strace排查nginx+php-fpm性能问题
php+nginx 中有时候 close系统调用消耗很高,这种问题,解决的时候非常棘手,日志对解决这种问题帮助有限,我们这次通过strace 这个追踪系统栈调用的工具来出一种解决此类问题的思路
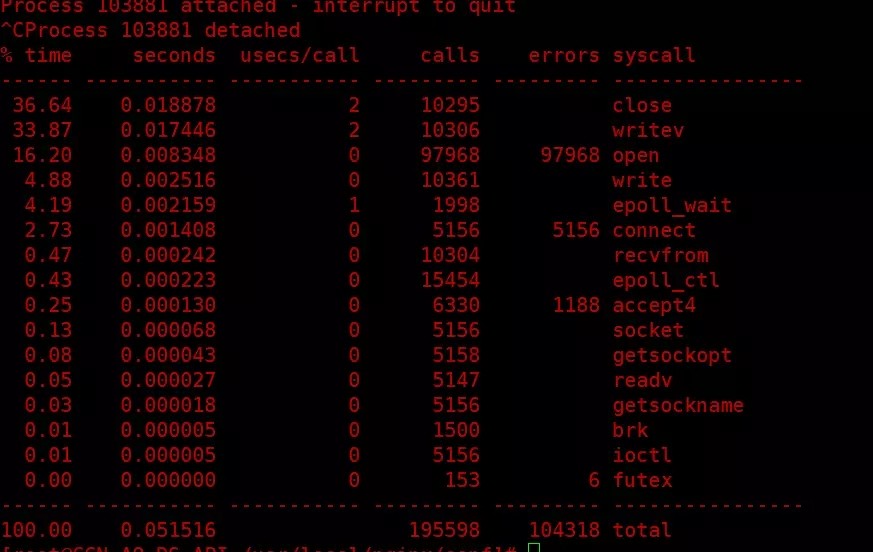
1,$ strace -cp $(pgrep -n nginx)
$ top
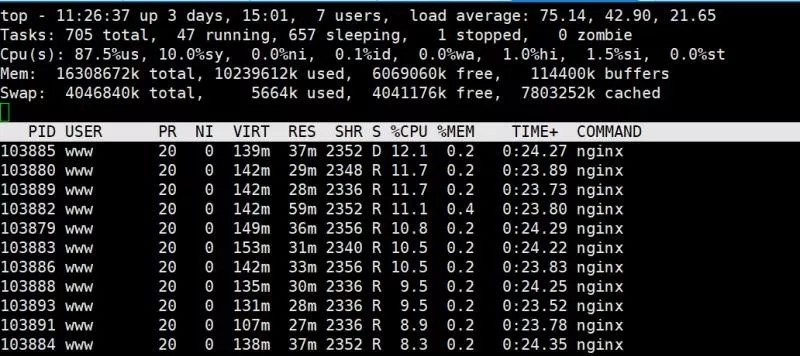
系统32c的,top查看负载去到75.14,
查看过nginx和php-fpm的
错误日志也没有什么发现。
strace 跟踪close的系统调用,
都是以下的信息:
$ strace -T -ttp $(pgrep -n nginx) 2&>1 |grep -B 10 close > ./close.log

$ lsof | more
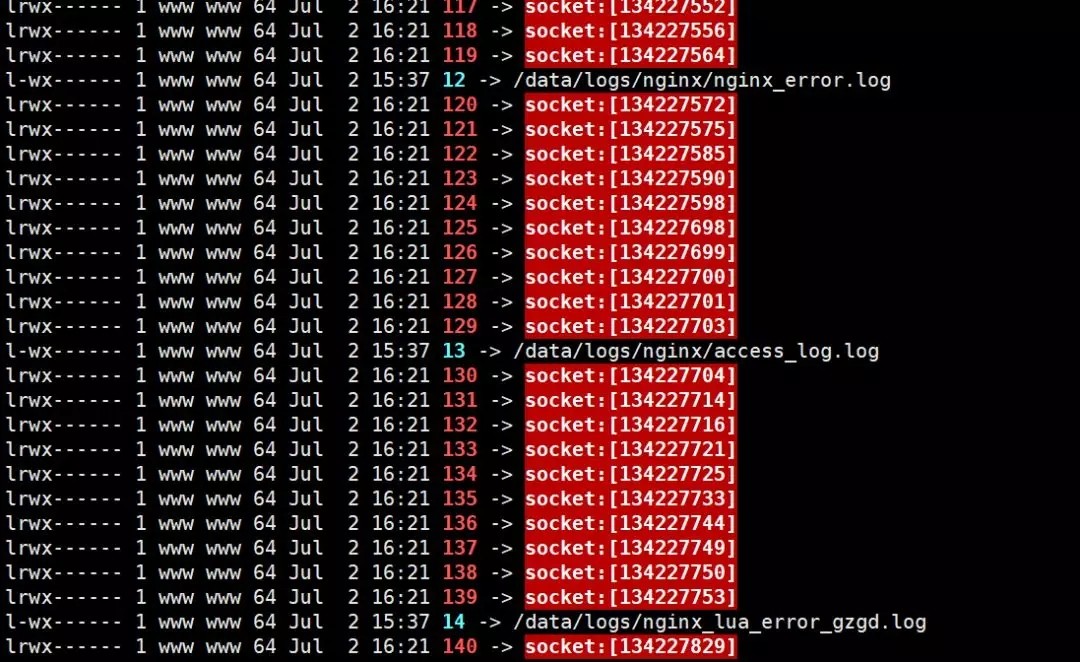
遂怀疑是连接创建关闭消耗了太多的资源,便加了台机器专门跑nginx,
前端挂了个nginx用长连接跟后端的nginx连接,接了个nginx之后负载果然就下来了。
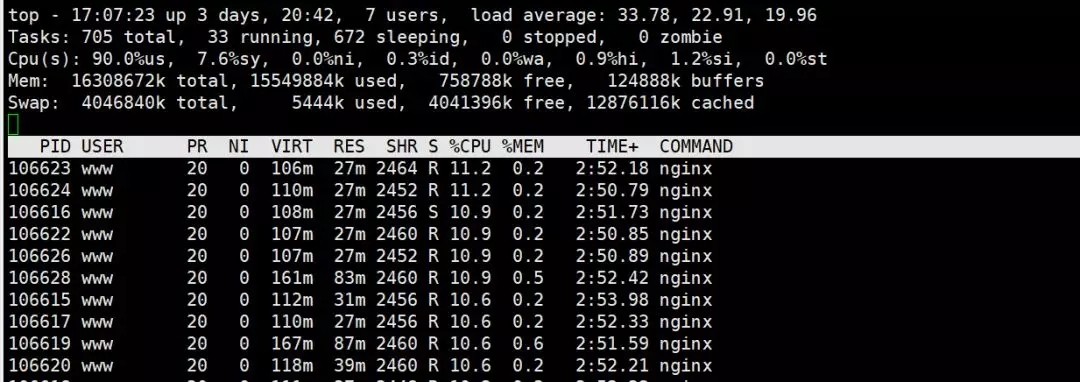
