数据库丢失数据大揭秘!
1.前言
一旦发生数据丢失、数据损坏,造成的影响就会非常大,这就要求业务系统有一个完善的机制以应对这些场景带来的灾难(服务器宕机、数据库崩溃或损坏、硬件故障等),比如之前的案例,2018年,腾讯云硬盘由于磁盘静默错误,导致创业公司线上生产数据完全丢失。为此,常见的应对方式有备份、冗余、灾备、快照、高可用等等。对于数据库来说,还有闪回等方式。
2.Priorities
服务器硬件简单来说就是CPU + 内存 + 磁盘(磁盘控制器也是一个重要的组成),对于一般的服务器优先级来说,主要都是受限于CPU,主要因为:
- 网络开销(http)
- 虚拟机(应用服务器)
- 应用程序代码
- ...
- x86架构的CPU目前主流是Intel和AMD(此处只谈x86架构的CPU,毕竟现在绝大多数数据库、中间件等还是跑在x86服务器上),Intel的处理器核心速度要比AMD快,但是价格和相关部件也更加昂贵,而AMD在多核处理器的价格上更有优势,并且使用AMD处理器的服务器性能通常不错,处理器设计能够使每个核心最大程度地利用内存。对于PostgreSQL9.6以后的版本来说,引入了并行机制,那么这种情况下AMD的优势就发挥出来了,我们可以使用一定的并行特性处理查询;对于较低的版本,那么为了尽可能快地运行,Intel就更为合适一点。但是,对于数据库服务器来说,就不是这样了,往往都是受限于磁盘(IO),比如
- 针对大表的顺序扫描
- 索引扫描带来的随机IO
- 检查点、后台写等消耗IO大户
- ACID中的持久化
- ...
- 当然随着SSD等磁盘技术的平民化,以及动辄上百GB内存的普及,I/O层面的性能问题得到了有效缓解。
3.花样Cache
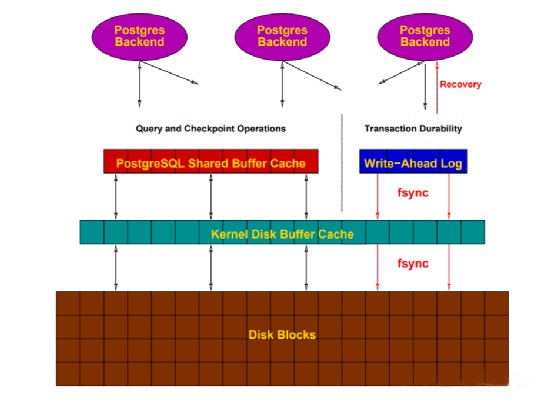
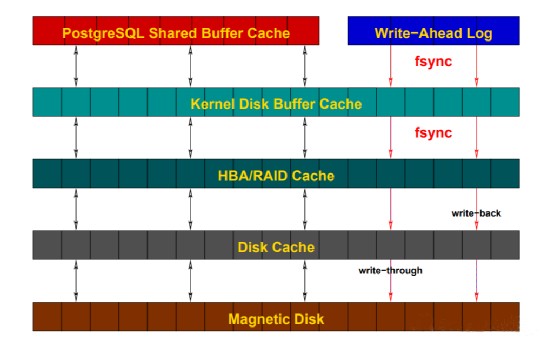
在存储系统中,Cache几乎无处不在,文件系统有Cache,存储有Cache,RAID控制器上有Cache,磁盘上也有Cache。操作系统的写缓存一般都可以达到GB的规模,RAID控制器上的缓存一般在128MB ~ 512MB,SAN上的缓存也达到GB,磁盘上的cache,一般是16M ~ 64M。在PostgreSQL中,实际是在写操作后马上调用fsync(fsync = on),wal_sync_method参数则用来控制使用哪种方法进行fsync。PostgreSQL为了保证数据的一致性,对于redo log支持Direct IO,Direct IO会绕过文件系统的Cache(对于Shared Buffer则只有Buffer IO),但是,OS不知道存储这一层,虽然绕过了文件系统层面的Cache,但是依然可能写在存储的Cache上。一般存储都有Cache,为了提高性能,写操作在Cache上完成就返回给OS了,也即write back,为了保证掉电时Cache中的内容不会丢失,存储一般都有电池保护,这些电池可以供存储在掉电后工作一定时间,保证Cache中的数据被刷入磁盘,不会丢失。另外一些控制器卡会监控电池的健康状况,当没有电池或电池不足时,会自动从write back切换到write through的模式。另外很多存储厂商都明确表示,存储中磁盘的Cache是禁用的,为了保证数据可靠性,而存储本身又提供了非常大的Cache,相比较而言,磁盘上的Cache就不再那么重要。可以参考下面的图片,一次IO经历了多少Cache才到磁盘上。 - 很多人都误认为使用write就能将数据写入到磁盘上,然而这是错误的。