tcp层丢包问题调优方案
tcp层丢包
1,TIME_WAIT过多丢包
大量TIMEWAIT出现,并且需要解决的场景,在高并发短连接的TCP服务器上,当服务器处理完请求后立刻按照主动正常关闭连接。。。这个场景下,会出现大量socket处于TIMEWAIT状态。如果客户端的并发量持续很高,此时部分客户端就会显示连接不上;
查看:
查看系统log :
dmsg
TCP: time wait bucket table overflow;
查看系统配置:
sysctl -a|grep tcp_max_tw_buckets
net.ipv4.tcp_max_tw_buckets = 16384
解决方案:
1. tw_reuse,tw_recycle 必须在客户端和服务端timestamps 开启时才管用(默认打开)
2. tw_reuse 只对客户端起作用,开启后客户端在1s内回收;
3. tw_recycle对客户端和服务器同时起作用,开启后在3.5*RTO 内回收,RTO 200ms~ 120s具体时间视网络状况。内网状况比tw_reuse稍快,公网尤其移动网络大多要比tw_reuse 慢,优点就是能够回收服务端的TIME_WAIT数量;
在服务端,如果网络路径会经过NAT节点,不要启用net.ipv4.tcp_tw_recycle,会导致时间戳混乱,引起其他丢包问题;
4. 调整tcp_max_tw_buckets大小,如果内存足够:
sysctl -w net.ipv4.tcp_max_tw_buckets=163840;
2,时间戳异常丢包
当多个客户端处于同一个NAT环境时,同时访问服务器,不同客户端的时间可能不一致,此时服务端接收到同一个NAT发送的请求,就会出现时间戳错乱的现象,于是后面的数据包就被丢弃了,具体的表现通常是是客户端明明发送的SYN,但服务端就是不响应ACK。在服务器借助下面的命令可以来确认数据包是否有不断被丢弃的现象。
检查:
netstat -s | grep rejects
解决方案:
如果网络路径会经过NAT节点,不要启用net.ipv4.tcp_tw_recycle;
3,TCP队列问题导致丢包
原理:
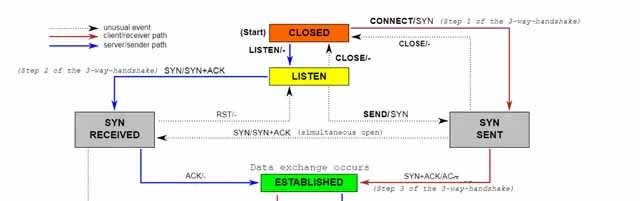
tcp状态机(三次握手)
协议处理:
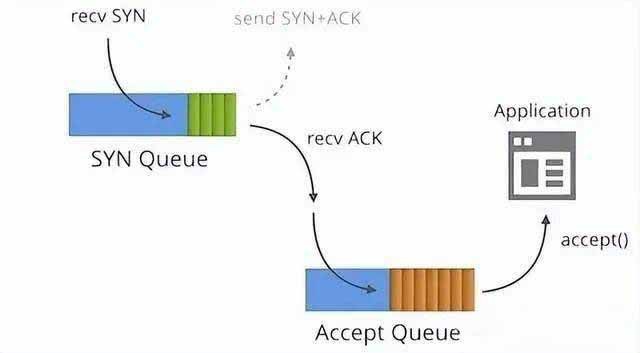
一个是半连接队列(syn queue):
在三次握手协议中,服务器维护一个半连接队列,该队列为每个客户端的SYN包开设一个条目(服务端在接收到SYN包的时候,就已经创建了request_sock结构,存储在半连接队列中),该条目表明服务器已收到SYN包,并向客户发出确认,正在等待客户的确认包(会进行第二次握手发送SYN+ACK的包加以确认)。这些条目所标识的连接在服务器处于Syn_RECV状态,当服务器收到客户的确认包时,删除该条目,服务器进入ESTABLISHED状态。该队列为SYN队列,长度为max(64, /proc/sys/net/ipv4/tcp_max_syn_backlog), 机器的tcp_max_syn_backlog值在/proc/sys/net/ipv4/tcp_max_syn_backlog下配置;
一个是全连接队列(accept queue):
第三次握手时,当server接收到ACK 报之后, 会进入一个新的叫 accept 的队列,该队列的长度为 min(backlog, somaxconn),默认情况下,somaxconn 的值为 128,表示最多有 129 的 ESTAB 的连接等待 accept,而 backlog 的值则应该是由 int listen(int sockfd, int backlog) 中的第二个参数指定,listen 里面的 backlog 可以有我们的应用程序去定义的;
查看:
连接建立失败,syn丢包:
netstat -s |grep -i listen
SYNs to LISTEN sockets dropped
也会受到连接满丢包影响
解决方案:增加大小 tcp_max_syn_backlog
连接满丢包
-xxx times the listen queue of a socket overflowed
查看:
- 查看accept队列大小 :net.core.somaxconn
- ss -lnt查询socket队列 :LISTEN 状态: Recv-Q 表示的当前等待服务端调用 accept 完成三次握手的 listen backlog 数值,也就是说,当客户端通过 connect 去连接正在 listen 的服务端时,这些连接会一直处于这个 queue 里面直到被服务端 accept;Send-Q 表示的则是最大的 listen backlog 数值,这就就是上面提到的 min(backlog, somaxconn) 的值,
