实施分布式数据库的 “正确姿势”
为什么需要分布式数据库
是因为数据量太大吗?
对于OLAP应用来说,或许是这样的,但对OLTP来说,数据量通常不是
问题。
例如全国14亿,无论男女老幼,每人申请10个支付宝帐号,也才总共
14...
为什么需要分布式数据库
是因为数据量太大吗?
对于OLAP应用来说,或许是这样的,但对OLTP来说,数据量通常不是
问题。
例如全国14亿,无论男女老幼,每人申请10个支付宝帐号,也才总共
140亿行记录。140亿行记录的数据量,可以算是大表,但并没有大到
一定要分布式才能存储。而事实上支付宝的核心数据库是由几十节点
数据库组成的一套分布式数据库。
为什么需要分布式数据库
Ø硬件能力:单机处理能力有限。
Ø软件瓶颈:数据库软件程序遇到竞争。
硬件能力
以整机256核的服务器来算,每个事务假设需要20ms(0.02秒),一个核心
每秒处理50个事务,256核就是256*50,整机每秒共能处理12800个事务。
而双11时峰值事务数达每秒数万笔事务。已经超出了单台服务器的峰值,
因此,分布式是必然的解决方案。
软件瓶颈
软件瓶颈并不是指程序写的不好、不够优化。目前主流的NoSQL、关系数
据库,软件代码的优化方面,都是做的非常好的。
我这里所说的“软件瓶颈”,主要指并发控制机制。
并发控制机制,就如同一个城市的交通体系。并不是一味的路宽,就能减
