再说MySQL中的 table_id
文章一:
【背景】
最近线上一个实例出现了主从数据不一致的情况,也即从库丢失数据的情况。根本原因:"由于table_list->table_id为uint,而m_table_id为ulong,主库上assign的table map id 总是一直递增的
当超过2^32后,备库出现溢出,导致row模式下备库对应table id的事件全部丢失,产生主备不一致。"
【问题分析】
一 table_id 介绍
当MySQL 开启日志模式时,binlog会记录所有对数据库的变更操作。binlog 分两种模式 statement 模式和row 模式。
当数据库的binlog format 是statement 模式时
例子:数据库中执行 一条语句
root@rac2 [yangyi]> insert into t1 values(9);
Query OK, 1 row affected (0.00 sec)
root@rac2 [yangyi]> show binlog events in 'mysql-bin.000003';
+------------------+-----+-------------+-----------+-------------+----------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+------------------+-----+-------------+-----------+-------------+----------------------------------------+
| mysql-bin.000003 | 4 | Format_desc | 2 | 106 | Server ver: 5.1.68-log, Binlog ver: 4 |
| mysql-bin.000003 | 106 | Query | 2 | 176 | BEGIN |
| mysql-bin.000003 | 176 | Query | 2 | 265 | use `yangyi`; insert into t1 values(8) |
| mysql-bin.000003 | 265 | Xid | 2 | 292 | COMMIT /* xid=12 */ |
| mysql-bin.000003 | 292 | Query | 2 | 369 | use `yangyi`; flush tables |
| mysql-bin.000003 | 369 | Query | 2 | 439 | BEGIN |
| mysql-bin.000003 | 439 | Query | 2 | 528 | use `yangyi`; insert into t1 values(9) |
| mysql-bin.000003 | 528 | Xid | 2 | 555 | COMMIT /* xid=15 */ |
+------------------+-----+-------------+-----------+-------------+----------------------------------------+
8 rows in set (0.00 sec)
binlog 的log event 记录如下:
#140511 14:44:12 server id 2 end_log_pos 439 Query thread_id=1 exec_time=0 error_code=0
SET TIMESTAMP=1399790652/*!*/;
BEGIN
/*!*/;
# at 439
#140511 14:44:12 server id 2 end_log_pos 528 Query thread_id=1 exec_time=0 error_code=0
SET TIMESTAMP=1399790652/*!*/;
insert into t1 values(9)
/*!*/;
# at 528
#140511 14:44:12 server id 2 end_log_pos 555 Xid = 15
COMMIT/*!*/;
从日志分析来看 ,DML会记录为原始的SQL,也就是记录在QUERY_EVENT中。
当数据库的binlog format 是row模式时
执行insert 操作
root@rac2 [yangyi]> insert into t1 values(6);
Query OK, 1 row affected (0.00 sec)
root@rac2 [yangyi]> show binlog events in 'mysql-bin.000002';
+------------------+-----+-------------+-----------+-------------+---------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+------------------+-----+-------------+-----------+-------------+---------------------------------------+
| mysql-bin.000002 | 4 | Format_desc | 2 | 106 | Server ver: 5.1.68-log, Binlog ver: 4 |
| mysql-bin.000002 | 106 | Query | 2 | 176 | BEGIN |
| mysql-bin.000002 | 176 | Table_map | 2 | 219 | table_id: 18 (yangyi.t1) |
| mysql-bin.000002 | 219 | Write_rows | 2 | 253 | table_id: 18 flags: STMT_END_F |
| mysql-bin.000002 | 253 | Xid | 2 | 280 | COMMIT /* xid=61 */ |
+------------------+-----+-------------+-----------+-------------+---------------------------------------+
5 rows in set (0.00 sec)
binlog中记录的信息:
BEGIN
/*!*/;
# at 176
# at 219
#140511 14:31:43 server id 2 end_log_pos 219 Table_map: `yangyi`.`t1` mapped to number 18
#140511 14:31:43 server id 2 end_log_pos 253 Write_rows: table id 18 flags: STMT_END_F
BINLOG '
TxlvUxMCAAAAKwAAANsAAAAAABIAAAAAAAEABnlhbmd5aQACdDEAAQMAAQ==
TxlvUxcCAAAAIgAAAP0AAAAAABIAAAAAAAEAAf/+BgAAAA==
'/*!*/;
### INSERT INTO `yangyi`.`t1`
### SET
### @1=6 /* INT meta=0 nullable=1 is_null=0 */
# at 253
#140511 14:31:43 server id 2 end_log_pos 280 Xid = 61
COMMIT/*!*/;
从解析的binlog中可以看出row模式下,DML操作会记录为:TABLE_MAP_EVENT+ROW_LOG_EVENT(包括WRITE_ROWS_EVENT ,UPDATE_ROWS_EVENT,DELETE_ROWS_EVENT).
