094be59c32fa391 192.168.0.140:6380
slots:[5461-10922] (5462 slots) master
M: 282358c2fb0c7c16ec60f2c4043b52a0eb91e19f 192.168.0.130:6379
slots:[10923-16383] (5461 slots) master
S: d645d06708e1eddb126a6c3c4e38810c188d0906 192.168.0.120:6380
replicates 282358c2fb0c7c16ec60f2c4043b52a0eb91e19f
S: 7a7392cb66bea30da401d2cb9768a42bbdefc5db 192.168.0.140:6379
replicates c71b52f728ab58fedb6e05a525ce00b453fd2f6b
S: ff53e43f9404981a51d4e744de38004a5c22b090 192.168.0.130:6380
replicates 6a627cedaa4576b1580806ae0094be59c32fa391
# 询问是否保存配置?输入yes
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
.
# 分槽相关,全部自动进行,无需手动操作
>>> Performing Cluster Check (using node 192.168.0.120:6379)
M: c71b52f728ab58fedb6e05a525ce00b453fd2f6b 192.168.0.120:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 282358c2fb0c7c16ec60f2c4043b52a0eb91e19f 192.168.0.130:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: 6a627cedaa4576b1580806ae0094be59c32fa391 192.168.0.140:6380
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: d645d06708e1eddb126a6c3c4e38810c188d0906 192.168.0.120:6380
slots: (0 slots) slave
replicates 282358c2fb0c7c16ec60f2c4043b52a0eb91e19f
S: 7a7392cb66bea30da401d2cb9768a42bbdefc5db 192.168.0.140:6379
slots: (0 slots) slave
replicates c71b52f728ab58fedb6e05a525ce00b453fd2f6b
S: ff53e43f9404981a51d4e744de38004a5c22b090 192.168.0.130:6380
slots: (0 slots) slave
replicates 6a627cedaa4576b1580806ae0094be59c32fa391
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
$
仔细观察上面的主从关系就可以看到异常,我的规划是所有的6379为主节点,而6380为从节点,显然他没有按照我的意思进行划分主从。
这种情况还算好的,至少不同节点都是岔开的,怕就怕一台机器2个实例组成1主1从,如果是那样的结构主从就没有任何意义。
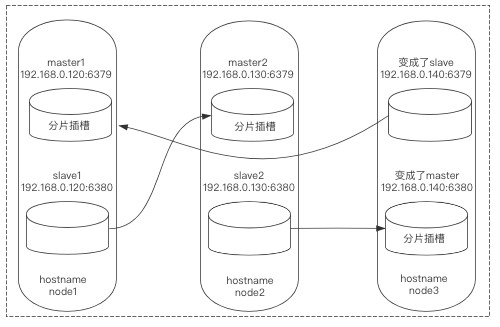
主从校正
由于上面自动部署时主从关系出现了问题,超乎了我们的预期(这可能是该工具的bug),所以我们要对其进行手动校正。
1)登录node3:6380,让其作为node1:6379的从库,由于node3:6380是一个主库,要想变为从库必须先清空它的插槽,而后进行指定:
$ redis-cli -h node3 -p 6380 -c
node3:6380> CLUSTER FLUSHSLOTS
node3:6380> CLUSTER REPLICATE c71b52f728ab58fedb6e05a525ce00b453fd2f6b
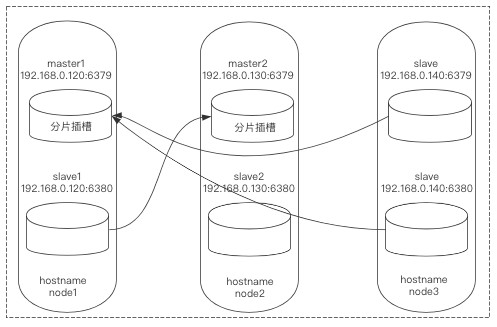
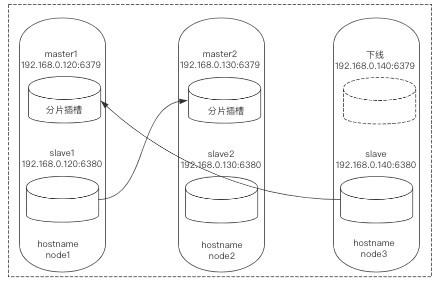
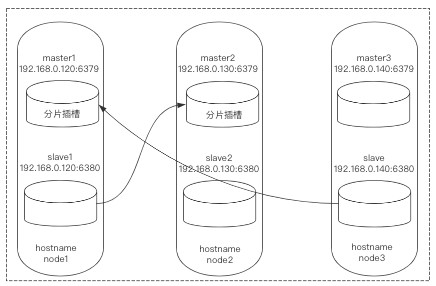
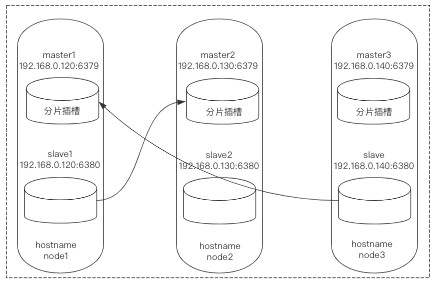
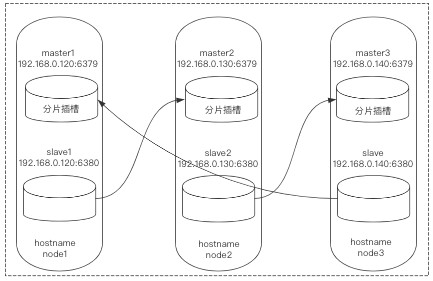
下面可能是我上面操作时输错了node-id导致的,一般按正确步骤来说不用产生这种情况。
*8)发现节点关系还是不正常,node3:6380也对应了node3:6379,更改一下就好了,让其对应node1的6379:
$ redis-cli -h node3 -p 6380
node3:6380> CLUSTER REPLICATE c71b52f728ab58fedb6e05a525ce00b453fd2f6b
集群扩容
发现节点
现在我们的node4还没有添加进集群,所以将node4进行添加:
$ redis-cli -h node1 -p 6379 CLUSTER MEET 192.168.0.150 6379
$ redis-cli -h node1 -p 6379 CLUSTER MEET 192.168.0.150 6380
目前node4的6379和6380并未建立槽位,也没有和其他节点建立联系,所以不能进行任何读写操作。
进行扩容
使用redis-trib.rb工具对新节点进行扩容,大体流程是每个节点拿出一部分槽位分配给node4:6379。
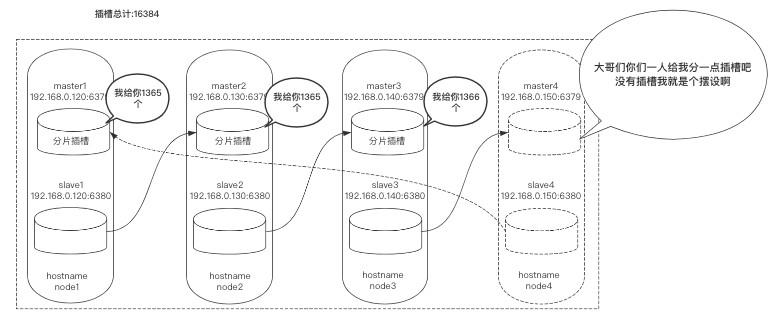
在槽位迁徙时会带着数据一起迁徙,这并不会影响正常业务,属于热扩容。
首先要做4分片的规划,每个节点共分4096个槽位:
$ python3
>>> divmod(16384,4)
(4096, 0)
查看集群节点信息,发现他分配的并不是特别均匀,只要误差在2%以内,就算正常范围。
主从修改
如果你在线上生产环境中对Redis集群进行了扩容,一定要注意主从关系。
手动的对主从关系进行校正,这里不再进行演示。
集群缩容
移除节点
下线节点时,节点如果持有槽必须指定将该槽迁徙到别的节点。
在槽迁徙时,数据也会一并迁徙,并不影响业务。
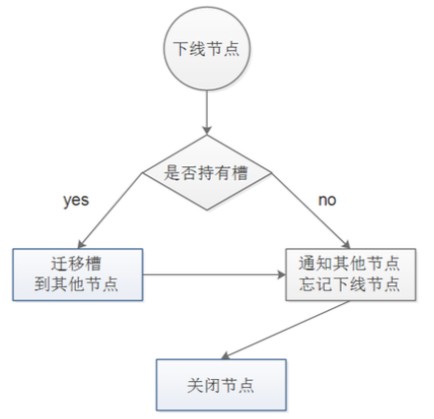
同时,当槽迁徙完成后,可在集群中对该节点进行遗忘。
进行缩容
这里缩容对象还是node4:6379,它本身具有4096个插槽,我们需要分别把4096个插槽移动到node1:6379、node2:6379、node3:6379上。
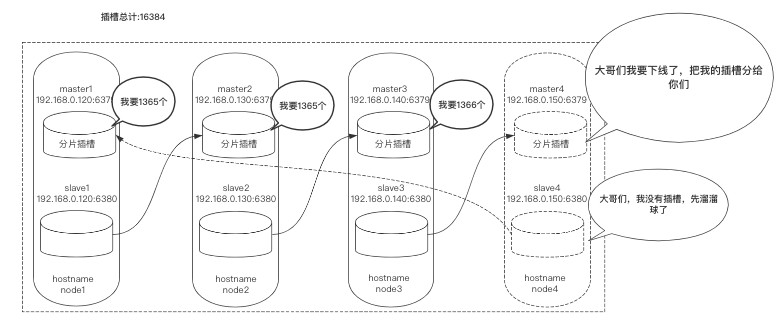
计算每个节点分多少:
$ python3
>>> divmod(4096,3)
(1365, 1)
# 2个分1365 1个分1366
扩容完成后检查集群状态:
进行下线
现在就可以对node4:6379与node4:6380进行下线了,任意登录集群中某一节点,输入以下命令:
$ redis-cli -h node1 -p 6379 cluster FORGET d1ca7e72126934ef569c4f4d34ba75562d36068f
$ redis-cli -h node1 -p 6379 cluster FORGET f3dec547054791b01cfa9431a4c7a94e62f81db3
至此,node4:6379以及node4:6380成功下线。
主从修改
如果你在线上生产环境中对Redis集群进行缩容,一定要注意主从关系。
手动的对主从关系进行校正,这里不再进行演示。
- 发表于 2021-06-28 19:32
- 阅读 ( 34 )