少阻塞。比如繁忙的十字路口,路再宽,对于减少阻塞帮助不大,不如修
建立体交通(立交桥),这样南来北往互相不再阻塞。



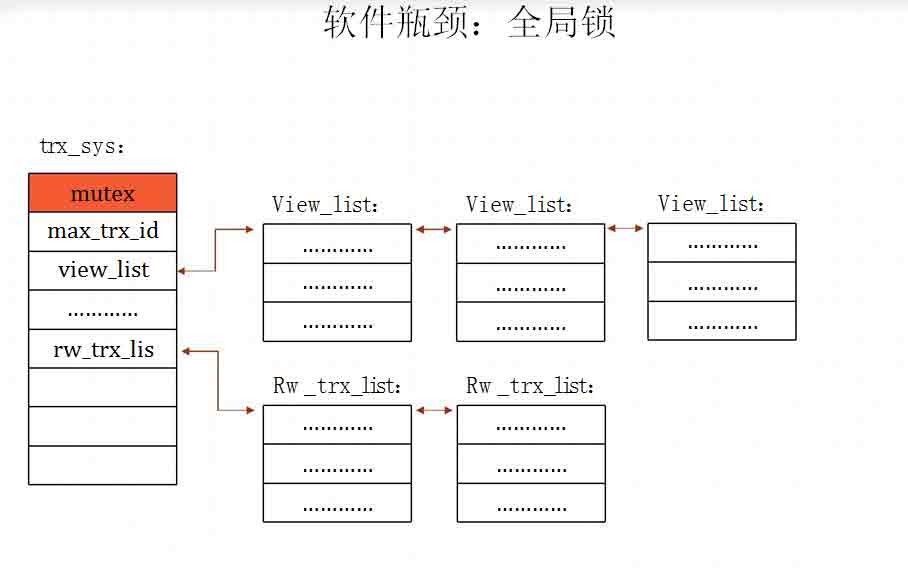
软件瓶颈:全局锁
软件瓶颈:MySQL全局锁举例
全局锁,就是一旦某个进(线)程持有,其他进(线)程的同类操作全部
被阻塞。
看一个数据库并发机制的好坏,就看它的全局锁数量和持有时间。全局锁
越少、持有时间越短,并发机制就越好,并发性越高
在代码层面,全局锁其实是一个全局变量,以trx_sys为例,可以在
storage/innobase/include/trx0sys.h中,找到它的声明:
/** The transaction system */
extern trx_sys_t* trx_sys;
“extern”声明它是一个全局变量。在事务开始时,线程要增加trx_sys中的max_trx_id,和设置
trx_sys中的view_list。
因为trx_sys是一个全局结构变量,所有线程共享一份,因此它的改变要在它的全局锁保护下完成。
保护它的全局锁就是下面红字显示的“Mutex”。
(同样是在trx0sys.h中,可以找到trx_sys_t结构的原型:)
603 struct trx_sys_t{
604
605 ib_mutex_t mutex; /*!< mutex protecting most fields in
