MySQL(InnoDB)与Kafka的文件存储实现对比
这篇文章主要围绕几个问题开展:
1.MySQL和Kafka的最小数据单元分别是什么?
2.围绕他们的最小数据单元,InnoDB和MySQL是怎样进行存储的?
3.一个数据的查询,在InnoDB和Kafka的内部是怎么定位到这条数据的?
前言
MySQL是非常流行的开源关系型数据库,目前国内大部分的电商网站都在使用。Kafka同样也是非常流行的分布式消息系统,同时也被作为实时数据生态圈的重要一环,也有着大量的互联网企业用户。这两个开源产品有一个共同特点:都关系到数据的存和取。对于数据,我们非常关心一致性存储、高效查询和它的使用方式。
今天,我们在这里对这两个开源产品在实现上做一些对比,借此机会加深对它们的认识。
最小单元
MySQL是一个关系型数据库,数据的最小的单元就是“行”;
Kafka是一个消息系统,它的最小单元是“message”是“条”。
InnoDB的文件存储机制
InnoDB的数据是一行行的,那么InnoDB是怎么把数据组织起来的呢?同样地,Kafka的消息是一条条的,Kafka又是怎么把消息组织起来的呢?
我们先来看看InnoDB的物理文件结构图:
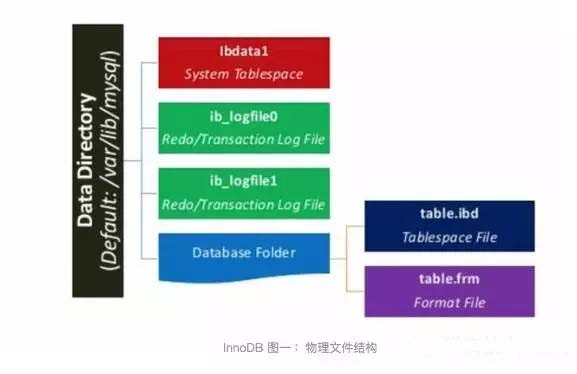
上图中,数据文件存储在数据目录data-dir,在data-dir下有这些文件或文件夹:
ibdata1:系统表空间
ib_logfile:事务日志文件
用户数据库目录/table.ibd:数据表空间文件
用户数据库目录/table.frm:数据表结构文件
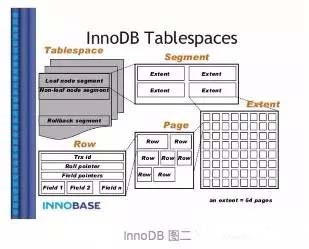
InnoDB的行和物理文件的关系可以用这样一个列表来表示:
row->page->extent->segment->tablespace->ibdata
我们用下图来表示它们之间的关系:
ibdata1文件
系统表空间文件,包含了以下部分doublewritebuffer、insert buffer、undo logs、rollback segment。
bid文件
其实是Tablespace包含了Page、Extent、Segment。
Tablespace
由file header、insert buffer bitmap、first inodepage number、index pages(segment)组成。
Segment
4个Extent组成一个segment。
当segment增长的时候,第一次扩展32个page,接着InnoDB会分配一整个segment(4个extent)。为了确保数据的顺序性,InnoDB是可以一次性增加一个segment的。在InnoDB里面,一个索引会分配2个segment。一个是B-tree的非叶子节点,一个是B-tree的叶子节点。非叶子节点只包含指向叶子节点的指针,叶子节点包含实际的数据行。保持叶子节点在磁盘的连续性可以获得顺序I/O的操作性能,叶子节点里面包含了数据。
Extent
以默认的16KB一个page为例,64个Page组成一个Extent,大小是1M。
Page
一个存放记录(row)的page,由page header、page trailer、page body,位移信息和page footer组成。
行(Row)
行的逻辑结构包括row header、undo pointer、null bitmap、Trx id(事务id)、Rollpointer,Field Pointers。
行的分类
假如一行的大小不超过8KB(半页),这一行就存储在一个页面。如果一行超过了8KB,可变长的列就会被挪到别的page来进行存储,直到一行小于等于8KB。
Compact format 和 DYNAMIC format
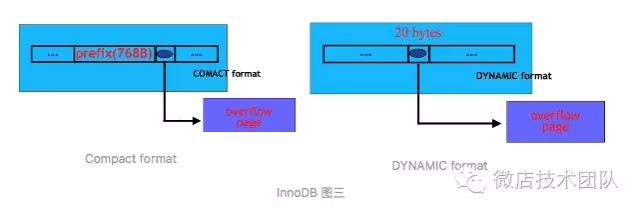
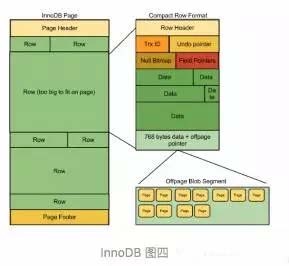
nnoDB的Page和行是如何组合在一起?
