PostgreSQL 锁机制全解析:从基础原理到深度实践
背景与概述
在生产环境中,数据库的并发控制是确保数据一致性和系统稳定性的核心机制。PostgreSQL作为一款功能强大的开源关系型数据库,其锁机制的设计直接决定了系统在高并发场景下的表现。
作为一名在一线工作多年的运维工程师,我见过太多因为锁问题导致的数据库故障:长事务导致的锁等待、应用超时、甚至是死锁造成的服务中断。这些问题的排查和解决需要对PostgreSQL的锁机制有深入的理解。
本文将系统性地解析PostgreSQL 17 的锁机制,涵盖锁的分类、MVCC与锁的关系、锁等待与死锁检测、常见故障排查以及监控优化实践。通过大量的实战案例和脚本,帮助读者建立完整的锁知识体系。
前置知识要求:
- 熟悉Linux基础命令操作
- 具备基本的数据库操作经验
- 理解事务ACID特性
实验环境说明:
- PostgreSQL 17.3(源码编译安装)
- 操作系统:CentOS Stream 9或Ubuntu 24.04 LTS
- 测试数据基于pgbench标准工具生成
1. 锁机制基础概念
1.1 为什么需要锁机制
数据库是多用户并发访问的系统,多个事务可能同时对同一份数据进行操作。如果没有有效的并发控制机制,就会出现以下问题:
脏读(Dirty Read):一个事务读取了另一个事务未提交的数据
不可重复读(Non-repeatable Read):同一事务中两次读取同一行数据结果不同
幻读(Phantom Read):同一事务中两次查询返回的记录数不同
更新丢失(Lost Update):两个事务同时读取并修改同一数据,后提交的覆盖了先提交的修改
PostgreSQL通过锁机制和MVCC(多版本并发控制)来避免这些问题。理解这两者的关系是掌握PostgreSQL并发控制的关键。
1.2 PostgreSQL锁机制分类
PostgreSQL的锁可以分为以下几大类:
按锁定对象分类:
- 表级锁(Table-level locks)
- 行级锁(Row-level locks)
- 页级锁(Page-level locks)
- 咨询锁(Advisory locks)
- 事务锁(Transaction locks)
按锁定模式分类:
- 排他锁(Exclusive)
- 共享锁(Share)
- 更新锁(Update)
- 等等
理解每种锁的粒度和适用场景,是进行锁问题排查的基础。
2. 表级锁详解
2.1 表级锁模式
PostgreSQL的表级锁有多种模式,通过pg_locks系统catalog可以查看。表级锁主要在DDL操作和某些DML操作中使用。
表级锁模式对照表:
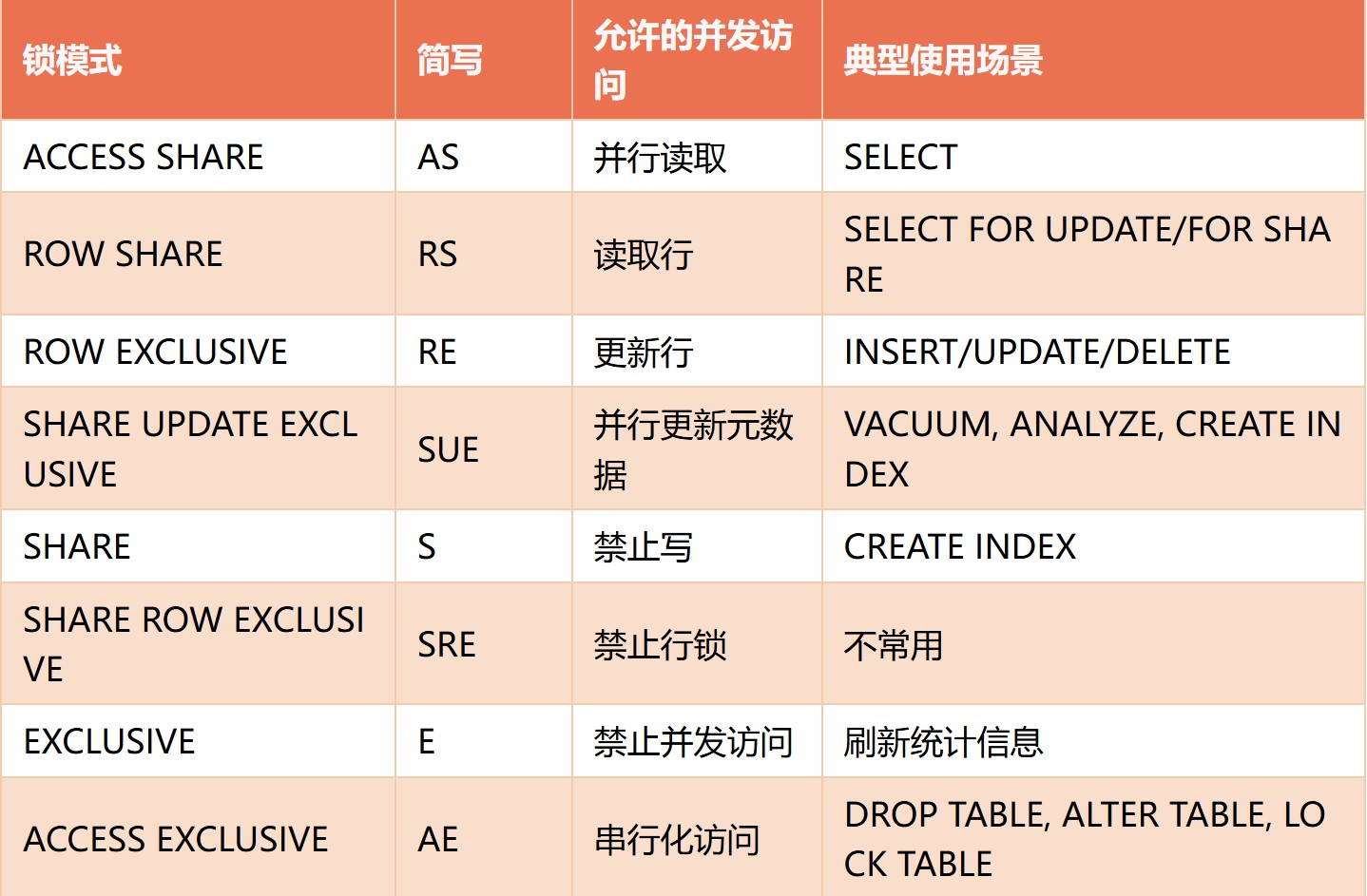
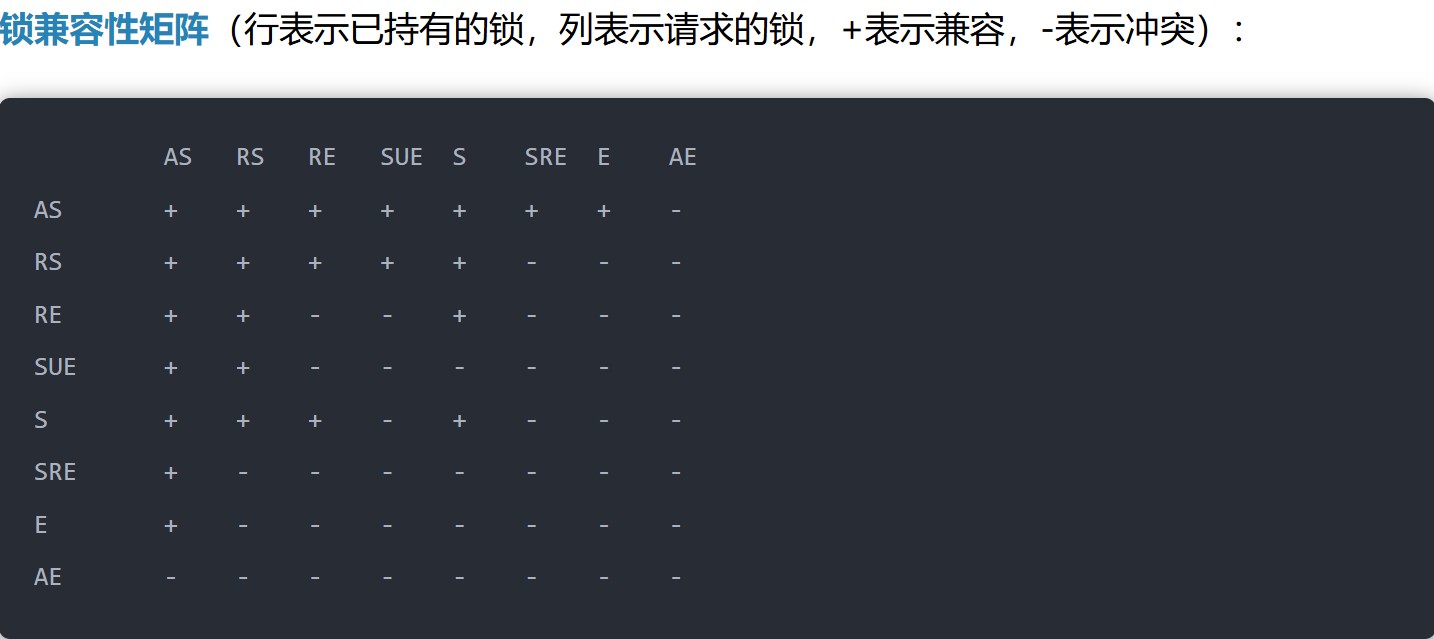
2.2 表级锁查看命令
查看当前数据库中所有表级锁的SQL查询:
-- 查看所有表级锁的详细信息
SELECT
l.locktype,
d.relname,
l.mode,
l.granted,
l.fastpath,
l.virtualtransaction,
l.pid,
l.virtualxid,
l.transactionid,
l.classid,
l.objid,
l.objsubid,
a.usename,
a.query,
a.query_start,
a.state
FROM
pg_locks l
LEFTJOIN pg_database d ON d.oid = l.database
LEFTJOIN pg_class c ON c.oid = l.relation
LEFTJOIN pg_authid a ON a.usesysid = l.pid
WHERE
l.relation ISNOTNULL
AND d.datname = current_database()
ORDERBY
l.pid,
l.mode;
执行这个查询时可能返回空结果,这是正常现象——没有锁等待时granted列全部为真。
2.3 表级锁的获取与释放
自动获取表级锁的场景:
-- ACCESS SHARE锁 - 普通SELECT
SELECT * FROMusersWHEREid = 1;
-- ROW EXCLUSIVE锁 - INSERT操作
INSERTINTOusers (name, email) VALUES ('test', 'test@example.com');
-- ROW EXCLUSIVE锁 - UPDATE操作
UPDATEusersSET email = 'new@example.com'WHEREid = 1;
-- ROW EXCLUSIVE锁 - DELETE操作
DELETEFROMusersWHEREid = 1;
手动获取表级锁的方法:
-- 显式获取ACCESS EXCLUSIVE锁
LOCKTABLEusersINACCESS EXCLUSIVE MODE;
-- 获取SHARE锁(禁止写操作)
LOCKTABLEusersINSHAREMODE;
-- 获取SHARE ROW EXCLUSIVE锁
LOCKTABLEusersINSHAREROW EXCLUSIVE MODE;
-- 无超时锁定(会一直等待)
LOCKTABLEusersINACCESS EXCLUSIVE MODE;
-- 带超时的锁定(5秒超时)
LOCKTABLEusersINACCESS EXCLUSIVE MODENOWAIT;