606 this structure except when noted
607 otherwise */
608 ulint n_prepared_trx; /*!< Number of transactions currently
609 in the XA PREPARED state */
…………
软件瓶颈:MySQL全局锁举例
软件瓶颈:MySQL全局锁举例
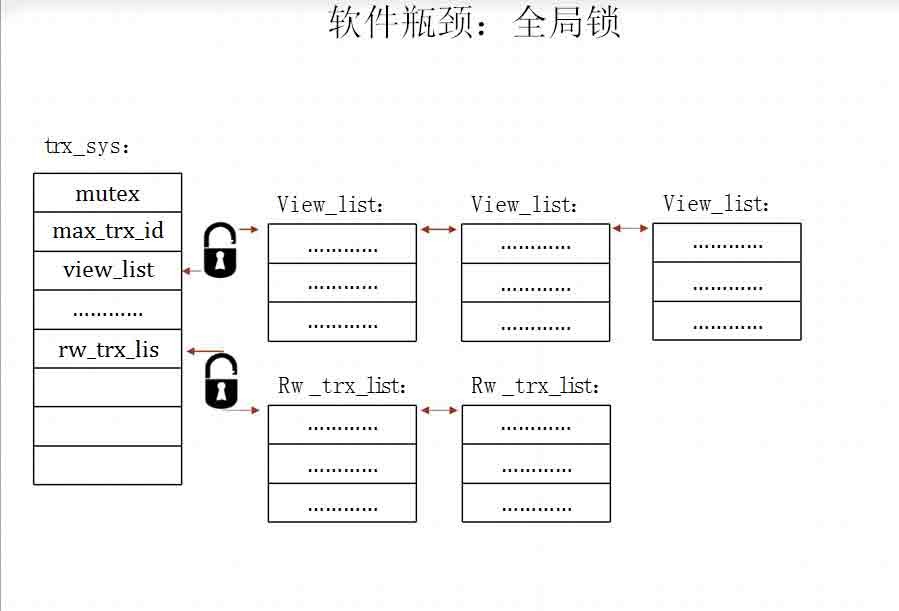
以事务开始时设置trx_sys中的view_list为例,这段示例代码在
storage/innobase/read/read0read.cc中,read_view_open_now_low函数的主要作用是设置
trx_sys中的view_list。
386 mutex_enter(&trx_sys->mutex);
387
388 view = read_view_open_now_low(cr_trx_id, heap);
389
390 mutex_exit(&trx_sys->mutex);
在read_view_open_now_low函数之前,mutex_enter函数设置全局锁trx_sys->mutex。
这将阻塞MySQL中所有涉及事务的操作,对innodb引擎来说,基本上就是阻塞所有操