为什么一个update在ROW模式下需要分解成两个event:一个Table_map,一个Update_rows。我们想象一下,一个update如果更新了10000条数据,那么对应的表结构信息是否需要记录10000次?其实是对同一个表的操作,所以这里binlog只是记录了一个Table_map用于记录表结构相关信息,而后面的Update_rows记录了更新数据的行信息。他们之间是通过table_id来联系的。
二 table_id 的特性
1 table_id 并不是固定的,它是当表被载入内存(table_definition_cache)时,临时分配的,是一个不断增长的变量。
2 当有新的table变更时,在cache中没有,就会触发一次load table def的操作,此时就会在原先最后一次table_id基础上+1,做为新的table def的id。
3 flush tables,之后对表的更新操作也会触发table_id 的增长。
4 如果table def cache过小,就会出现频繁的换入换出,从而导致table_id增长比较快。
例子
root@rac2 [yangyi]> show binlog events in 'mysql-bin.000002';
+------------------+-----+-------------+-----------+-------------+---------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+------------------+-----+-------------+-----------+-------------+---------------------------------------+
| mysql-bin.000002 | 4 | Format_desc | 2 | 106 | Server ver: 5.1.68-log, Binlog ver: 4 |
| mysql-bin.000002 | 106 | Query | 2 | 176 | BEGIN |
| mysql-bin.000002 | 176 | Table_map | 2 | 219 | table_id: 18 (yangyi.t1) |
| mysql-bin.000002 | 219 | Write_rows | 2 | 253 | table_id: 18 flags: STMT_END_F |