-- 或使用timeout参数(PostgreSQL 17支持)
SET lock_timeout = '5s';
LOCKTABLEusersINACCESS EXCLUSIVE MODE;
SET lock_timeout = '0';
2.4 表级锁与DDL操作
DDL操作会获取ACCESS EXCLUSIVE锁,这是最严格的表级锁,会阻塞所有其他访问。
典型DDL操作的锁级别:
-- DROP TABLE - ACCESS EXCLUSIVE
DROPTABLEIFEXISTSusers;
-- ALTER TABLE - ACCESS EXCLUSIVE
ALTERTABLEusersADDCOLUMN phone VARCHAR(20);
-- ALTER TABLE(部分操作使用Share Update Exclusive)
ALTERTABLEusersSET (
autovacuum_vacuum_threshold = 50
);
-- CREATE INDEX - SHARE
CREATEINDEX idx_users_email ONusers(email);
-- CREATE INDEX CONCURRENTLY - 无锁(事务外执行)
CREATEINDEX CONCURRENTLY idx_users_email ONusers(email);
重要警告:生产环境中执行DDL前务必检查是否有长事务持有锁,否则可能导致应用长时间阻塞。
3. 行级锁详解
3.1 行级锁模式
行级锁是PostgreSQL中最常用的锁类型,主要用于控制对表中具体行的并发访问。
行级锁模式:
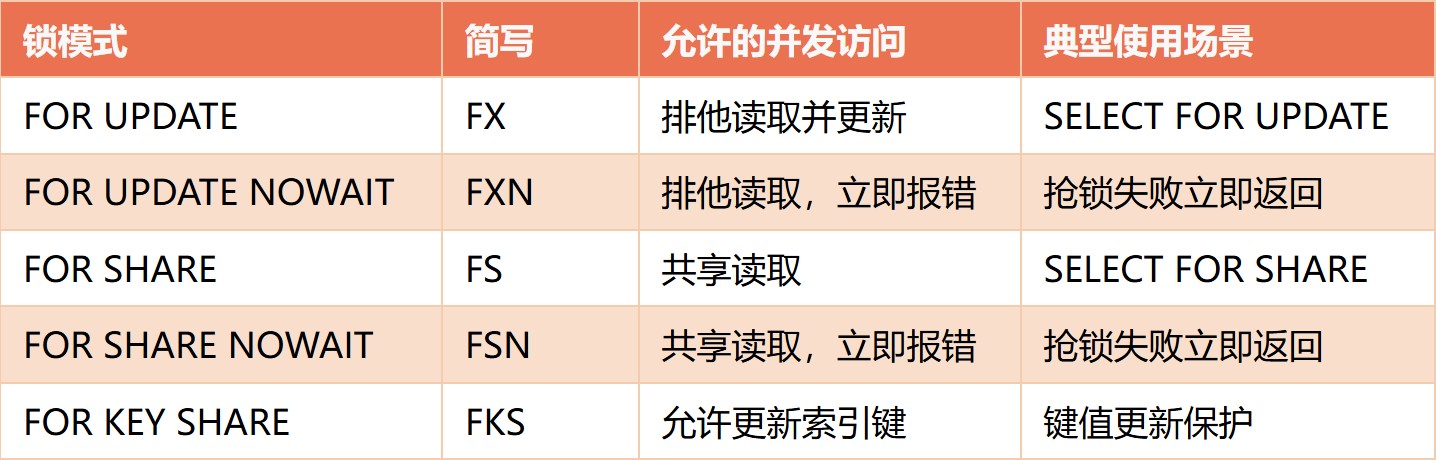
注意:FOR UPDATE和FOR SHARE是行级锁,但它们也会在表级别获取相应的锁(ROW SHARE或ROW EXCLUSIVE)。
3.2 行级锁查看命令
-- 查看当前行级锁(通过pg_locks)
SELECT
l.locktype,
c.relname AS table_name,
l.mode,
l.granted,
l.pid,
l.virtualtransaction,
l.transactionid,
l.classid,
l.objid,
l.objsubid,
a.usename,
a.query,
a.query_start,
a.state,
a.wait_event_type,
a.wait_event
FROM
pg_locks l
JOIN pg_class c ON c.oid = l.relation
LEFTJOIN pg_authid a ON a.usesysid = l.pid
WHERE
l.locktype = 'tuple'
OR (l.locktype IN ('transactionid', 'virtualxid') AND l.pid ISNOTNULL)
ORDERBY
a.query_start DESC;
更简洁的查看当前会话持有的行锁:
-- PostgreSQL 17新增:pg_locks_with_info视图
SELECT * FROM pg_locks_with_info
WHERE locktype = 'tuple'
ORDER BY pid, mode;
3.3 常见行级锁操作
SELECT FOR UPDATE:
-- 普通SELECT不会加行锁
SELECT * FROM accounts WHEREid = 1; -- 无锁
-- SELECT FOR UPDATE会加排他行锁
SELECT * FROM accounts WHEREid = 1FORUPDATE; -- 排他锁
-- NOWAIT变体:锁被占用时立即报错
SELECT * FROM accounts WHEREid = 1FORUPDATENOWAIT;
-- SKIP LOCKED变体:跳过被锁的行
SELECT * FROM accounts WHEREid = 1FORUPDATESKIPLOCKED;
SELECT FOR SHARE:
-- 共享行锁,多个事务可以同时持有
SELECT * FROM accounts WHERE id = 1 FOR SHARE;
-- NOWAIT变体
SELECT * FROM accounts WHERE id = 1 FOR SHARE NOWAIT;
在UPDATE/DELETE中隐式获取:
-- UPDATE自动对目标行加FOR UPDATE锁
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
-- DELETE自动对目标行加FOR UPDATE锁
DELETE FROM accounts WHERE id = 1;
3.4 行级锁与死锁
行级锁是最容易引起死锁的锁类型。死锁发生在两个或多个事务相互等待对方持有的锁时。
死锁示例:
-- 事务1
BEGIN;
SELECT * FROM accounts WHEREid = 1FORUPDATE; -- 锁定id=1
SELECT * FROM accounts WHEREid = 2FORUPDATE; -- 等待id=2
-- 事务2(并发执行)
BEGIN;
SELECT * FROM accounts WHEREid = 2FORUPDATE; -- 锁定id=2
SELECT * FROM accounts WHEREid = 1FORUPDATE; -- 等待id=1,死锁!