作了。read_view_open_now_low函数之后的mutex_exit是释放Mutex。哪么这个函数
通常会耗用多长时间呢?
软件瓶颈:MySQL全局锁举例
SYSTEM TAP测试脚本:
1 #!/usr/bin/stap
2
3 global mutex_time, mutex_cycle;
4
5 probe begin {
6
printf("Begin.\n");
7 }
8
9 probe process("/usr/local/mysql/bin/mysqld").statement("read_view_open_now@read0read.cc:387") {
10
11
mutex_time=gettimeofday_us();
mutex_cycle=get_cycles();
12 }
13
14 probe process("/usr/local/mysql/bin/mysqld").statement("read_view_open_now@read0read.cc:389") {
15
printf("hold time:%d, hold cycle:%d \n",
gettimeofday_us()-mutex_time, get_cycles()-mutex_cycle);
16 }
在我的测试机中,以Select操作为例,read_view_open_now_low函数将耗时35微
秒左右,8、9万个指令周期。
应用题:从甲地到乙地必须经过路口A。路口A每次只能通过一个人,每次穿过路
口A需耗时35微秒。问:每秒最多可以有多少人从甲地到乙地。
不考虑其他路段所耗时间,28571人次。
软件瓶颈:全局锁
软件瓶颈:全局锁
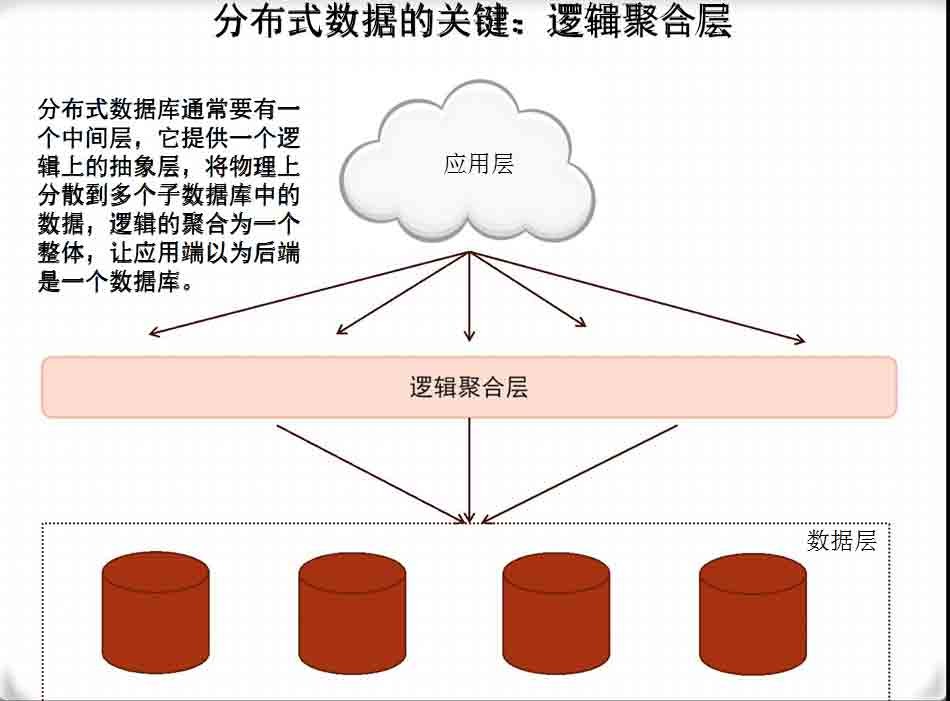
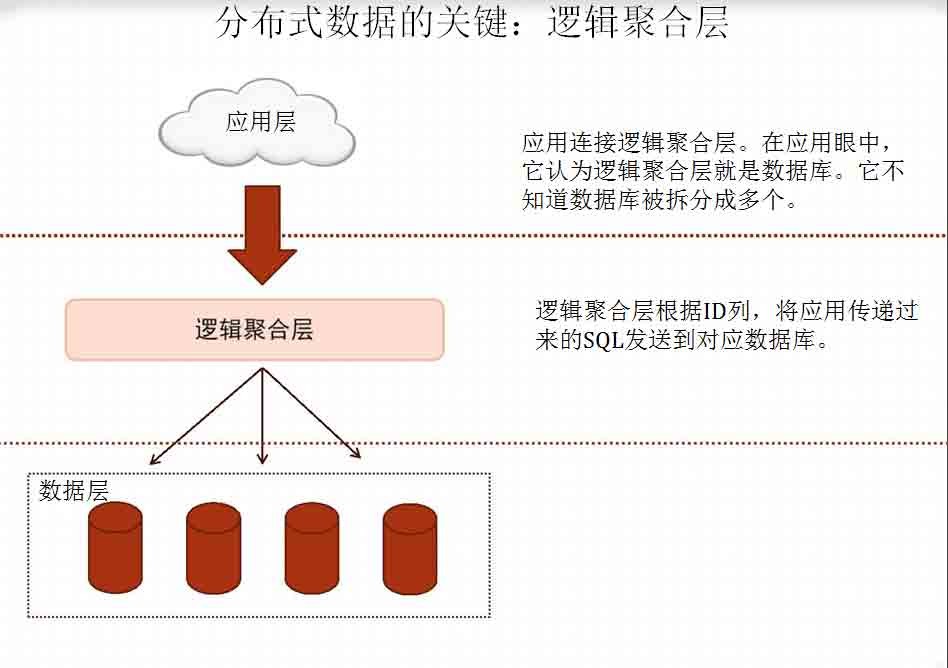

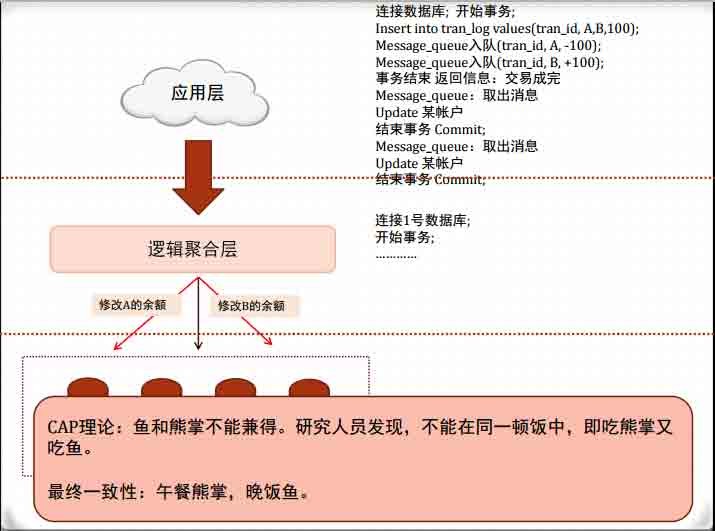
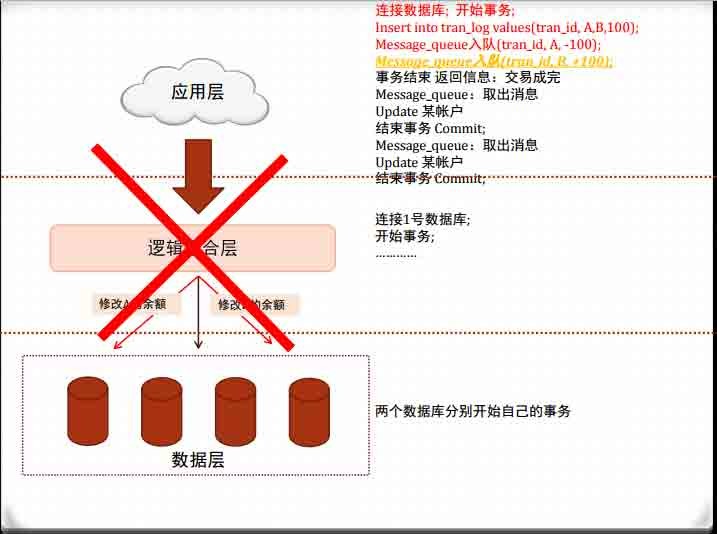
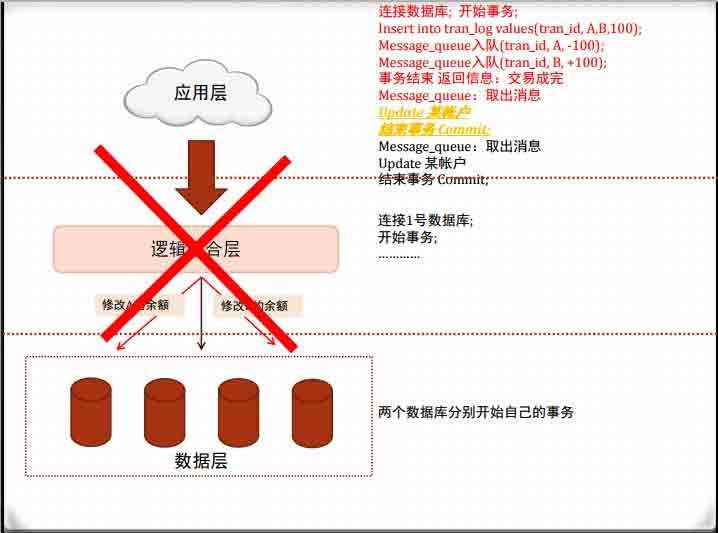
 分布式数据的关键:逻辑聚合层
分布式数据的关键:逻辑聚合层


 节约成本的方法:适当分布式
节约成本的方法:适当分布式
节约成本的方法:适当分布式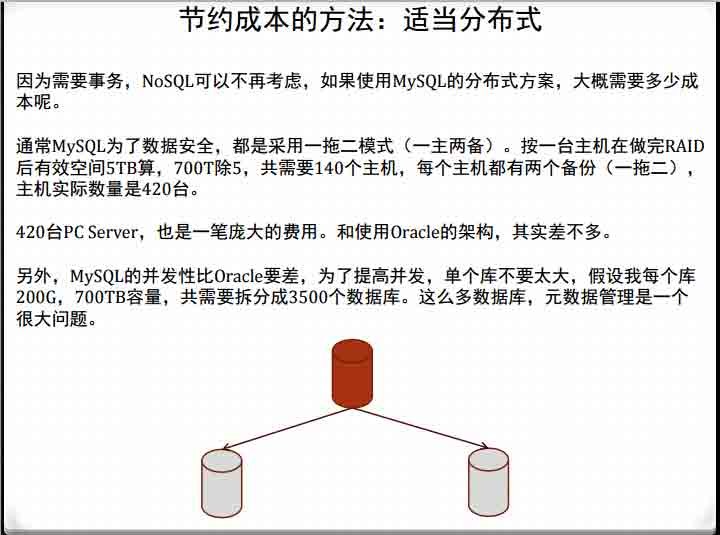
测试结果是在我自己的个人电脑上得到的,但即使是高端PC Server服务器,也不会比
这个结果快多少。
高端服务器的优点是核多、核间通信效率高、L1等CACHE多,等等。在大数据量、高
并发环境下,高端服务器优势明显,如果只是衡量单线程下一个简单的C++函数的执
行时间,高端服务器比我的个人电脑也快不了多少。
而且,Select在执行时,并不是只有这一处全局锁。单说trx_sys变量,还有一次全局