行是包含在Page里面的,如图:
Kafka的文件存储机制
要理解Kafka的文件存储机制,我们先来看看这个列表:
Message->log file->index file->segment->partition->topic->broker
1.broker接收producer的写入请求,把消息写入到一个topic里面,同时根据router信息进行分区操作。
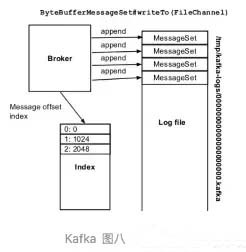
2.broker把确定了partition的消息写入到segment里面的某一个log文件,消息的物理偏移量同时记入index文件里面。
3.查询一条message的时候,consumer发送需要读取的消息的offset给broker,broker根据offset来进行二分查找,定位到具体的index文件,进而定位到log文件里面的消息。
我们从下面的图一可以看到Broker是接收Produer的写入请求,而图二展示了Broker的内部机制:
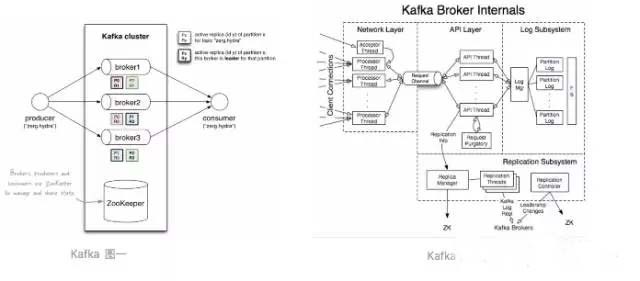
图三、四、五分别表示了Broker写入消息的时候进行分区、Broker在写入消息的时候同时操作index和log文件、Partition的物理构成:
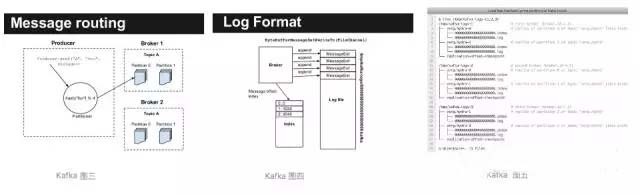
操作如何通过index和log文件来定位某一条message?
Index文件是索引文件,log文件是数据文件,Segment文件命名规则,Partition全局的第一个segment从0开始,后续每个segment文件名为上一个segment最后一条消息的offset值。
数值最大为64位long大小,19位数字字符长度,没有数字用0填充。

通过offset查找消息的步骤如下:
step1:查找segment文件的index
00000000000000000000.index表示最开始的文件,起始偏移量(offset)为0.第二个文件00000000000000368769.index的消息量起始偏移量为368770 =368769 +1。同样,第三个文件00000000000000737337.index的起始偏移量为737338=737337+ 1,其他后续文件依次类推,以起始偏移量命名并排序这些文件,只要根据offset 二分查找文件列表,就可以快速定位到具体文件。当offset=368776时定位到00000000000000368769.index|log
step2:根据index对应的物理位移定位message
通过第一步定位到segment文件,当offset=368776时,依次定位到00000000000000368769.index的元数据物理位置和00000000000000368769.log的物理偏移地址,然后再通过00000000000000368769.log顺序查找直到offset=368776为止。
segment index file采取稀疏索引存储方式,它减少索引文件大小,通过mmap可以直接内存操作,稀疏索引为数据文件的每个对应message设置一个元数据指针,它比稠密索引节省了更多的存储空间,但查找起来需要消耗更多的时间。
Message的物理结构

8 byte offset 在parition(分区)内的每条消息都有一个有序的id号,这个id号被称为偏移(offset),它可以唯一确定每条消息在parition(分区)内的位置。即offset表示partiion的第多少message
4 byte message size message大小
4 byte CRC32 用crc32校验message
1 byte “magic” 表示本次发布Kafka服务程序协议版本号
1 byte “attributes” 表示为独立版本、或标识压缩类型、或编码类型
4 byte key length 表示key的长度,当key为-1时,K byte key字段不填
K byte key 可选
value bytes payload 表示实际消息数据
Kakfa log操作
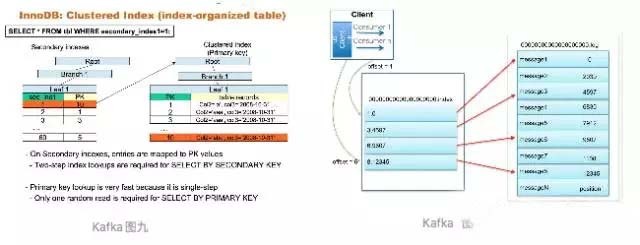
nnoDB/Kafka的一个查询如何工作的?
InnoDB的一个查询的主要流程:
1.用户输入一个SQL到MySQL Server(假设带索引查询),MySQL的语法解析器会对SQL进行分解,最后确定该SQL的主键索引/二级索引以及对应的值。SQL内容为SELECT * from tbl where secondary_index1=1
2.InnoDB会对这个二级索引的值进行B+Tree的查找,由于是二级索引,这时候会在二级索引的non-leaf进行查找
3.当定位到对应的叶子节点,根据叶子节点里面的主键信息,再对主键索引进行查找
Kafka的读取过程,相对于InnoDB的读取,显得简单很多,因为它是直接发送offset给Broker
1.client发送offset给broker
2.broker对offset进行二分查找,定位对应的index文件,进而定位对应的log
小结
1.InnoDB作为关系型数据库,从文件存储到文件构成和查找实现,都比Kafka要复杂很多。
2.Kakfa的定位是消息分发,定位简单,所以在逻辑上会比InnoDB要简单一点。
- 发表于 2017-02-24 19:03
- 阅读 ( 52 )