- 看一下是不是应用程序设置限制, int listen(int sockfd, int backlog);
解决方案:
- Linux内核参进行优化,可以缓解压力 tcp_abort_on_overflow=1
- 调整net.core.somaxconn大小;
- 应用程序设置问题,通知客户程序修改;
syn flood攻击丢包
目前,Linux下默认会进行5次重发SYN-ACK包,重试的间隔时间从1s开始,下次的重试间隔时间是前一次的双倍,5次的重试时间间隔为1s, 2s, 4s, 8s, 16s,总共31s,第5次发出后还要等32s都知道第5次也超时了,所以,总共需要 1s + 2s + 4s+ 8s+ 16s + 32s = 63s,TCP才会把断开这个连接。由于,SYN超时需要63秒,那么就给攻击者一个攻击服务器的机会,攻击者在短时间内发送大量的SYN包给Server(俗称 SYN flood 攻击),用于耗尽Server的SYN队列。对于应对SYN 过多的问题;
解决方案:
- 增大tcp_max_syn_backlog
- 减少tcp_synack_retries
- 启用tcp_syncookies
- 启用tcp_abort_on_overflow, tcp_abort_on_overflow修改成 1,1表示第三步的时候如果全连接队列满了,server发送一个reset包给client,表示废掉这个握手过程和这个连接(本来在server端这个连接就还没建立起来);
4,PAWS机制丢包
原理:PAWS(Protect Against Wrapped Sequence numbers),高带宽下,TCP序列号可能在较短的时间内就被重复使用(recycle/wrapped) 就可能导致同一条TCP流在短时间内出现序号一样的两个合法的数据包及其确认包。
查看:
$netstat -s |grep -e "passive connections rejected because of time
stamp" -e "packets rejects in established connections because of
timestamp”
387158 passive connections rejected because of time stamp
825313 packets rejects in established connections because of timestamp
通过sysctl查看是否启用了tcp_tw_recycle及tcp_timestamp:
$ sysctl net.ipv4.tcp_tw_recycle
net.ipv4.tcp_tw_recycle = 1
$ sysctl net.ipv4.tcp_timestamps
net.ipv4.tcp_timestamps = 1
- 1. tcp_tw_recycle参数。它用来快速回收TIME_WAIT连接,不过如果在NAT环境下会引发问题;
2. 当多个客户端通过NAT方式联网并与服务端交互时,服务端看到的是同一个IP,也就是说对服务端而言这些客户端实际上等同于一个,可惜由于这些客户端的时间戳可能存在差异,于是乎从服务端的视角看,便可能出现时间戳错乱的现象,进而直接导致时间戳小的数据包被丢弃。如果发生了此类问题,具体的表现通常是是客户端明明发送的SYN,但服务端就是不响应ACK。
解决方案:
在NAT环境下,清除tcp时间戳选项,或者不开启tcp_tw_recycle参数;
5,TLP问题丢包
TLP主要是为了解决尾丢包重传效率的问题,TLP能够有效的避免较长的RTO超时,进而提高TCP性能,详细参考文章:
http://perthcharles.github.io/2015/10/31/wiki-network-tcp-tlp/;
但在低时延场景下(短连接小包量),TLP与延迟ACK组合可能会造成无效重传,导致客户端感发现大量假重传包,加大了响应延迟;
查看:
查看协议栈统计:
netstat -s |grep TCPLossProbes
查看系统配置:
sysctl -a | grep tcp_early_retrans

解决方案:
1.关掉延迟ack,打开快速ack;
2.linux实现nodelay语意不是快速ack,只是关闭nagle算法;
3.打开快速ack选项,socket里面有个 TCP_QUICKACK 选项, 需要每次recv后再设置一次。
6,内存不足导致丢包