PostgreSQL会自动检测死锁并选择其中一个事务进行回滚。查看死锁日志:
# PostgreSQL配置文件postgresql.conf中启用日志
# log_lock_waits = on
# deadlock_timeout = 1s
# 查看死锁日志(如果发生)
grep -i "deadlock" /var/lib/postgresql/17/data/log/postgresql-*.log
4. MVCC机制与锁的关系
4.1 MVCC原理概述
MVCC(Multi-Version Concurrency Control,多版本并发控制)是PostgreSQL实现事务隔离的核心机制。它通过为每个事务提供数据库的一致性快照来实现并发访问。
MVCC的核心概念:
- TID(Tuple ID):行的物理位置标识
- xmin/xmax:创建行的事务ID和删除/更新行的事务ID
- 事务快照:包含当前活跃事务ID列表的快照
事务可见性判断规则:
规则1:如果行的xmin事务在快照的active事务列表中,该行对当前事务不可见
规则2:如果行的xmax事务在快照的active事务列表中,该行对当前事务不可见
规则3:如果行的xmin事务在快照的active事务列表之前提交,该行对当前事务可见
规则4:如果行的xmax事务为空或未提交,该行对当前事务可见
规则5:如果当前事务是行的xmax事务,该行对当前事务不可见(自己的更新不可见)
4.2 MVCC与锁的协同工作
MVCC和锁是PostgreSQL并发控制的两大支柱,它们协同工作以提供高性能的并发访问:
MVCC处理的场景:
- 读写操作不互相阻塞
- 快照隔离级别下的并发读取
- 避免脏读和不可重复读
锁处理的场景:
- 写操作之间的协调
- DDL操作的串行化
- 行级更新/删除的协调
关键理解:
- SELECT查询不加行锁(除非使用FOR UPDATE/SHARE)
- UPDATE/DELETE需要对目标行加锁来防止并发修改
- 锁和MVCC共同保证隔离性和一致性
4.3 VACUUM与MVCC
由于MVCC会产生多版本数据,旧的行版本需要被清理以回收空间,这由VACUUM进程负责。
关键参数:
# postgresql.conf中的VACUUM相关配置
# autovacuum = on # 启用自动vacuum
# autovacuum_max_workers = 4 # 最大工作进程数
# autovacuum_naptime = 1min # 检查间隔
# 手动执行VACUUM
VACUUM VERBOSE ANALYZE users;
# 查看表膨胀情况
SELECT
schemaname,
relname,
n_dead_tup,
n_live_tup,
n_dead_tup / NULLIF(n_live_tup + n_dead_tup, 0) AS dead_ratio,
last_vacuum,
last_autovacuum
FROM
pg_stat_user_tables
WHERE
n_dead_tup > 1000
ORDER BY
n_dead_tup DESC;
5. 锁等待与性能问题
5.1 锁等待的概念
当一个事务请求的锁被另一个未提交的事务持有时,就会发生锁等待。长时间或大量的锁等待会严重影响系统性能。
查看锁等待的SQL:
-- 查看当前等待锁的会话
SELECT
a.datname,
c.relname AS table_name,
l.locktype,
l.mode,
l.granted,
l.pid,
l.virtualtransaction,
l.transactionid,
a.usename,
a.query,
a.query_start,
a.state,
a.wait_event_type,
a.wait_event,
a.client_addr
FROM
pg_locks l
JOIN pg_class c ON c.oid = l.relation
JOIN pg_stat_activity a ON a.pid = l.pid
WHERE
l.granted = false
ORDERBY
a.query_start;
5.2 锁等待监控脚本
以下是一个生产环境可用的锁等待监控脚本:
#!/bin/bash
# 文件名:check_lock_waits.sh
# 功能:监控PostgreSQL锁等待情况
# 使用:./check_lock_waits.sh [警告阈值秒数]
WARNING_THRESHOLD=${1:-30}# 默认30秒
PSQL="psql -U postgres -d postgres -t -A -F'|'"
echo"=========================================="
echo"PostgreSQL锁等待检查 - $(date '+%Y-%m-%d %H:%M:%S')"
echo"=========================================="
# 检查未授权的锁等待
echo""
echo"【1】当前等待锁的会话:"
echo"----------------------------------------"
WAITING=$($PSQL -c "
SELECT
l.pid AS blocked_pid,
a.usename AS blocked_user,
a.query AS blocked_query,
left(a.query_start::text, 19) AS query_start,
extract(EPOCH FROM (now() - a.query_start))::integer AS wait_seconds,
l.mode AS blocked_mode,
c.relname AS blocked_table,
l.locktype
FROM
pg_locks l
JOIN pg_stat_activity a ON a.pid = l.pid
LEFT JOIN pg_class c ON c.oid = l.relation
WHERE
l.granted = false
ORDER BY
extract(EPOCH FROM (now() - a.query_start)) DESC;
")
if [ -z "$WAITING" ]; then
echo"没有发现锁等待。"
else
echo"$WAITING"
fi
# 检查超过阈值的等待
echo""
echo"【2】等待超过${WARNING_THRESHOLD}秒的会话:"
echo"----------------------------------------"
CRITICAL=$($PSQL -c "
SELECT
l.pid AS blocked_pid,
a.usename AS blocked_user,
extract(EPOCH FROM (now() - a.query_start))::integer AS wait_seconds,
a.state,
left(a.query, 80) AS query_preview
FROM
pg_locks l
JOIN pg_stat_activity a ON a.pid = l.pid
WHERE
l.granted = false
AND extract(EPOCH FROM (now() - a.query_start)) > $WARNING_THRESHOLD
ORDER BY
extract(EPOCH FROM (now() - a.query_start)) DESC;
")
if [ -z "$CRITICAL" ]; then
echo"没有超过阈值的等待。"
else
echo"$CRITICAL"
fi
# 检查持有锁的阻塞者
echo""
echo"【3】持有锁并阻塞其他会话的进程:"
echo"----------------------------------------"
BLOCKERS=$($PSQL -c "
SELECT
l.pid AS blocker_pid,
a.usename AS blocker_user,
a.state,
left(a.query, 80) AS query_preview,
count(*) AS blocked_count
FROM
pg_locks l
JOIN pg_stat_activity a ON a.pid = l.pid
WHERE
l.granted = true
AND EXISTS (
SELECT 1 FROM pg_locks l2
WHERE l2.relation = l.relation
AND l2.granted = false
AND l2.pid != l.pid
)
GROUP BY
l.pid, a.usename, a.state, a.query
ORDER BY
blocked_count DESC;
")
if [ -z "$BLOCKERS" ]; then
echo"没有发现阻塞者。"
else
echo"$BLOCKERS"
fi
# 检查死锁
echo""