| mysql-bin.000002 | 253 | Xid | 2 | 280 | COMMIT /* xid=61 */ |
| mysql-bin.000002 | 280 | Query | 2 | 357 | use `yangyi`; flush tables |
| mysql-bin.000002 | 357 | Query | 2 | 427 | BEGIN |
| mysql-bin.000002 | 427 | Table_map | 2 | 470 | table_id: 19 (yangyi.t1) |
| mysql-bin.000002 | 470 | Write_rows | 2 | 504 | table_id: 19 flags: STMT_END_F |
| mysql-bin.000002 | 504 | Xid | 2 | 531 | COMMIT /* xid=65 */ |
+------------------+-----+-------------+-----------+-------------+---------------------------------------+
10 rows in set (0.00 sec)
三 table_id在主从复制过程中转变
每一个dml操作表的信息都被会记录table_mapping的hash数据结构中,hash的key就是ulong型的table_id,hash的值就是TABLE*的数据结构(包含了表的各种信息,包括数据库名,表名,字段数,字段类型等),通过set_table()方法来hash,通过get_table()方法来根据table_id获得对应的表信息。
当主库的日志传递到备库时,每一个log_event都是通过do_apply_event()方法来将event应用到本地数据库中。在apply relay log中的event时,do_apply_event()将ulong型的m_table_id(binlog记录的table_id)赋值给RPL_TABLE_LIST结构中的uint型的table_id。核心问题出现了: 如果binlog 中的table_id 的值大于max(uint),在变量传递是,就会发生截断。
而MySQL内部使用set_table(table_id)构造hash,使用get_table(m_table_id)从hash表中取值,在两个阶段用到的key因为发生了数据截断,所以必然也就不能取到预期的值。也就是说之前用uint型的table_id构建出来的key-value的hash对,用ulong型的m_table_id是无法查询到的。