一般情况下,对文件的write只会更新内存中的页缓存,这些页缓存不会立刻刷入磁盘,操作系统的 flusher线程会在满足以下条件时将数据落盘:1)空闲内存下降到了特定的阈值,需要释放脏页占用的内存空间;2)脏数据持续了一定时间,最老的数据就会被写入磁盘;3)用户进程执行sync或者fsync系统调用;如果我们想要将数据立刻刷入磁盘,就需要在执行write后立刻调用fsync等函数,当 fsync等函数返回后,数据库才会通知调用方数据已经成功写入。PostgreSQL认为系统提供的fsync调用是可靠的,即写到了持久化的存储。然后下面还有更底层的Raid Cache、Disk Cache等,虽说大多数Raid卡或企业级SSD可以通过电容残余的电量,将Disk Cache里的数据持久化下来,但是请不要相信所有磁盘都有这个功能。所以这个可以叫做"说谎的驱动器",虽然返回写成功了,但是不一定实际写入了。因此不要轻易使用易失缓存,可以使用有掉电保护的易失缓存。在个人工作过程中,还有幸暂未遇到因为回写缓存,系统崩溃导致PostgreSQL无法使用的例子。至此,我们可以看到在PostgreSQL中,一个物理IO是经历了一系列的Cache之后,最终被写入到磁盘上。
4.其他意外
除了上面介绍的因为各种Cache的存在导致数据没有及时刷入磁盘带来的数据丢失风险,还有就是常见的人为错误。人为错误是造成数据丢失的首要原因。在2018年腾讯云数据丢失事故中,我们会发现,虽然事故的起因是硬件故障,但是最终导致数据完整性受损的还是运维人员的不当操作,可以参照官方说法:https://mp.weixin.qq.com/s/8JSPY6vHPhg8pX0JwjqttQ第一是正常数据搬迁流程默认开启数据校验,开启之后可以有效发现并规避源端数据异常,保障搬迁数据正确性,但是运维人员为了加速完成搬迁任务,违规关闭了数据校验;第二是正常数据搬迁完成之后,源仓库数据应保留24小时,用于搬迁异常情况下的数据恢复,但是运维人员为了尽快降低仓库使用率,违规对源仓库进行了数据回收。因此减少人为错误的最好方式是将数据的备份和运维等操作标准化,使用自动化的流程处理涉及数据安全的操作,这样才能降低人为干预带来的风险。除此之外,还有不可预知的硬件错误,比如上述事件中的磁盘静默错误,一个较好的做法是部署那些已经在市场上经过长时间检验的硬件设备,这样可以通过既往经验获取较为真实可靠的硬件故障率。这里可以看一下google的一个故障趋势调研:Failuer Trends in a Large Disk Drive Population,https://wenku.baidu.com/view/3fc77221dd36a32d7375817c.html5.预防
既然数据随时有丢失的风险,那么就一定做好预防措施,针对PostgreSQL,整理了一下现有的预防措施。5.1 备份大法
最先想到的就是备份大法,不管是pg_dump等逻辑备份,还是cp、pg_basebackup等物理备份,还是存储级别的快照备份,都可以实现目的。然后结合归档WAL日志,实现PITR,不过需要确保有误操作前的全量备份和所有WAL归档。因此RTO和RPO的选择也同样至关重要 5.2 Standby数据库
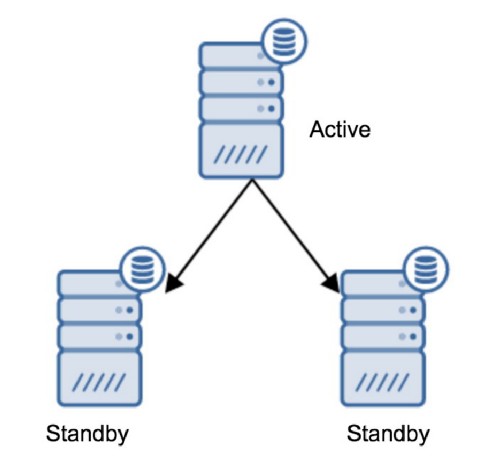
这个也是能想到的另一种方法,当主库服务器异常时,备库可以快速提升为主并提供服务,同时备库的存在,也提供了数据库的另一个副本,主库数据丢失后,备库还有一份数据。另外,还有强大的"延时备库",recovery_min_apply_delay,设置备库延迟重做WAL的时间,而备库依然及时接收主库发送的WAL日志流,只是不是一接收到WAL后就立即应用,而是等待此参数设置的值再应用。注意若synchronous_commit=remote_apply,主库每插入一条语句都需要延迟recovery_min_apply_delay该参数这么久才能继续写。比如recovery_min_apply_delay = 24h,主库上不小心删了一张表,那么你还有24小时的时候在备库上进行挽救操作。5.3 控制vacuum