echo"【4】最近死锁统计:"
echo"----------------------------------------"
DEADLOCKS=$($PSQL -c "
SELECT
datname,
queries,
callers,
storage,
locks
FROM
pg_stat_database
WHERE
datname = current_database();
")
echo"$DEADLOCKS" | head -20
echo""
echo"检查完成 - $(date '+%Y-%m-%d %H:%M:%S')"
5.3 锁等待超时配置
合理设置锁等待超时可以避免长时间锁等待导致的故障扩散:
# postgresql.conf配置
# 锁等待超时(建议值:1-5秒)
lock_timeout = '2s'
# 事务超时(建议值:30秒-5分钟)
statement_timeout = '60000'# 60秒
# 空闲事务超时(建议值:10分钟)
idle_in_transaction_session_timeout = '10min'
# 锁等待日志
log_lock_waits = on
deadlock_timeout = '1s'
# 设置示例
ALTER SYSTEM SET lock_timeout = '2s';
ALTER SYSTEM SET statement_timeout = '60s';
ALTER SYSTEM SET idle_in_transaction_session_timeout = '10min';
# 验证设置
SHOW lock_timeout;
SHOW statement_timeout;
SHOW idle_in_transaction_session_timeout;
6. 死锁检测与处理
6.1 死锁原理
PostgreSQL的死锁检测器会定期检查等待锁的事务图。当检测到循环等待时选择一个事务进行回滚以打破死锁。
死锁检测算法:
- 构建等待图:节点是事务,边是等待关系
- 检测图中是否存在环
- 存在环时选择victim事务进行回滚
victim选择策略:
- 优先回滚持有最少锁的事务
- 优先回滚最晚启动的事务
- 优先回滚完成工作量最少的事务
6.2 死锁配置参数
# postgresql.conf
# 死锁检测间隔(默认值1秒,生产环境可降低)
# deadlock_timeout = '1s'
# 查看当前值
SHOW deadlock_timeout;
# 启用死锁日志详细输出
log_lock_waits = on
log_parameter_max_length = 1KB
log_parameter_max_length_in_display = 1KB
6.3 死锁处理流程脚本
#!/bin/bash
# 文件名:handle_deadlock.sh
# 功能:检测并处理PostgreSQL死锁
# 使用:./handle_deadlock.sh
PSQL="psql -U postgres -d postgres -t -A -F'|'"
echo"=========================================="
echo"PostgreSQL死锁检测与处理 - $(date '+%Y-%m-%d %H:%M:%S')"
echo"=========================================="
# 检查最近的死锁
echo""
echo"【1】数据库死锁统计:"
echo"----------------------------------------"
STATS=$($PSQL -c "
SELECT
datname,
numbackends,
xact_commit,
xact_rollback,
deadlocks,
pg_size_pretty(pg_database_size(datname)) AS size
FROM
pg_stat_database
WHERE
datname = current_database();
")
echo"$STATS"
# 如果有死锁发生,记录警告
DEADLOCK_COUNT=$($PSQL -c "SELECT deadlocks FROM pg_stat_database WHERE datname = current_database();")
if [ "$DEADLOCK_COUNT" -gt 0 ]; then
echo""
echo"【警告】检测到 $DEADLOCK_COUNT 个死锁事件!"
echo"请检查PostgreSQL日志获取详细信息。"
fi
# 查找可能的死锁参与者
echo""
echo"【2】潜在死锁参与者(长事务+多锁):"
echo"----------------------------------------"
POTENTIAL=$($PSQL -c "
SELECT
pid,
usename,
state,
left(query, 100) AS query,
extract(EPOCH FROM (now() - query_start))::integer AS duration_sec,
wait_event_type,
wait_event
FROM
pg_stat_activity
WHERE
state != 'idle'
AND extract(EPOCH FROM (now() - query_start)) > 60
ORDER BY
duration_sec DESC
LIMIT 10;
")
if [ -z "$POTENTIAL" ]; then
echo"没有发现长事务。"
else
echo"$POTENTIAL"
fi
# 检查特定表的锁竞争
echo""
echo"【3】高竞争表统计:"
echo"----------------------------------------"
TABLES=$($PSQL -c "
SELECT
c.relname AS table_name,
l.mode,
count(*) AS lock_count
FROM
pg_locks l
JOIN pg_class c ON c.oid = l.relation
WHERE
l.granted = true
AND c.relkind = 'r'
GROUP BY
c.relname, l.mode
HAVING
count(*) > 1
ORDER BY
lock_count DESC;
")
if [ -z "$TABLES" ]; then
echo"没有发现高竞争表。"
else
echo"$TABLES"
fi
echo""
echo"检查完成。"
7. 咨询锁
7.1 咨询锁概念
咨询锁(Advisory Locks)是PostgreSQL提供的应用层锁机制,它不与数据库对象关联,需要应用显式获取和释放。适用于业务层面的并发控制。
咨询锁特点:
- 不与数据实体关联
- 需要显式获取(LOCK)和释放(通过会话结束或UNLOCK)
- 可以跨会话使用
- 对性能有一定影响
7.2 咨询锁函数
-- 获取会话级咨询锁(阻塞等待)
SELECT pg_advisory_lock(keybigint);
SELECT pg_advisory_lock(key1 int, key2 int);
-- 尝试获取咨询锁(非阻塞,获取失败立即返回)
SELECT pg_try_advisory_lock(keybigint);
SELECT pg_try_advisory_lock(key1 int, key2 int);
-- 释放咨询锁
SELECT pg_advisory_unlock(keybigint);
SELECT pg_advisory_unlock(key1 int, key2 int);
-- 释放当前会话持有的所有咨询锁
SELECT pg_advisory_unlock_all();
-- 查看会话级咨询锁
SELECT * FROM pg_locks WHERE locktype = 'advisory';
-- 进程级咨询锁(PostgreSQL 17新增)
SELECT pg_advisory_lock_shared(keybigint);
SELECT pg_try_advisory_lock_shared(keybigint);
7.3 咨询锁使用示例
排队控制示例:
-- 创建处理任务的函数(使用咨询锁实现互斥)
CREATEORREPLACEFUNCTION process_task(task_id BIGINT)
RETURNSBOOLEANAS $$
DECLARE
lock_acquired BOOLEAN;
BEGIN
-- 尝试获取任务锁
lock_acquired := pg_try_advisory_lock(task_id);
IF NOT lock_acquired THEN
RAISE NOTICE '任务 % 正在被其他进程处理', task_id;
RETURN FALSE;
ENDIF;
-- 执行任务处理
-- ... 业务逻辑 ...