锁操作,就是在“trx_start_if_not_started”函数中,将trx_sys中的事务ID加1时。
另外在SQL解析期间、逻辑读期间、事务结束期间,都需要全局锁。
相比之下, Oracle普通的Select和DML全局锁非常少,只在硬解析时会持有少数全局
锁,软解析和软软解析时没有全局锁。
Oracle的整个事务流程中,没有一处全局锁。比如事务ID,MySQL有一个“最大事务
ID”,是一个保存trx_sys中的整数。每个线程开始事务时,要在全局锁的保护下,将
这个最大事务ID加1,得到的新值就是此新事务的ID。
Oracle的事务ID不是一个整数,它是根据事务所占空间计算得到的,因此“得到事务
ID”的过程,不需要像MySQL哪样在全局Mutex锁的保护下进行。
软件瓶颈
并发机制是为了避免竞争,但无论多么复杂的
并发机制,都无法避免所有的竞争。
仍以交通为例,避免竞争的最好方式,是减少
车流量。如果把一个杭州分成十个、一百个杭
州,交通拥堵的情况,将大大改善。
因此,分布式是解决“软件瓶颈”的最佳选择。
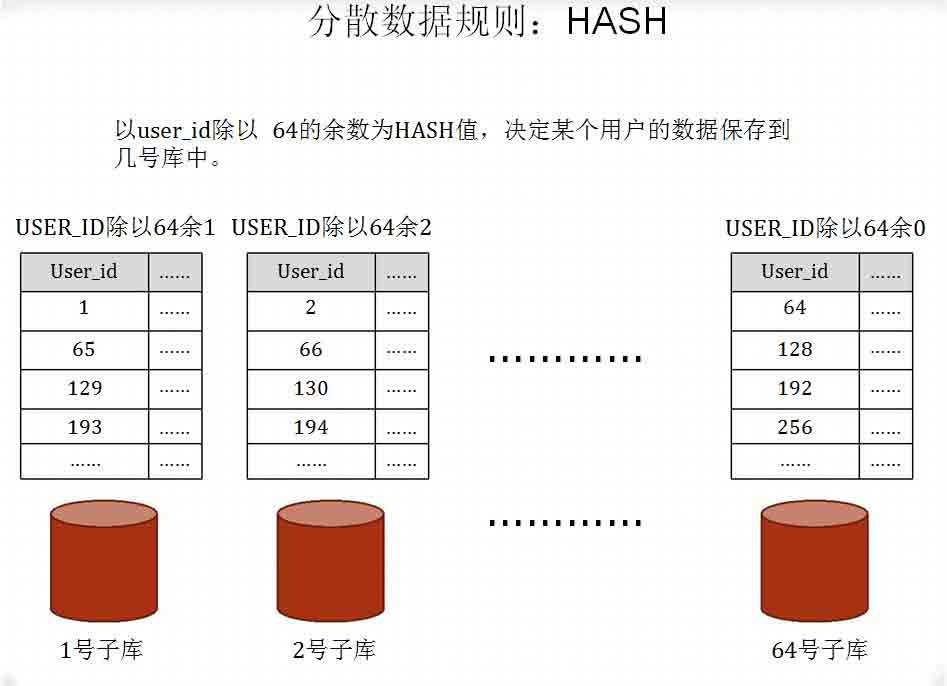
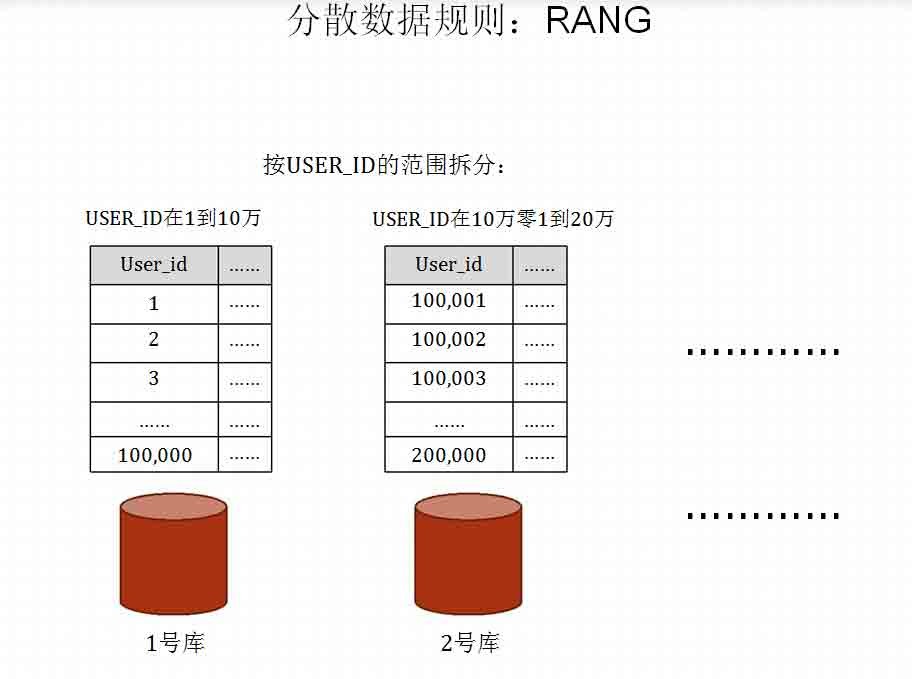
分布式数据库的一般方法:分散数据
分布式数据库本质上就是将数据分散存储。简单点说,就是将一张表分散