我们知道在PostgreSQL的MVCC实现方式中,死元组并不会立即删除,而是由后台vacuum进程去定期清理那些"不可见"的死元组。所以还有一种操作是,把autovacuum设为off,关闭后台自动清理进程,由自己手动去执行vacuum的动作,这样那些未执行过vacuum的表里的死元组就会一直保留,然后通过pg_resetwal"篡改"数据库的事务号,达到数据可见的目的。注意关闭autovacuum会导致表膨胀,除非你知道自己在干什么,否则不要关闭autovacuum,对更新频繁的数据库或表更要慎重使用这一技巧。并且这种方式不适用于drop table,vacuum full和truncate等DDL,会提示/base/xxx not exists,因为原来的数据文件已经被删了。另外一个可以控制vacuum的参数较vacuum_defer_cleanup_age,延迟多少个事务进行清理,比如设置为100,也不会立马删除,留下抢救的时机。5.4 回收站
pgtrashcan垃圾回收工具,就像windows中的回收站,删除了文件后,是放在回收站的,可以选择还原,找回相关文件。同样,当我们删除PostgreSQL表后,表并不会立即物理删除,而是先保存到回收站中,在需要时可以恢复表。当DROP TABLE命令执行后,表会被移到一个名为"Trash"的schema下,如果想永久删除此表,可以删除"Trash"模式下的这张表或者删除整个"Trash" 模式,这个pgtrashcan仅对表有效,其它数据库对像被删除后不会转移到"Trash"模式。5.5 反向生成undo
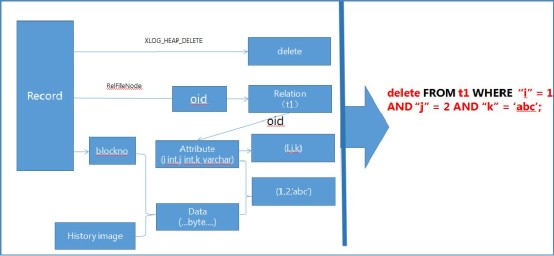
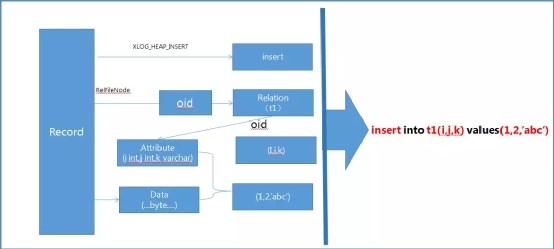
PostgreSQL因为没有undo的原因,但是由于有WAL的存在,WAL日志里面记录了对数据文件的修改,所以这里就要使用到另一个工具walminer了,首先向作者致敬,真是一个十分给力的工具。这个是一个类似MySQL中的binlog2sql的日志解析工具,通过walminer,可以逆向解析出undo sql,如下,比如误删一条数据,那么拿出相应的undo sql重新insert一下即可。这里引用一下作者的原图:ØDELETE语句解析原理- ØINSERT语句解析原理
- postgres=# select * from walminer_contents;
- -[ RECORD 1 ]-------------------------------------------------------------
- sqlno | 1
- xid | 268435484
- topxid | 0
- sqlkind | 1
- minerd | t
- timestamp | 2020-06-18 11:14:45.380952+08
- op_text | INSERT INTO public.t1(i ,j ,k) VALUES(3 ,1 ,'after truncate')
- undo_text | DELETE FROM public.t1 WHERE i=3 AND j=1 AND k='after truncate'
- complete | t
5.6 篡改事务状态