-- 释放锁
PERFORM pg_advisory_unlock(task_id);
RETURN TRUE;
END;
$$ LANGUAGE plpgsql;
-- 使用示例
DO $$
DECLARE
resultBOOLEAN;
BEGIN
result := process_task(12345);
IF result THEN
RAISE NOTICE '任务处理成功';
ELSE
RAISE NOTICE '任务处理失败(已被占用)';
ENDIF;
END;
$$;
限制并发数量示例:
-- 创建信号量函数
CREATEORREPLACEFUNCTION acquire_semaphore(
semaphore_name TEXT,
max_concurrent INT
) RETURNSBOOLEANAS $$
DECLARE
sem_key BIGINT;
current_count INT;
BEGIN
-- 生成唯一的sem_key
sem_key := hashtext(semaphore_name)::BIGINT;
-- 获取当前计数
SELECT
COUNT(*)
INTO
current_count
FROM
pg_locks
WHERE
locktype = 'advisory'
AND objid = sem_key
AND granted = true;
-- 如果已达上限,等待
IF current_count >= max_concurrent THEN
PERFORM pg_advisory_lock(sem_key);
PERFORM pg_advisory_unlock(sem_key);
RETURN FALSE;
ENDIF;
-- 获取信号量
PERFORM pg_advisory_lock(sem_key);
RETURN TRUE;
END;
$$ LANGUAGE plpgsql;
-- 释放信号量
CREATEORREPLACEFUNCTION release_semaphore(semaphore_name TEXT)
RETURNSVOIDAS $$
DECLARE
sem_key BIGINT;
BEGIN
sem_key := hashtext(semaphore_name)::BIGINT;
PERFORM pg_advisory_unlock(sem_key);
END;
$$ LANGUAGE plpgsql;
7.4 咨询锁监控
-- 查看所有咨询锁
SELECT
l.locktype,
l.pid,
l.relation,
l.mode,
l.granted,
l.virtualtransaction,
a.usename,
a.query,
a.query_start,
a.state
FROM
pg_locks l
JOIN pg_stat_activity a ON a.pid = l.pid
WHERE
l.locktype = 'advisory'
ORDERBY
l.pid;
-- 查看咨询锁持有者
SELECT
a.pid,
a.usename,
a.state,
left(a.query, 100) ASquery,
extract(EPOCH FROM (now() - a.query_start)) ASduration
FROM
pg_stat_activity a
WHERE
EXISTS (
SELECT1FROM pg_locks l
WHERE l.pid = a.pid
AND l.locktype = 'advisory'
AND l.granted = true
)
ORDERBY
durationDESC;
8. 锁监控与诊断
8.1 锁监控视图和函数
PostgreSQL提供了多个系统视图和函数用于锁监控:
-- pg_locks - 锁信息综合视图
SELECT * FROM pg_locks LIMIT0; -- 查看结构
-- pg_locks_with_info - PostgreSQL 17新增,包含更详细的会话信息
SELECT * FROM pg_locks_with_info;
-- pg_blocking_pids - PostgreSQL 13+,查看阻塞给定进程的PID列表
SELECT pg_blocking_pids(pid) AS blocking_pids
FROM pg_stat_activity
WHERE state != 'idle';
-- pg_current_backend_pid - 获取当前后端PID
SELECT pg_current_backend_pid();
-- 查看特定会话持有的所有锁
SELECT * FROM pg_locks WHERE pid = 12345;
8.2 锁监控综合脚本
#!/bin/bash
# 文件名:pg_lock_monitor.sh
# 功能:PostgreSQL锁监控系统
# 建议:配合cron每分钟执行
REPORT_FILE="/var/log/postgresql/lock_report_$(date '+%Y%m%d_%H%M').log"
ALERT_SCRIPT="/opt/scripts/pg_lock_alert.sh"
PSQL="psql -U postgres -d postgres -t -A -F'|'"
echo"==========================================" > "$REPORT_FILE"
echo"PostgreSQL锁监控报告" >> "$REPORT_FILE"
echo"生成时间:$(date '+%Y-%m-%d %H:%M:%S')" >> "$REPORT_FILE"
echo"==========================================" >> "$REPORT_FILE"
# 1. 锁等待总体情况
echo"" >> "$REPORT_FILE"
echo"【1】锁等待总体统计" >> "$REPORT_FILE"
echo"----------------------------------------" >> "$REPORT_FILE"
$PSQL -c "
SELECT
COUNT(*) AS total_waiting,
COUNT(DISTINCT pid) AS waiting_sessions,
COUNT(DISTINCT relation) AS tables_involved
FROM
pg_locks
WHERE
granted = false;
" >> "$REPORT_FILE"
# 2. 等待超过10秒的会话
echo"" >> "$REPORT_FILE"
echo"【2】等待超过10秒的会话" >> "$REPORT_FILE"
echo"----------------------------------------" >> "$REPORT_FILE"
$PSQL -c "
SELECT
a.pid,
a.usename,
a.datname,
left(a.query, 80) AS query_preview,
extract(EPOCH FROM (now() - a.query_start))::integer AS wait_seconds,
a.state,
c.relname AS locked_table,
l.mode AS lock_mode
FROM
pg_locks l
JOIN pg_stat_activity a ON a.pid = l.pid
LEFT JOIN pg_class c ON c.oid = l.relation
WHERE
l.granted = false
AND extract(EPOCH FROM (now() - a.query_start)) > 10
ORDER BY
wait_seconds DESC
LIMIT 20;
" >> "$REPORT_FILE"
# 3. 持有锁最多的会话(潜在阻塞源)
echo"" >> "$REPORT_FILE"
echo"【3】持有锁最多的会话(潜在阻塞源)" >> "$REPORT_FILE"
echo"----------------------------------------" >> "$REPORT_FILE"
$PSQL -c "
SELECT
a.pid,
a.usename,
a.state,
left(a.query, 80) AS query_preview,
COUNT(*) AS locks_held,
SUM(CASE WHEN l.granted THEN 1 ELSE 0 END) AS granted_locks,
SUM(CASE WHEN NOT l.granted THEN 1 ELSE 0 END) AS waiting_locks
FROM
pg_locks l
JOIN pg_stat_activity a ON a.pid = l.pid
GROUP BY
a.pid, a.usename, a.state, a.query
HAVING
COUNT(*) > 5
ORDER BY
locks_held DESC
LIMIT 10;
" >> "$REPORT_FILE"
# 4. 按表统计锁竞争
echo"" >> "$REPORT_FILE"
echo"【4】按表统计锁竞争情况" >> "$REPORT_FILE"
echo"----------------------------------------" >> "$REPORT_FILE"
$PSQL -c "
SELECT
c.relname AS table_name,
l.mode,
COUNT(*) AS lock_count,
COUNT(DISTINCT l.pid) AS session_count
FROM
pg_locks l
JOIN pg_class c ON c.oid = l.relation
WHERE
l.granted = true
AND c.relkind = 'r'
GROUP BY
c.relname, l.mode
ORDER BY
lock_count DESC
LIMIT 20;
" >> "$REPORT_FILE"
# 5. 死锁统计
echo"" >> "$REPORT_FILE"
echo"【5】数据库死锁统计" >> "$REPORT_FILE"
echo"----------------------------------------" >> "$REPORT_FILE"
$PSQL -c "
SELECT
datname,
numbackends,
xact_commit,
xact_rollback,
deadlocks,
conflicts
FROM
pg_stat_database
WHERE
datname = current_database();
" >> "$REPORT_FILE"
# 6. IDLE in transaction会话
echo"" >> "$REPORT_FILE"
echo"【6】IDLE in transaction会话(可能导致锁问题)" >> "$REPORT_FILE"
echo"----------------------------------------" >> "$REPORT_FILE"
$PSQL -c "
SELECT
pid,
usename,
state,
extract(EPOCH FROM (now() - state_change))::integer AS idle_seconds,
left(query, 100) AS query
FROM
pg_stat_activity
WHERE
state = 'idle in transaction'
AND extract(EPOCH FROM (now() - state_change)) > 60
ORDER BY
idle_seconds DESC;
" >> "$REPORT_FILE"
cat "$REPORT_FILE"
# 检查是否需要告警(等待超过60秒)
CRITICAL_COUNT=$($PSQL -c "
SELECT
COUNT(*)
FROM
pg_locks l
JOIN pg_stat_activity a ON a.pid = l.pid
WHERE
l.granted = false
AND extract(EPOCH FROM (now() - a.query_start)) > 60;
")
if [ "$CRITICAL_COUNT" -gt 0 ]; then
echo""
echo"【警告】发现 $CRITICAL_COUNT 个会话等待超过60秒!"
