今早经历的职业生涯中最大的一次冒险
最近几天因为睡眠严重缺乏,也使我忘记了“疲劳不上机的”的运维戒条,尤其是数据库的运维,偏偏这两者一起发生了,这次经历应该是终身难玩的,也是我认识到使一个公司瞬间灰飞烟灭是多么轻而易举的事情。
事情经历是这样的,公司最主要的一台数据库服务器的主从同步出现问题,为了解决问题,我从主服务器上通过
innobackupex --user=root --password=****** --socket=/webdata/opt/local/mysql/misc/mysql.sock - --parallel=1 /webdata/hotbak/ 热复制了一份数据,
innobackupex --apply-log --redo-only /webdata/hotbak
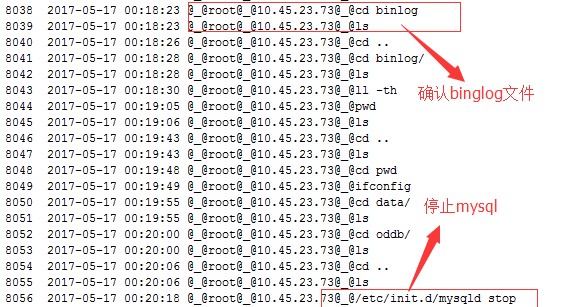
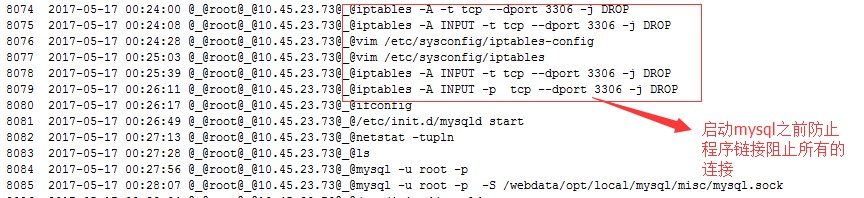
数据大小为480G左右,然后通过网络传输到从服务器上,数据传输完成大概在17日凌晨左右,我零点15分左右开始操作从服务器,应为数据太大,我本意是删除从上服务器上面的数据库,然后把复制过来的数据补上,但惊心动魄的事情就出现这这里,我本意在从上面的 rm -rf data/ 操作,因为极度疲惫,鬼使神差的在主服务器上面执行了,My God~ 年初GitLab的一幕在我这里copy了一遍,1s过来我反应过来,ctrl+C取消后,几个库只剩下,FDDB,ODDB,其他的近300G的数据消失得干干净净,看着自己的“成果”,我脑子足足有2s的时间是空白的,心想,这下子全完了,全完了! 不过很快我平静下来,我下午四点多的时候刚复制了一份全备,然后以最快的速度看了下binlog目录,还好,binlog文件都在,因为时间间隔不长,我的全备之后的文件都在一个binlog文件:master-000139 里面。我接下来马上做的一件事情是,关闭mysql,备份binlog文件夹。为了保险,我把全备文件也复制了一份,还好是半夜里,为了应付老板,我谎称了是数据备份出了问题,mysql需要停机一个半小时,似乎,天地人和都占了,这就减少了我不少压力。把全备文件copy了一份之后,时间已经来到1:50左右,剩下的就是恢复数据库,开始的时候还是走了弯路,思路是一个数据库一个数据库恢复,因为还有oddb和fddb没有删除,数据似乎也是完整的,我天真的以为,只要把这两个库文件copy到data目录覆盖原来的,就可以把这两个库完好的恢复,结果因为ibdata1 (表空间和redo,undo)不一致,启动失败,其实只要 frm,和idb(innodb-file-per-table=1)文件是可以通过工具找回数据的,具体见:https://wenda.zuncuang.com/article/153
我这里是不可能通过这种方法找回数据库的,在这里浪费了一个小时的时间,最后还是回到了,通过全备+binlog的方式恢复,在分析binlog的时候,我发现binlog里面的数据是按顺序写入的,和数据库都少没有关系,也就是说,如果fddb数据库中给一个表比如:fd_transactions_result 表中最新的一条数据的时间为:16:59:43秒,也就是说,只要一个表在这个时间点有数据,其他的任何库,任何表的数据,在16:59:43之前全备上面都是有的,剩下的就是找到全部库最后一条在binlog中的记录,这个记录的下一个位置就是我们开始恢复的起始点位置,在这个上面我也是走了不少弯路,浪费了很多时间,最后找到了这个--start-position=547468087,使用下面语句进行了恢复:
mysqlbinlog --start-position=547468087 master-bin.001939|mysql -u root -p -S /webdata/opt/local/mysql/misc/mysql.sock
事情经过如下:





又回到到最初的想法,通过全备+binlog恢复



其实找到这个开始恢复点,innobackupex恢复的文件中已经有了,这个恢复点就是在: xtrabackup_binlog_info 中间,一秒钟可以搞定的事情,还是费了这么多时间,哎,
再次提醒:疲劳不上机,上机保持清醒,尤其对重要的数据库,一个公司重要资产,有时候甚至是全部资产,千千万万小心,要让一个公司灰飞烟灭,只需一个 rm -rf :-)
- 发表于 2017-05-17 16:38
- 阅读 ( 78 )