存储到多个数据库中。这种技术在数据库界有一系列专门的名词:Database
Sharding、horizontal partitioning/horizontal split、拆表、分表等等。
分布式数据库的一般方法:分散数据
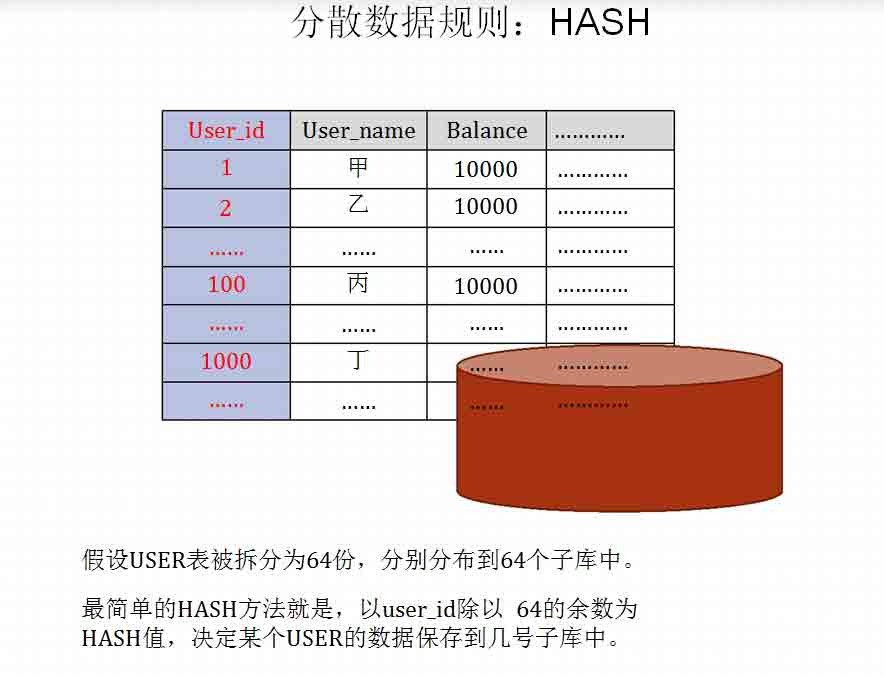
分布式数据库的实现方法,就是根据某种规则,将数据分散存储。分散规则总结来说有
以下三种:
• HASH
• RANG
• 路由库
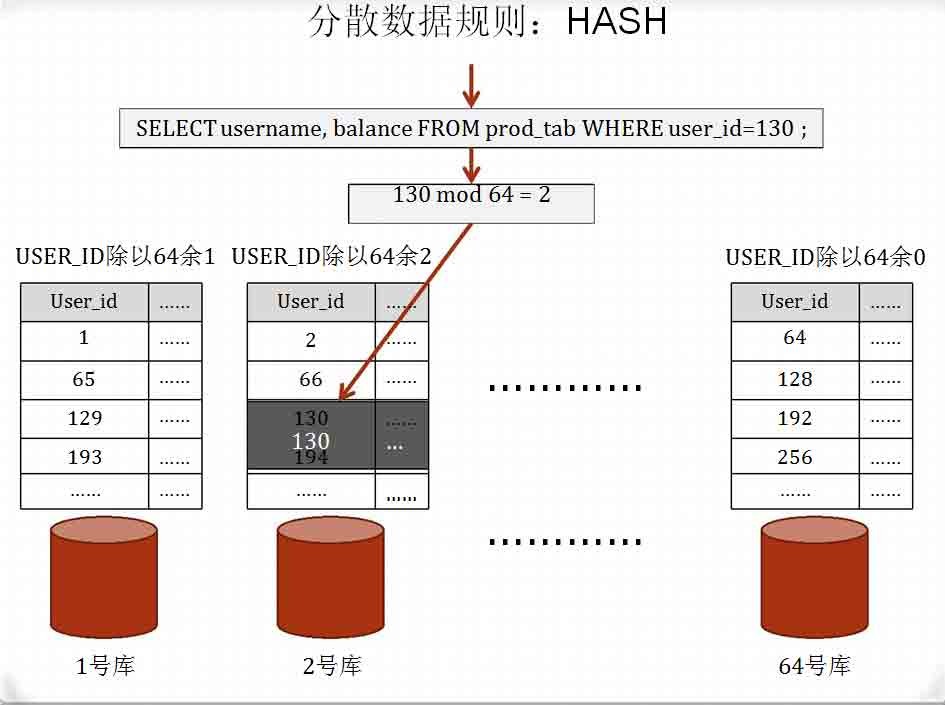
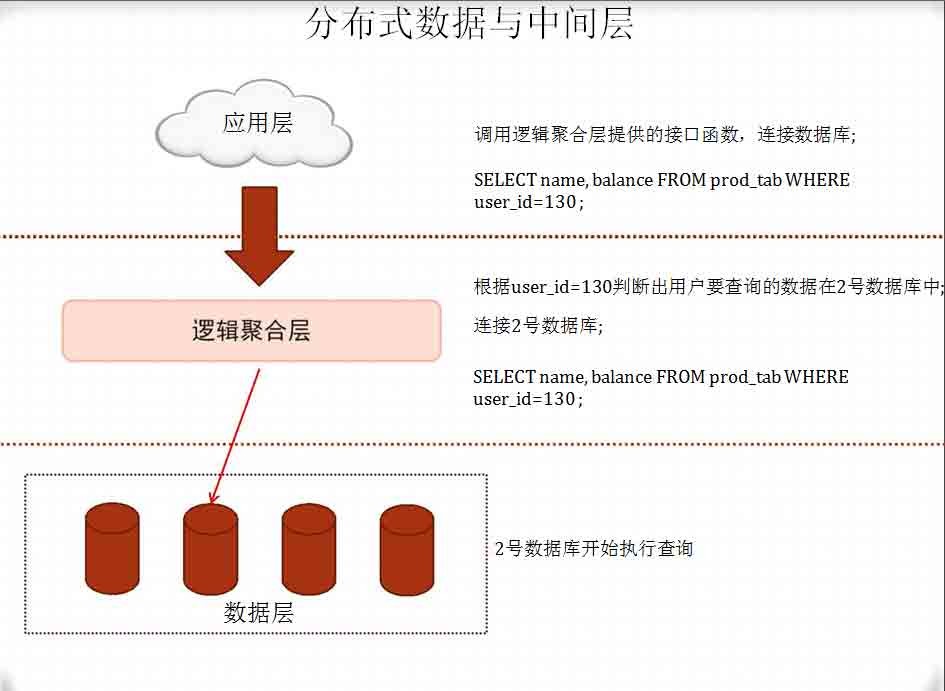
分散数据规则:路由
将USER_ID的分布法则写到一张表中,每次访问数据时,比如要查询
USER_ID为130的行,先查询路由表,得到130存在哪个库中,再去到指
定库中查询
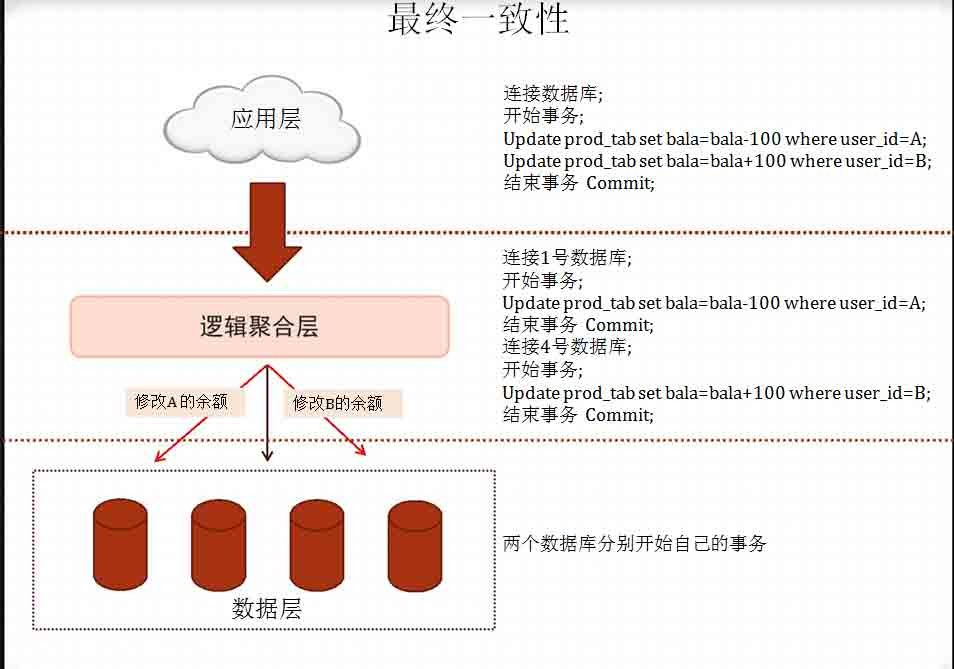
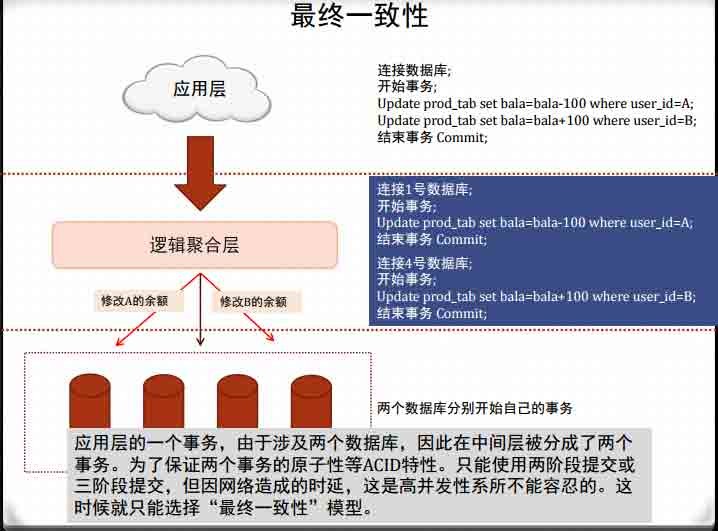
分布式数据的关键:逻辑聚合层逻辑聚合层的实现技术有很多种,最简单的就是JDBC外包一层,或者在
数据库的监听程序外包一层。
无论哪种实现方式,在处理查询、和只包含一条DML语句的事务时,逻
辑都是简单的,但处理多条DML的事务时,就比较复杂了。