# 这里可以调用告警脚本
# bash "$ALERT_SCRIPT" "Critical lock wait detected"
fi
8.3 锁性能诊断脚本
#!/bin/bash
# 文件名:pg_lock_diagnosis.sh
# 功能:深入诊断锁性能问题
PSQL="psql -U postgres -d postgres -t -A -F'|'"
echo"=========================================="
echo"PostgreSQL锁性能诊断"
echo"=========================================="
# 1. 查找长时间运行的事务
echo""
echo"【1】长时间运行的事务(可能持有锁)"
echo"----------------------------------------"
$PSQL -c "
SELECT
pid,
usename,
state,
extract(EPOCH FROM (now() - xact_start))::integer AS xact_age_sec,
extract(EPOCH FROM (now() - query_start))::integer AS query_age_sec,
left(query, 100) AS query
FROM
pg_stat_activity
WHERE
state NOT IN ('idle', 'idle in transaction', 'idle in transaction (aborted)')
AND xact_start IS NOT NULL
ORDER BY
xact_age_sec DESC
LIMIT 10;
"
# 2. 分析锁等待模式
echo""
echo"【2】锁等待模式分析"
echo"----------------------------------------"
$PSQL -c "
WITH waiting_locks AS (
SELECT
l.relation,
l.mode,
l.pid,
l.transactionid
FROM
pg_locks l
WHERE
l.granted = false
),
holding_locks AS (
SELECT
l.relation,
l.mode,
l.pid,
l.transactionid
FROM
pg_locks l
WHERE
l.granted = true
)
SELECT
w.pid AS waiting_pid,
h.pid AS holding_pid,
c.relname AS table_name,
w.mode AS waiting_mode,
h.mode AS holding_mode,
w.transactionid AS waiting_xid,
h.transactionid AS holding_xid
FROM
waiting_locks w
JOIN holding_locks h ON (
COALESCE(w.relation, 0) = COALESCE(h.relation, 0)
AND COALESCE(w.transactionid, 0) = COALESCE(h.transactionid, 0)
)
LEFT JOIN pg_class c ON c.oid = w.relation
WHERE
w.pid != h.pid
ORDER BY
c.relname, w.mode;
"
# 3. 计算锁等待导致的性能损失
echo""
echo"【3】锁等待导致的性能损失估算"
echo"----------------------------------------"
$PSQL -c "
SELECT
COUNT(*) AS total_lock_waits,
COUNT(DISTINCT pid) AS affected_sessions,
round(COUNT(*) * 1.0 / NULLIF(EXTRACT(EPOCH FROM (now() - MIN(a.query_start))), 0), 2) AS avg_waits_per_sec
FROM
pg_locks l
JOIN pg_stat_activity a ON a.pid = l.pid
WHERE
l.granted = false;
"
# 4. 推荐优化建议
echo""
echo"【4】基于诊断的优化建议"
echo"----------------------------------------"
echo"检查以下配置参数:"
echo" - lock_timeout (当前: $(SHOW lock_timeout;))"
echo" - statement_timeout (当前: $(SHOW statement_timeout;))"
echo" - idle_in_transaction_session_timeout (当前: $(SHOW idle_in_transaction_session_timeout;))"
echo""
echo"考虑优化的场景:"
echo" 1. 减少事务持有时间"
echo" 2. 使用乐观锁替代悲观锁"
echo" 3. 优化查询减少锁竞争"
echo" 4. 调整锁粒度(行锁vs表锁)"
9. 常见锁故障排查
9.1 故障排查流程图
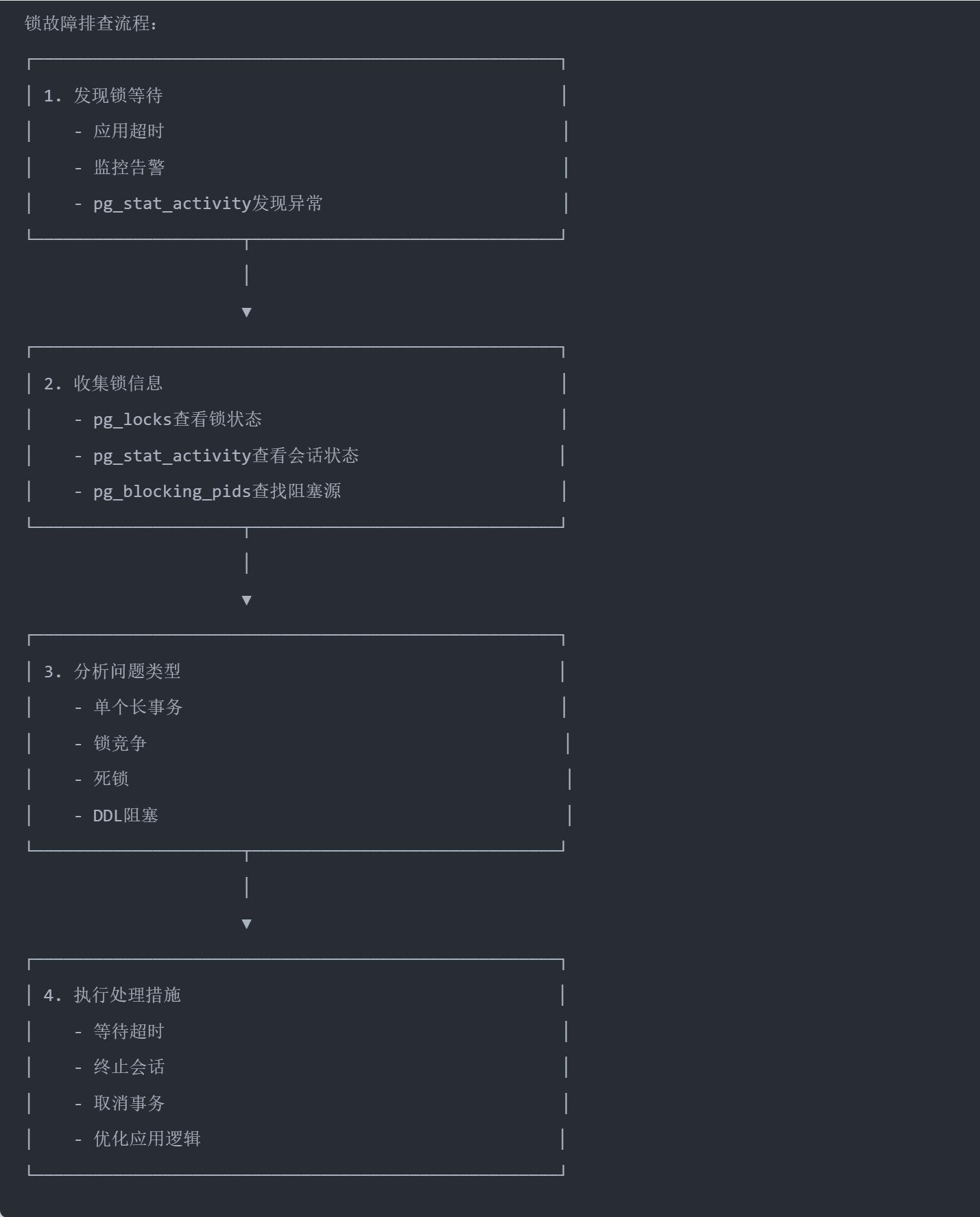
9.2 场景一:长事务导致锁等待
问题现象:应用访问特定记录时长时间等待,最终超时
排查步骤:
-- 1. 查看锁等待情况
SELECT
l.pid,
a.usename,
a.query,
a.query_start,
c.relname AS table_name,
l.mode
FROM
pg_locks l
JOIN pg_stat_activity a ON a.pid = l.pid
LEFTJOIN pg_class c ON c.oid = l.relation
WHERE
l.granted = false
AND a.query LIKE'%users%'; -- 替换为实际表名
-- 2. 查看持有锁的会话
SELECT
l.pid,
a.usename,
a.query,
a.query_start,
a.state,
c.relname AS table_name,
l.mode
FROM
pg_locks l
JOIN pg_stat_activity a ON a.pid = l.pid
LEFTJOIN pg_class c ON c.oid = l.relation
WHERE
l.granted = true
AND c.relname = 'users'; -- 替换为实际表名
-- 3. 查看该会话的事务详情
SELECT
pid,
usename,
query,
xact_start,
query_start,
state,
state_change,
wait_event_type,
wait_event
FROM
pg_stat_activity
WHERE
pid = <holding_pid>; -- 替换为实际PID
解决方案:
-- 方案1:等待长事务完成
-- 如果长事务正在正常工作,只需等待
-- 方案2:取消长时间空闲的事务
SELECT pg_cancel_backend(<pid>); -- 优雅取消
-- 方案3:强制终止(最后手段)
SELECT pg_terminate_backend(<pid>); -- 强制终止
-- 方案4:查看是否可以优化长事务
-- 分析慢查询
SELECT
query,
calls,
mean_time,
total_time
FROM
pg_stat_statements
ORDERBY
total_time DESC
LIMIT10;
9.3 场景二:DDL操作阻塞
问题现象:执行ALTER TABLE等DDL操作时长时间阻塞
排查步骤:
-- 1. 查看ACCESS EXCLUSIVE锁等待
SELECT
l.pid,
a.usename,
a.query,
a.state,
c.relname AS table_name,
l.mode,
l.granted
FROM
pg_locks l
JOIN pg_stat_activity a ON a.pid = l.pid
LEFTJOIN pg_class c ON c.oid = l.relation
WHERE
l.mode = 'AccessExclusiveLock'
OR l.locktype = 'relation'
ANDNOT l.granted;
-- 2. 查看是否有长事务
SELECT
pid,
usename,
query,
xact_start,
state
FROM
pg_stat_activity
WHERE
state NOTIN ('idle', 'idle in transaction')