四 风险与解决
从第二,三点我们知道当table_id 过快增长,会导致从库应用binlog无法解析到对应的表,造成数据不一致的情况。
解决方法:
1 加大 table cache 的大小。
2 重启主库使table_id 归0,缺点 成本比较高,出现此问题的时候,主备已经不一致,线上环境 不能完成切换。
3 修改MySQL源码,将 RPL_TABLE_LIST结构中的uint型的table_id修改为ulong型 ,一劳永逸。
文章二:
1. 什么是table_id
MySQL binlog文件按格式分为文件头部和事件信息。文件头部占4字节,内容固定为:"\xfe\x62\x69\x6e",接下来就是各个event了。event有多种类型,比如ROTATE_EVENT对应的记录了binlog切换到下一个binlog文件的信息,XID_EVENT记录了一个事务提交的相关信息。
binlog_format可以设置为statement和row的方式。当设置为statement情况下,DML会记录为原始的SQL,也就是记录在QUERY_EVENT中。而row会记录为TABLE_MAP_EVENT+ROW_LOG_EVENT(包括WRITE_ROWS_EVENT,UPDATE_ROWS_EVENT,DELETE_ROWS_EVENT)。
binlog_format设置为row时,执行一句insert,对应的binlog如下所示:
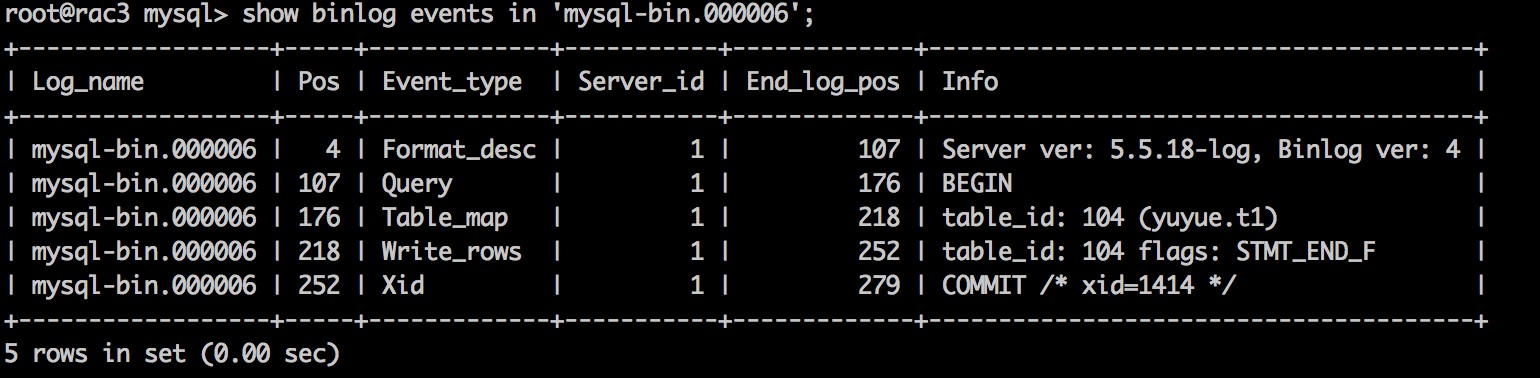
为什么一个insert在row模式下需要分解成两个event:一个Table_map,一个Write_rows?假如一个insert更新了10000条数据,那么对应的表结构信息是否需要记录10000次列?其实是对同一个表的操作,所以这里binlog只是记录了一个Table_map用于记录表结构相关信息,而后面的Write_rows记录了更新数据的行信息。他们之间是通过table_id来联系的。
table_id用来做hash key,通过set_table(table_id)的方法将某个表的信息hash到cache中;又可以通过get_table()方法来根据table_id获得对应的表信息。
要注意table_id并不是固定的绑定在一个表上,它是表载入table cache时临时分配的,一个不断增长的变量。