查看:
查看log:
dmesg|grep “out of memory”
查看系统配置:
cat /proc/sys/net/ipv4/tcp_mem
cat /proc/sys/net/ipv4/tcp_rmem
cat /proc/sys/net/ipv4/tcp_wmem
解决方案:
根据TCP业务并发流量,调整系统参数,一般试着增大2倍或者其他倍数来看是否缓解;
sysclt -w net.ipv4.tcp_mem=
sysclt -w net.ipv4.tcp_wmem=
sysclt -w net.ipv4.tcp_rmem=
sysctl -p
7,TCP超时丢包
查看:
抓包分析一下网络RTT:
用其他工具测试一下当前端到端网络质量(hping等);
# hping -S 9.199.10.104 -A
HPING 9.199.10.104 (bond1 9.199.10.104): SA set, 40 headers + 0 data bytes
len=46 ip=9.199.10.104 ttl=53 DF id=47617 sport=0 flags=R seq=0 win=0 rtt=38.3 ms
len=46 ip=9.199.10.104 ttl=53 DF id=47658 sport=0 flags=R seq=1 win=0 rtt=38.3 ms
len=46 ip=9.199.10.104 ttl=53 DF id=47739 sport=0 flags=R seq=2 win=0 rtt=30.4 ms
len=46 ip=9.199.10.104 ttl=53 DF id=47842 sport=0 flags=R seq=3 win=0 rtt=30.4 ms
len=46 ip=9.199.10.104 ttl=53 DF id=48485 sport=0 flags=R seq=4 win=0 rtt=38.7 ms
len=46 ip=9.199.10.104 ttl=53 DF id=49274 sport=0 flags=R seq=5 win=0 rtt=34.1 ms
len=46 ip=9.199.10.104 ttl=53 DF id=49491 sport=0 flags=R seq=6 win=0 rtt=30.3 ms
解决方案:
- 关闭Nagle算法,减少小包延迟;
- 关闭延迟ack:
sysctl -w net.ipv4.tcp_no_delay_ack=1
8,TCP乱序丢包
此时TCP会无法判断是数据包丢失还是乱序,因为丢包和乱序都会导致接收端收到次序混乱的数据包,造成接收端的数据空洞。TCP会将这种情况暂定为数据包的乱序,因为乱序是时间问题(可能是数据包的迟到),而丢包则意味着重传。当TCP意识到包出现乱序的情况时,会立即ACK,该ACK的TSER部分包含的TSEV值会记录当前接收端收到有序报文段的时刻。这会使得数据包的RTT样本值增大,进一步导致RTO时间延长。这对TCP来说无疑是有益的,因为TCP有充分的时间判断数据包到底是失序还是丢了来防止不必要的数据重传。当然严重的乱序则会让发送端以为是丢包一旦重复的ACK超过TCP的阈值,便会触发超时重传机制,以及时解决这种问题;
查看:抓包分析是否存在很多乱序报文:
解决方案:如果在多径传输场景或者网络质量不好,可以通过修改下面值来提供系统对TCP无序传送的容错率:
拥塞控制丢包
在互联网发展的过程当中,TCP算法也做出了一定改变,先后演进了
Reno、NewReno、Cubic和Vegas,这些改进算法大体可以分为基于丢包和基于延时的拥塞控制算法。基于丢包的拥塞控制算法以Reno、NewReno为代表,它的主要问题有Buffer bloat和长肥管道两种,基于丢包的协议拥塞控制机制是被动式的,其依据网络中的丢包事件来做网络拥塞判断。即使网络中的负载很高,只要没有产生拥塞丢包,协议就不会主动降低自己的发送速度。最初路由器转发出口的Buffer 是比较小的,TCP在利用时容易造成全局同步,降低带宽利用率,随后路由器厂家由于硬件成本下降不断地增加Buffer,基于丢包反馈的协议在不丢包的情况下持续占用路由器buffer,虽然提高了网络带宽的利用率,但同时也意味着发生拥塞丢包后,网络抖动性加大。另外对于带宽和RTT都很高的长肥管道问题来说,管道中随机丢包的可能性很大,TCP的默认buffer设置比较小加上随机丢包造成的cwnd经常下折,导致带宽利用率依旧很低;BBR(Bottleneck Bandwidth and Round-trip propagation time)是一种基于带宽和延迟反馈的拥塞控制算法。