AND xact_start ISNOTNULL
ORDERBY
xact_start;
解决方案:
-- 方案1:使用CONCURRENTLY选项(针对CREATE INDEX)
CREATEINDEX CONCURRENTLY idx_users_email ONusers(email);
-- 方案2:设置短锁等待超时
SET lock_timeout = '5s';
ALTERTABLEusersADDCOLUMN phone VARCHAR(20);
RESET lock_timeout;
-- 方案3:找出阻塞者并处理
SELECT pg_terminate_backend(<blocking_pid>);
-- 方案4:使用pg_repack进行在线表重构
-- 安装pg_repack后执行
-- pg_repack -d mydb -t users --add-column phone
9.4 场景三:死锁频发
问题现象:应用日志中出现大量死锁错误
排查步骤:
-- 1. 启用详细死锁日志
ALTER SYSTEM SET log_lock_waits = on;
ALTER SYSTEM SET log_statement = 'all';
SELECT pg_reload_conf();
-- 2. 查看pg_stat_database中的deadlocks计数
SELECT * FROM pg_stat_database WHERE datname = current_database();
-- 3. 分析最近的死锁日志
-- 在postgresql.conf中配置log_directory后查看
解决方案:
-- 方案1:调整事务顺序(应用层)
-- 确保不同事务以相同顺序访问资源
-- 方案2:使用SELECT FOR UPDATE NOWAIT
-- 快速失败而不是长时间等待
-- 方案3:减少事务持锁时间
-- 将大事务拆分为小事务
-- 避免在事务中执行不必要的SELECT
-- 方案4:使用乐观锁
-- 通过版本号而非锁来控制并发
-- 方案5:分析访问模式优化索引
-- 确保查询走索引,避免全表扫描导致的锁
9.5 场景四:行级锁竞争严重
问题现象:高并发更新同一张表的某些热点行,性能急剧下降
排查步骤:
-- 1. 统计各表的行级锁使用情况
SELECT
c.relname AS table_name,
l.mode,
COUNT(*) AS lock_count
FROM
pg_locks l
JOIN pg_class c ON c.oid = l.relation
WHERE
l.locktype = 'tuple'
AND c.relkind = 'r'
GROUPBY
c.relname, l.mode
ORDERBY
lock_count DESC;
-- 2. 查看热块(hot tuple)问题
SELECT
relname,
n_tup_upd,
n_tup_del,
n_tup_hot_upd,
n_live tup,
n_dead_tup,
ROUND(n_tup_hot_upd::numeric / NULLIF(n_tup_upd, 0) * 100, 2) AS hot_ratio
FROM
pg_stat_user_tables
ORDERBY
n_tup_upd DESC;
-- 3. 查看vacuum配置
SELECT
relname,
last_vacuum,
last_autovacuum,
vacuum_count,
autovacuum_count
FROM
pg_stat_user_tables
WHERE
relname IN ('table1', 'table2'); -- 替换为实际表名
解决方案:
-- 方案1:优化HOT更新(Heap-Only Tuple)
-- 确保UPDATE不影响索引键
-- 保持列宽度不变
-- 方案2:调整autovacuum参数
ALTERTABLE hot_table SET (
autovacuum_vacuum_threshold = 50,
autovacuum_vacuum_scale_factor = 0.01,
autovacuum_analyze_threshold = 50,
autovacuum_analyze_scale_factor = 0.01
);
-- 方案3:手动执行VACUUM
VACUUM VERBOSE ANALYZE hot_table;
-- 方案4:考虑分区
-- 将热点数据分散到不同分区
-- 方案5:使用pg_stat_statements分析更新模式
SELECT
query,
calls,
total_time,
mean_time,
rows
FROM
pg_stat_statements
WHERE
queryLIKE'%UPDATE%table_name%'-- 替换表名
ORDERBY
total_time DESC
LIMIT10;
10. 锁优化最佳实践
10.1 应用设计最佳实践
事务设计原则:
-- 原则1:保持事务简短
-- 好的做法:只包含必要的操作
BEGIN;
UPDATE accounts SET balance = balance - 100WHEREid = 1;
UPDATE accounts SET balance = balance + 100WHEREid = 2;
COMMIT;
-- 不好的做法:在事务中执行网络IO、复杂计算等
BEGIN;
SELECT * FROM remote_api(); -- 外部API调用
-- ... 更多操作
COMMIT;
-- 原则2:避免在循环中持有锁
-- 好的做法:批量处理
DO $$
DECLARE
ids INTEGER[];
BEGIN
ids := ARRAY[1, 2, 3, 4, 5];
FOR i IN 1..array_length(ids, 1) LOOP
-- 每个UPDATE都是独立的小事务
UPDATE accounts SET last_access = now() WHEREid = ids[i];
ENDLOOP;
END;
$$;
-- 原则3:使用适当的隔离级别
-- PostgreSQL默认READ COMMITTED,大多数场景足够
SETTRANSACTIONISOLATIONLEVELREAD COMMITTED;
-- 或使用READ COMMITTED(默认)
-- 只有在必要时才使用SERIALIZABLE
SETTRANSACTIONISOLATIONLEVELSERIALIZABLE;
锁使用原则:
-- 原则1:使用NOWAIT避免长时间等待
-- 好的做法:快速失败
BEGIN;
SELECT * FROM accounts WHEREid = 1FORUPDATENOWAIT;
-- 处理业务逻辑
COMMIT;
EXCEPTION
WHEN lock_not_available THEN
RAISE NOTICE '无法获取锁,请重试';
END;
-- 原则2:使用SKIP LOCKED处理队列
-- 好的做法:跳过已锁定的行
SELECT * FROM tasks
WHEREstatus = 'pending'
ORDERBYpriority
LIMIT1
FORUPDATESKIPLOCKED;
-- 原则3:避免显式表锁
-- 显式LOCK TABLE会阻塞所有并发
-- LOCK TABLE users IN ACCESS EXCLUSIVE MODE; -- 尽量避免
10.2 数据库配置最佳实践
# postgresql.conf关键配置
# 连接与超时配置
max_connections = 200
shared_buffers = 8GB
effective_cache_size = 24GB
work_mem = 64MB
maintenance_work_mem = 2GB
# 锁相关配置
lock_timeout = '2s' # 锁等待超时
statement_timeout = '60s' # 语句超时
idle_in_transaction_session_timeout = '10min'# 空闲事务超时
# 死锁检测
deadlock_timeout = '1s'
# 日志配置
log_lock_waits = on # 记录锁等待
log_min_duration_statement = '1s' # 记录慢查询
# VACUUM配置
autovacuum = on
autovacuum_max_workers = 4
autovacuum_naptime = '1min'
autovacuum_vacuum_threshold = 50
autovacuum_vacuum_scale_factor = 0.01
# 表级配置示例
# ALTER TABLE big_table SET (autovacuum_vacuum_scale_factor = 0.005);
10.3 监控告警配置