2. table_id的增长机制
连续往同一个table中进行多次DML操作,table_id不变。 一般来说,出现DDL操作时,table_id才会变化。
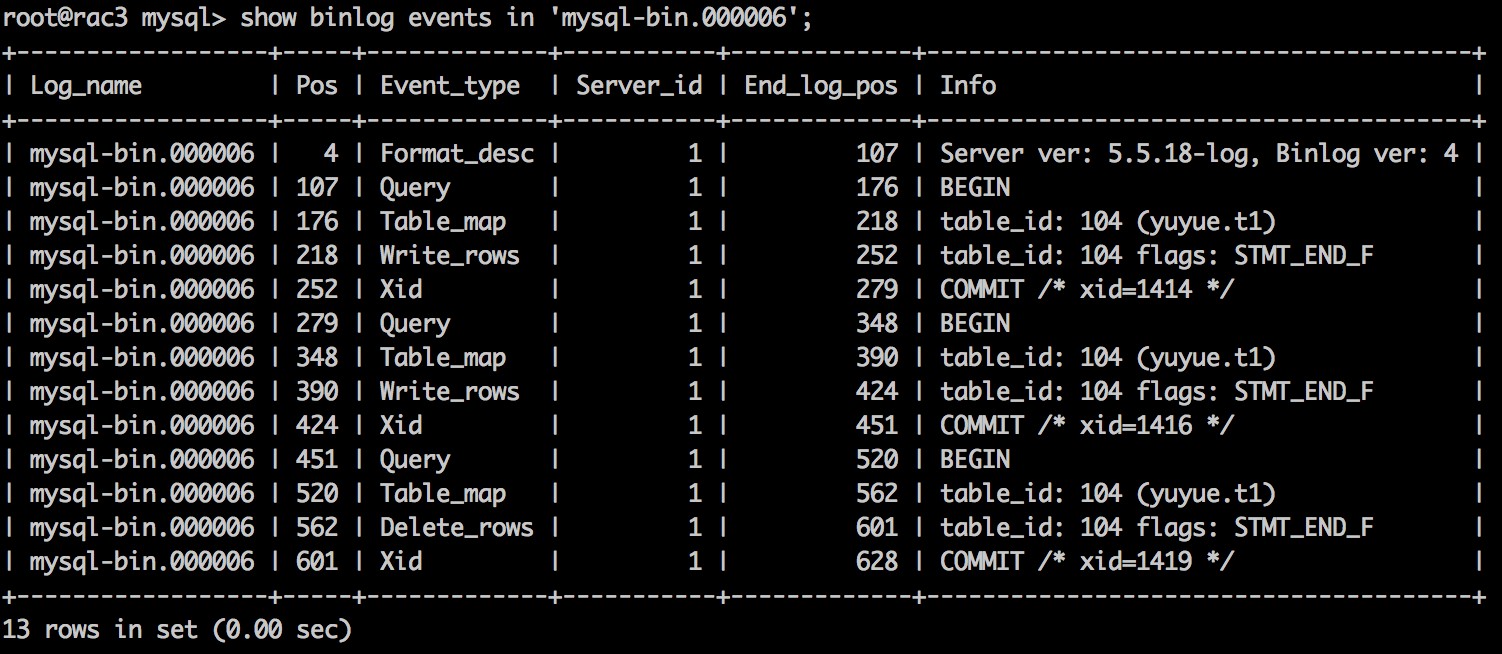
下图中有3个表(t1、t2、t3),执行flush tables,再进行DML操作,每个表的table_id都在增长。
如果表太多,又有频繁的flush tables,会导致table_id增长比较快。
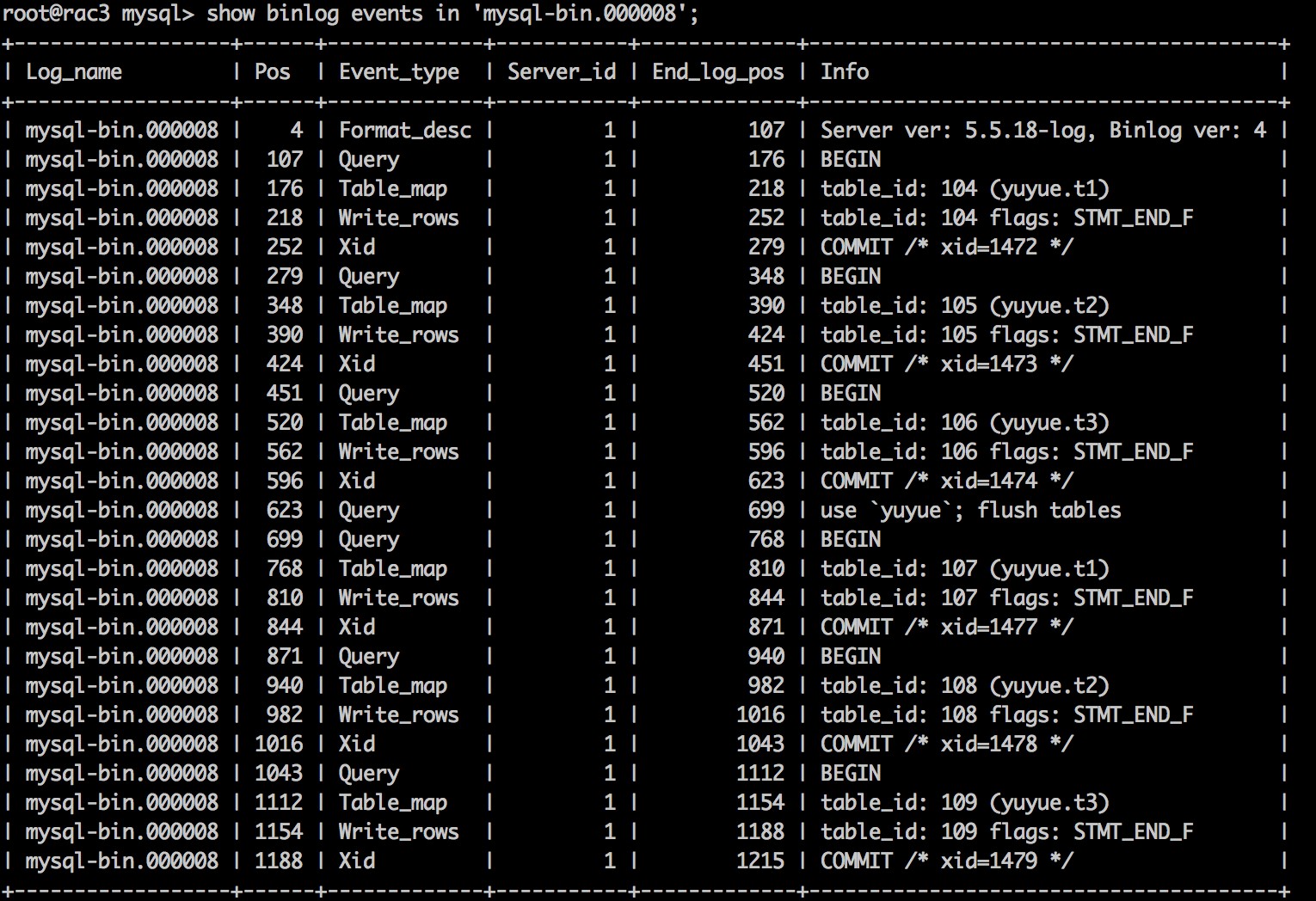
根据MySQL binlog table_id源码分析 ,可以知道:
table id的变化依赖于table cache中是否存储了binlog操作表的表定义。如果table cache中存在,则table id不变;而当table cache中不存在时,该值根据上一次操作的table id自增1。因此,table id与实际操作的数据表没有直接对应关系,而与操作的数据表是否在table cache中有关。此外,table_definition_cache中默认存放400个表定义,如果超出该范围,会将最久未用的表定义置换出table cache。
3. table_id快速增长的风险
binlog中table_id是一个ulong类型(无符号长整形),在slave进行重做binlog events之前,会先将这个ulong的table_id(为了避免混淆,用m_table_id表示)传给一个它内部维护的一个数据结构RPL_TABLE_LIST,这个里面有一个变量table_id用来存储binlog中的m_table_id,问题出现了:数据结构的变量table_id是一个uint(无符号整形),如果m_table_id超过uint的范围会发生截断。而MySQL内部在构造hash,从hash表中取值是这样的做法:set_table(table_id),get_table(m_table_id),在两个阶段用到的key因为发生了数据截断所以必然也就不能取到预期的值。也就是说之前用uint型的table_id构建出来的key-value的hash对,用ulong型的m_table_id是无法查询到的。
具体的源码分析可以参考:淘宝物流MySQL slave数据丢失详细原因
三:案例分析
0、导读
主从复制环境中,IO、SQL线程都很正常,也没设置过滤规则,但数据就是无法复制到slave上,什么原因?