比如支付操作,A向B支付100块钱:
事务开始
Update prod_tab set bala=bala-100 where user_id=A;
Update prod_tab set bala=bala+100 where user_id=B;
Commit;
节约成本的方法:适当分布式分布式大大增加了系统的复杂程度,过度的分布式反而有可能增加成本。
我们有一套700T的OLTP库,不使用分布式时,700T数据还在一个数据库中,无论容量
还是性能,都会有问题。
我们选择的分布式方案,使用SUN SPACK主机,全闪存存储,加上Oracle数据库。所有
数据分为近30个子Oracle数据库存储。
SPACK主机优点是单机CPU核心多,可以达到单机512核。按每核心20ms处理一个事务
算的心,单机一秒可处理25600笔事务。
Oracle数据库,是并发机制做的最好的数据库,可以最大程度上减少软件瓶颈对性能的
影响。
30个左右的子库,虽然也是分布式,但分布的不算多,管理成功并不高。30台SUN
SPACK主机,700TB存储空间,成本也只是千万级别。Oracle license费用,当有如此数
据规模时,License费用好商量的。
节约成本的方法:适当分布式
分布式是可以解决扩展性和性能&容量问题,但适当分布式,才能真正节省成本、减少
工作量。
- 发表于 2016-08-22 23:53
- 阅读 ( 482 )