#!/bin/bash
# 文件名:pg_lock_alert.sh
# 功能:锁监控告警脚本(用于cron或监控集成)
PSQL="psql -U postgres -d postgres -t -A -F'|'"
# 告警阈值(秒)
LOCK_WAIT_THRESHOLD=60
IDLE_TRANSACTION_THRESHOLD=600
# 检查锁等待
LOCK_WAIT_COUNT=$($PSQL -c "
SELECT
COUNT(*)
FROM
pg_locks l
JOIN pg_stat_activity a ON a.pid = l.pid
WHERE
l.granted = false
AND extract(EPOCH FROM (now() - a.query_start)) > $LOCK_WAIT_THRESHOLD;
")
# 检查IDLE in transaction
IDLE_TRANS_COUNT=$($PSQL -c "
SELECT
COUNT(*)
FROM
pg_stat_activity
WHERE
state = 'idle in transaction'
AND extract(EPOCH FROM (now() - state_change)) > $IDLE_TRANSACTION_THRESHOLD;
")
# 发送告警(根据实际情况选择告警方式)
if [ "$LOCK_WAIT_COUNT" -gt 0 ]; then
echo"CRITICAL: $LOCK_WAIT_COUNT lock waits exceeding ${LOCK_WAIT_THRESHOLD}s"
# 邮件告警
# echo "PostgreSQL lock wait alert" | mail -s "PG Lock Alert" admin@example.com
# 或者调用监控API
# curl -X POST "https://monitoring.example.com/api/alerts" -d "{\"type\":\"lock_wait\",\"count\":$LOCK_WAIT_COUNT}"
fi
if [ "$IDLE_TRANS_COUNT" -gt 0 ]; then
echo"WARNING: $IDLE_TRANS_COUNT idle in transaction sessions exceeding ${IDLE_TRANSACTION_THRESHOLD}s"
fi
# 输出状态码供cron判断
if [ "$LOCK_WAIT_COUNT" -gt 0 ] || [ "$IDLE_TRANS_COUNT" -gt 0 ]; then
exit 1
else
exit 0
fi
10.4 定期维护任务
#!/bin/bash
# 文件名:pg_lock_maintenance.sh
# 功能:锁相关定期维护任务
PSQL="psql -U postgres -d postgres -t -A -F'|'"
LOG_FILE="/var/log/postgresql/lock_maintenance_$(date '+%Y%m%d').log"
echo"==========================================" > "$LOG_FILE"
echo"PostgreSQL锁维护任务" >> "$LOG_FILE"
echo"执行时间:$(date '+%Y-%m-%d %H:%M:%S')" >> "$LOG_FILE"
echo"==========================================" >> "$LOG_FILE"
# 1. 收集统计信息
echo"" >> "$LOG_FILE"
echo"【1】锁统计快照" >> "$LOG_FILE"
echo"----------------------------------------" >> "$LOG_FILE"
$PSQL -c "
SELECT
locktype,
mode,
COUNT(*) AS count,
COUNT(DISTINCT pid) AS sessions
FROM
pg_locks
GROUP BY
locktype, mode
ORDER BY
count DESC;
" >> "$LOG_FILE"
# 2. 表膨胀检查
echo"" >> "$LOG_FILE"
echo"【2】死元组过多的表" >> "$LOG_FILE"
echo"----------------------------------------" >> "$LOG_FILE"
$PSQL -c "
SELECT
schemaname,
relname,
n_dead_tup,
n_live_tup,
ROUND(n_dead_tup::numeric / NULLIF(n_live_tup + n_dead_tup, 0) * 100, 2) AS dead_pct
FROM
pg_stat_user_tables
WHERE
n_dead_tup > 1000
ORDER BY
n_dead_tup DESC
LIMIT 10;
" >> "$LOG_FILE"
# 3. 建议执行的维护操作
echo"" >> "$LOG_FILE"
echo"【3】建议的维护操作" >> "$LOG_FILE"
echo"----------------------------------------" >> "$LOG_FILE"
# 生成需要VACUUM的表列表
TABLES_TO_VACUUM=$($PSQL -c "
SELECT
'VACUUM VERBOSE ' || schemaname || '.' || relname || ';'
FROM
pg_stat_user_tables
WHERE
n_dead_tup > 10000
AND (last_vacuum IS NULL OR last_vacuum < now() - interval '7 days')
ORDER BY
n_dead_tup DESC
LIMIT 20;
")
if [ -n "$TABLES_TO_VACUUM" ]; then
echo"建议执行以下VACUUM操作:" >> "$LOG_FILE"
echo"$TABLES_TO_VACUUM" >> "$LOG_FILE"
fi
echo"" >> "$LOG_FILE"
echo"维护任务完成" >> "$LOG_FILE"
11. 总结
11.1 核心要点回顾
锁机制理解:
- PostgreSQL的锁机制是保证数据一致性的基础
- 表级锁控制DDL和并发DDL操作
- 行级锁控制对具体行的并发修改
- MVCC通过多版本减少读写冲突
- 咨询锁用于应用层自定义并发控制
监控诊断要点:
- pg_locks是查看锁信息的核心视图
- pg_stat_activity显示会话和查询状态
- pg_blocking_pids快速定位阻塞源
- 合理配置lock_timeout避免长时间等待
优化策略:
- 保持事务简短
- 使用适当的锁模式(NOWAIT/SKIP LOCKED)
- 调整autovacuum及时清理死元组
- 通过监控提前发现潜在问题
11.2 常见问题速查表
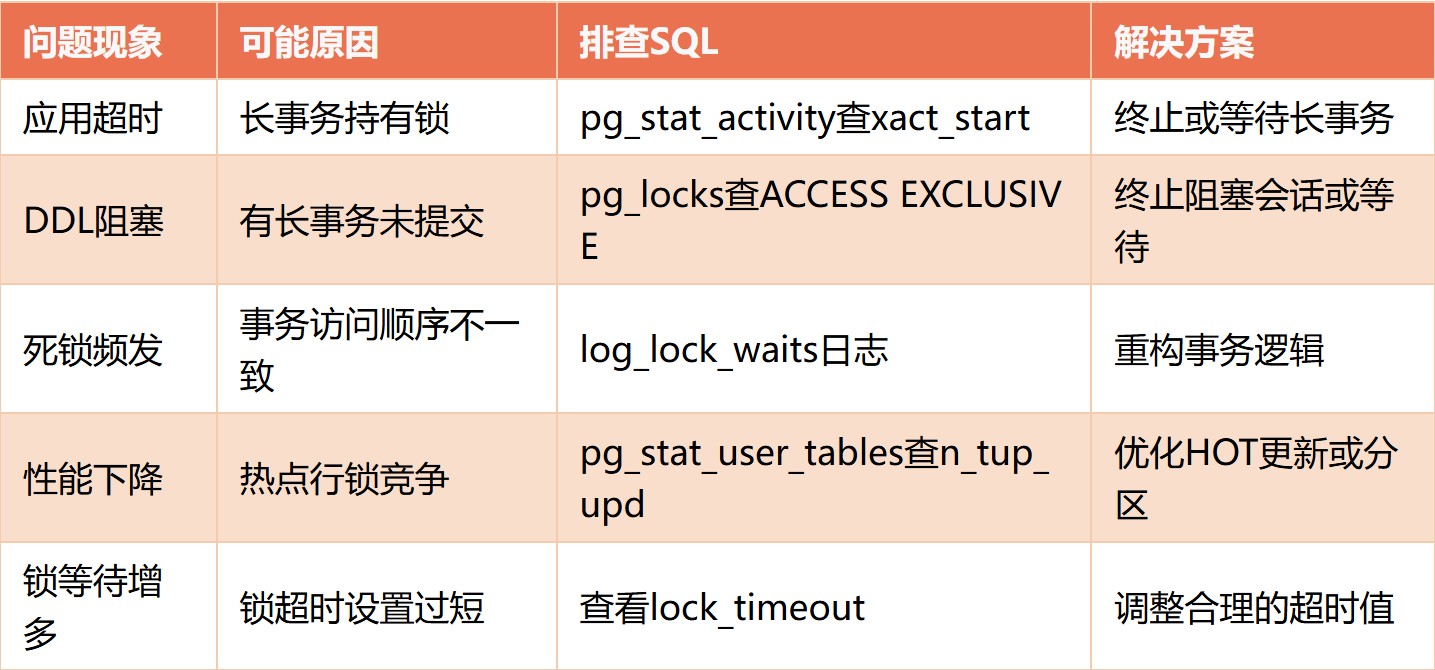
11.3 推荐配置文件
# postgresql.conf中的关键锁配置总结
# === 锁管理 ===
lock_timeout = '2s' # 锁等待超时
statement_timeout = '60s' # 语句超时
idle_in_transaction_session_timeout = '10min'# 空闲事务超时
deadlock_timeout = '1s' # 死锁检测间隔
# === 日志 ===
log_lock_waits = on # 记录锁等待
log_min_duration_statement = '1s' # 记录超过1秒的查询
# === 自动清理 ===
autovacuum = on
autovacuum_max_workers = 4
autovacuum_naptime = '1min'
11.4 进一步学习建议
推荐阅读:
- PostgreSQL官方文档第13章"并发控制"
- PostgreSQL源码:src/backend/storage/lmgr/
- 《PostgreSQL数据库内核分析》
实践建议:
- 在测试环境模拟各种锁场景
- 定期查看pg_stat_database的deadlocks计数
- 记录和分析生产环境的锁等待日志
- 建立锁监控仪表盘
通过本文的系统学习,应该能够对PostgreSQL锁机制有全面的理解,并具备生产环境锁问题的排查和优化能力。锁问题是数据库运维中的重要课题,需要持续关注和实践。
- 发表于 2026-04-01 18:47
- 阅读 ( 10 )