从PostgreSQL多版本实现的原理上,通过篡改事务状态找回数据也是有可能的。因为PostgreSQL的多版本原理是旧数据并不删除:1)对于删除数据的操作,只是把行上的xmax改成当前的事务id2)对于更新操作,只是把原先行上xmax改成当前的事务id,并插入一个新行,而新行上的xmin置为当前的事务id事务的状态是记录在commit log中的,如果事务提交,只是把commit log中相应的事务状态改成"已提交状态(TRANSACTION_STATUS_COMMITTED )",如果事务回滚,则把commit log中的事务状态改成"事务回滚(TRANSACTION_STATUS_ABORTED )"所以从理论上说,只要把在commit log中刚提交事务状态从"TRANSACTION_STATUS_COMMITTED"改成"TRANSACTION_STATUS_ABORTED",原先的事务就会做废,就能回到事务之前的状态。但同时tuple上面还由于有infomask标志位的存在,加速获取事务状态。在PostgreSQL中提供了TransactionIdIsInProgress、TransactionIdDidCommit和TransactionIdDidAbort用于获取事务的状态,这些函数被设计为尽可能减少对CLOG的频繁访问(假如把freeze相关参数设置为20亿的话,那么clog最多可能达到500多MB,每一个事务占2bit)。尽管如此,如果在检查每条元组时都执行这些函数,也可能会成为瓶颈。所以,为了解决这个问题,PostgreSQL在t_infomask中使用了相关标志位,如下:#define HEAP_XMIN_COMMITTED 0x0100 /* t_xmin committed */#define HEAP_XMIN_INVALID 0x0200 /* t_xmin invalid/aborted */#define HEAP_XMAX_COMMITTED 0x0400 /* t_xmax committed */#define HEAP_XMAX_INVALID 0x0800 /* t_xmax invalid/aborted */在读取或写入元组时,PostgreSQL会择机将提示为设置到t_infomask中,比如上面的例子,PostgreSQL检查了元组的t_xmin对应事务的状态,结果为commited,那么就会在元组的t_infomask中置位一个HEAP_XMIN_COMMITTED,表示这条元组已经提交了,如果设置了标志位,那么就不再需要去调用TransactionIdDidCommit和TransactionIdDidAbort去获取事务的状态,可以高效地检查每个元组xmin和xmax对应的事务状态。所以要想恢复数据,还需要把相应表文件中各行上的t_infomask状态中的hint标志位给清除掉之后,数据才能恢复回来。为此,唐成老师专门写了一个工具,pg_fix,https://github.com/osdba/pg_fix,直接修改表中数据和commit log中事务的状态,注意生产上慎用。
5.7 闪回
Oracle支持强大的闪回,闪回特性使用场景: 1)flashback database:数据库闪回;多用于数据库恢复,数据库、用户、表空间误删。 2)flashback table:表闪回;用于数据表恢复;数据表误删。 3)flashback query:闪回查询;应用于修复误操作数据。此处可以参考德哥的文章,PostgreSQL中的一系列闪回方法:PgSQL 应用案例 PostgreSQL flashback(闪回) 功能实现与介绍
6.后话
可以看到,数据库为什么会丢失数据有诸多原因,包括人为的、硬件故障还有本身数据库的复杂实现,这还不算上分布式数据库要实现的那一套CAP、BASE理论,所以对于PostgreSQL来说,备份一定是重中之重,也是最简单粗暴有效的方式。若备份因为种种原因失效了,那么还有各种各样的强大工具供我们使用,如walminer、pg_fix、回收站等等。
- 发表于 2021-04-03 23:45
- 阅读 ( 32 )