前端未挂nginx压测ab压测结果:
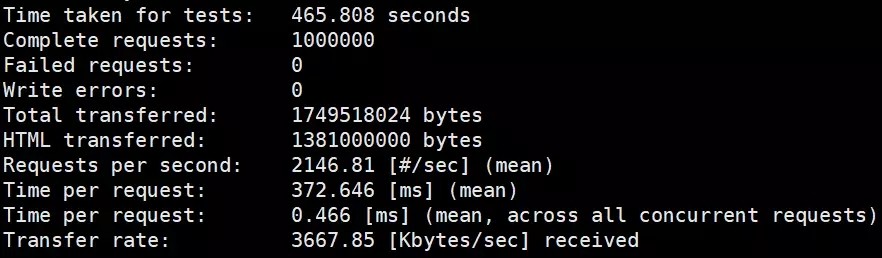
前端挂了nginx压测ab压测结果:
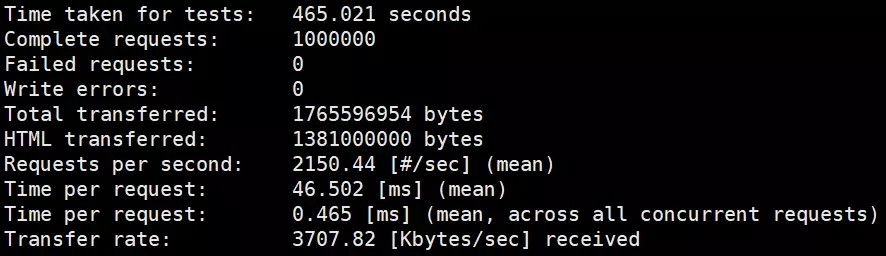
tps基本没变第一个Time per,requset快了87.52%。
接着继续排查tps上不去的原因,继续strace后端的nginx。
$ strace -cp $(pgrep -n nginx)
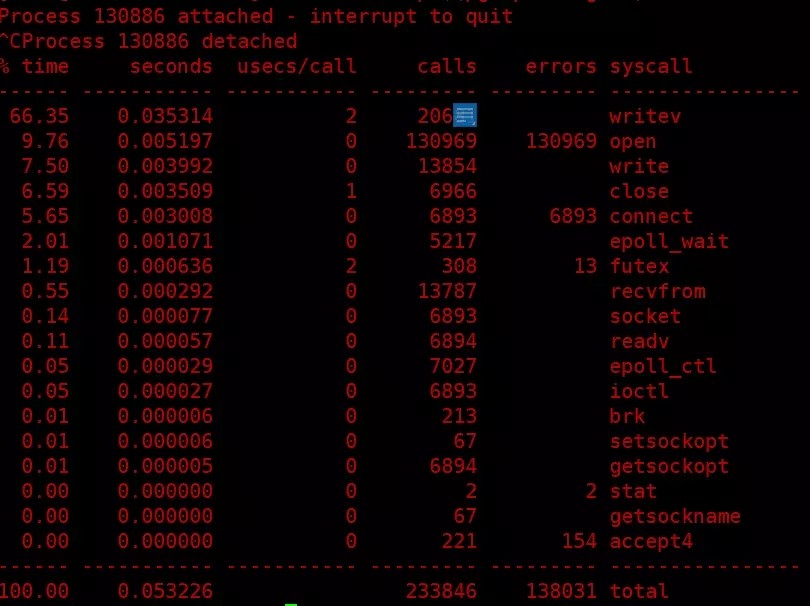
发现现在是wrtiev占用高了,strace 跟踪close的系统调用,
发现很多以下的输出:
connect(26, {sa_family=AF_INET,
sin_port=htons(9000),
sin_addr=inet_addr("127.0.0.1")},
16) = -1 EINPROGRESS
(Operation now in progress)
问题应该不是在nginx上,
应该是在php-fpm上了。
继续
$ strace -cp $(pgrep -n php-fpm)
显示下图所示:
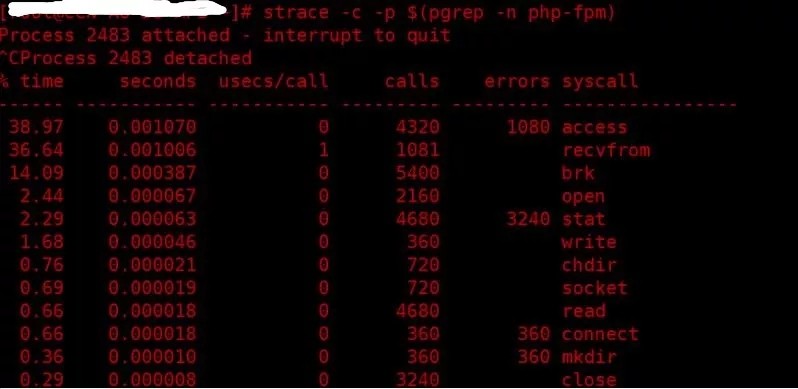
access cpu时间消耗最多那就先
排查access
系统调用:
$ strace -T -ttp
$(pgrep -n php-fpm) 2&>1 |
grep -B 10 access >
./access.log
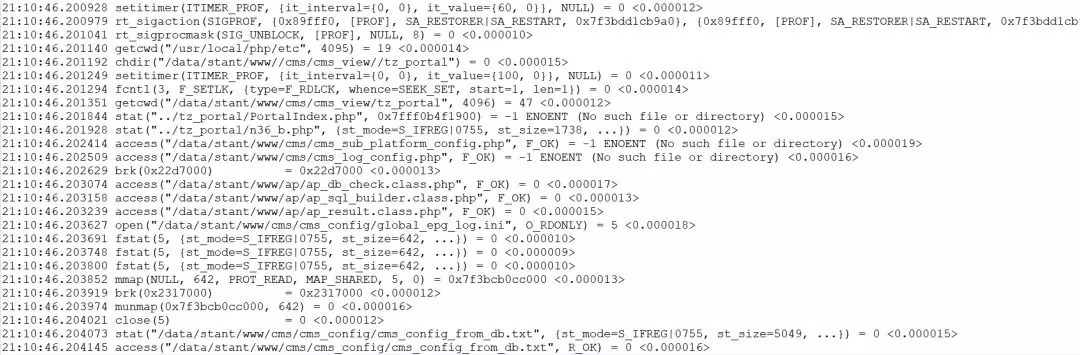
php-fpm进程频繁的去读取文件,整个操
作下来花费4ms的时间。
然后排查recvfrom:
$ strace -T -ttp $(pgrep -n
php-fpm) 2&>1 |
grep -B 10 recvfrom >
./recvfrom.log

频繁的去访问10.0.0.156的6379,端口,明显就是访问redis读取数据的过程,
整个过程花费12ms。
让小明把上面两个strace信息发给开发,第一个得到回复是老版本的流程,
新版本改了,但还是有些判断没有处理。
第二个问题让开发使用redis连接池,无需频繁创建连接读取数据,
频繁创建连接开销很大的
保存strace 到文件 使用 -o strace -o dd.txt -T -ttp $(pgrep -n php-fpm) -s 200 2>&1
总 结
当遇上性能问题时,排查日志无法解决时,使用strace工具来查看一下系统调用,看时间到底消耗在哪里了,有可能会有意想不到的效果
- 发表于 2018-07-19 13:02
- 阅读 ( 77 )