1、问题描述
事实上,这个案例发生已经有一阵子了,一直拖到现在我才整理。
发现一个主从环境中,slave上的io_thread、sql_thread状态均正常,relay log也正常接收来自master的event,但slave上却无法正常应用这些event,个别表数据没有复制过来。而且slave上的binlog也没有记录这些表上的操作。
2、原因分析
接到现场后,第一反应是是先检查是否设置了ignore/do规则,发现并不是这个原因引起的。
我自己手动测试创建了个新的测试表,写了几条数据,发现在slave上这个表能被创建,但写入的测试数据仍旧无法复制过来。这说明,slave上的复制并不是完全失效的,只是有特殊情形下才会失效。
结合上面的问题,想到了可能是因为binlog format以及事务隔离级别等原因导致失效的,于是做了下面的尝试。
//首先修改事务隔离级别为RR(此前是RC),尽可能保证主从数据一致性
root@imysql [mydb]> set session transaction isolation level repeatable read;
//测试写入2条数据
root@imysql [mydb]> insert into z select 5,5;
root@imysql [mydb]> insert into z select 6,6;
经过观察,这2条数据 不可以 复制到slave上。
//修改binlog format为statement(此前是row),再写入2条数据
root@imysql [mydb]> set session binlog_format=’statement’;
root@imysql [mydb]> insert into z select 7,7;
root@imysql [mydb]> insert into z select 8,8;
经过观察,这2条数据则 可以 复制到slave上。
现在至少表面上看起来,是由于binlog format+事务隔离级别综合因素引起的,所以我们来对比下不同binlog format下的binlog有什么区别吧。
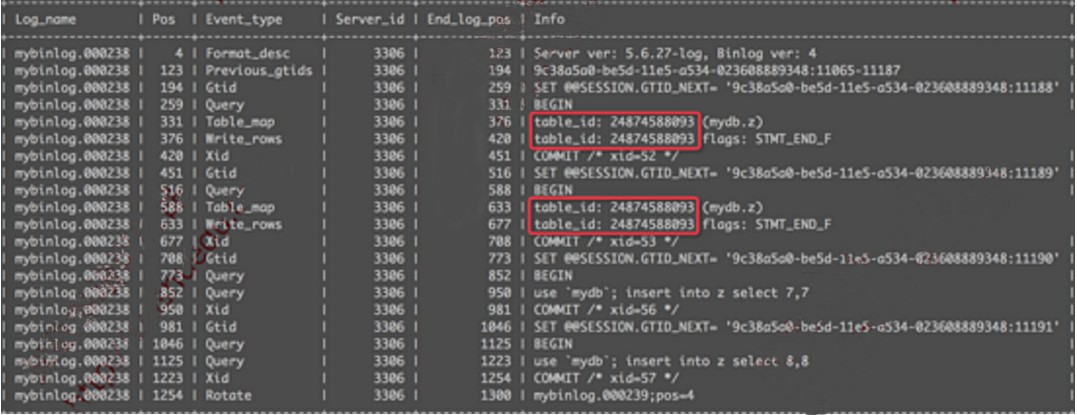
这些日志中,前两条是row模式下的日志,后两条则是statement模式下的。我们注意到红框中内容是: table_id: 24874588093 ,正是由于这个原因导致了slave无法正常复制数据。
正常情况下,row模式下的binlog event应该是这样的:
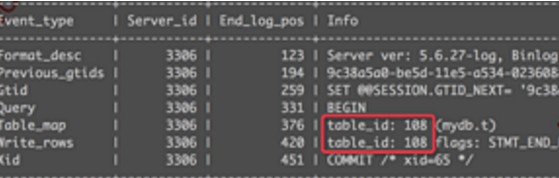
在上面的日志中,我们看到的是: table_id: 108 ,这种情况下就可以正常复制了。
现在问题很明确了,就是由于binlog中table id异常导致无法复制。那么,到底什么原因导致table id出现异常呢。
3、案例建议
搜索了一些资料,发现也有别人遇到同样的问题。我就不多啰嗦了,大家可以看下方参考文章详细了解下。简言之,发生这中问题的原因,主要是因为table cache不够了,导致要频繁打开、关闭table,导致table id急剧增长,因而导致主从数据复制失败。
解决办法有几个:
- 加大 table_cache_size,或者 table_open_cache 值,以及 table_definition_cache 选项。一般设置不低于总table数量的1.5倍,更严谨的话,要看 Open_tables 和 Opened_tables 这两个status值。Open_tables 表示当前正被打开的table数量,而 Opened_tables 表示历史上反复打开table的总次数。如果 Opened_tables 值特别高,表明 table cache 很可能不够用所致。
- 择机重启主库实例,让table id的值再次从0开始计数。
- 临时解决方案:把binlog format改成statement,并且把事务隔离级别改成RR,尽量避免数据不一致的风险。
- 发表于 2017-05-17 12:03
- 阅读 ( 51 )