目前已经演化到第二版,是一个典型的封闭反馈系统,发送多少报文和用多快的速度发送这些报文都是在每次反馈中不断调节。在BBR提出之前,拥塞控制都是基于事件的算法,需要通过丢包或延时事件驱动;BBR提出之后,拥塞控制是基于反馈的自主自动控制算法,对于速率的控制是由算法决定,而不由网络事件决定,BBR算法的核心是找到最大带宽(Max BW)和最小延时(Min RTT)这两个参数,最大带宽和最小延时的乘积可以得到BDP(Bandwidth Delay Product), 而BDP就是网络链路中可以存放数据的最大容量。BDP驱动Probing State Machine得到Rate quantum和cwnd,分别设置到发送引擎中就可以解决发送速度和数据量的问题。
Linux 4.9内核首次采用BBR拥塞控制算法第一个版本,BBR抗丢包能力比其他算法要强,但这个版本在某些场景下面有问题(缺点),BBR在实时音视频领域存在的问题,深队列竞争不过Cubic。
问题现象就是:在深队列场景,BBR的ProbeRTT阶段只发4个包,发送速率下降太多会引发延迟加大和卡顿问题。
查看:
ss -sti //在源端 ss -sti|grep 10.125.42.49:47699 -A 3 ( 10.125.42.49:47699 是目的端地址和端口号)
解决方案:
- ProbeRTT并不适用实时音视频领域,因此可以选择直接去除,或者像BBRV2把probe RTT缩短到2.5s一次,使用0.5xBDP发送;
- 如果没有特殊需求,切换成稳定的cubic算法;
9,UDP层丢包
收发包失败丢包
查看:netstat 统计
如果有持续的 receive buffer errors/send buffer errors 计数;
解决方案:
- CPU负载(多核绑核配置),网络负载(软中断优化,调整驱动队列netdev_max_backlog),内存配置(协议栈内存);
- 按峰值在来,增大buffer缓存区大小:
net.ipv4.udp_mem = xxx
net.ipv4.udp_rmem_min = xxx
net.ipv4.udp_wmem_min = xxx
3. 调整应用设计:
- UDP本身就是无连接不可靠的协议,适用于报文偶尔丢失也不影响程序状态的场景,比如视频、音频、游戏、监控等。对报文可靠性要求比较高的应用不要使用 UDP,推荐直接使用 TCP。当然,也可以在应用层做重试、去重保证可靠性
- 如果发现服务器丢包,首先通过监控查看系统负载是否过高,先想办法把负载降低再看丢包问题是否消失
- 如果系统负载过高,UDP丢包是没有有效解决方案的。如果是应用异常导致CPU、memory、IO 过高,请及时定位异常应用并修复;如果是资源不够,监控应该能及时发现并快速扩容
- 对于系统大量接收或者发送UDP报文的,可以通过调节系统和程序的 socket buffer size 来降低丢包的概率
- 应用程序在处理UDP报文时,要采用异步方式,在两次接收报文之间不要有太多的处理逻辑
应用层socket丢包
socket缓存区接收丢包
查看:
1. 抓包分析是否存在丢包情况;
2. 查看统计:
netstat -s|grep "packet receive errors"
解决方案:
调整socket缓冲区大小:
10,socket配置(所有协议socket):
# Default Socket Receive Buffer
net.core.rmem_default = 31457280
# Maximum Socket Receive Buffer
net.core.rmem_max = 67108864
具体大小调整原理:
缓冲区大小没有任何设置值是最佳的,因为最佳大小随具体情况而不同
缓冲区估算原理:在数据通信中,带宽时延乘积(英语:bandwidth-delay product;或称带宽延时乘积、带宽延时积等)指的是一个数据链路的能力(每秒比特)与来回通信延迟(单位秒)的乘积。[1][2]其结果是以比特(或字节)为单位的一个数据总量,等同在任何特定时间该网络线路上的最大数据量——已发送但尚未确认的数据。
BDP = 带宽 * RTT
可以通过计算当面节点带宽和统计平均时延来估算BDP,即缓冲区的大小,可以参考下面常见场景估计:

11,应用设置tcp连接数大小丢包
查看:
请参考上面TCP连接队列分析;
解决方案:
设置合理的连接队列大小,当第三次握手时,当server接收到ACK 报之后, 会进入一个新的叫 accept 的队列,该队列的长度为 min(backlog, somaxconn),默认情况下,somaxconn 的值为 128,表示最多有 129 的 ESTAB 的连接等待 accept,而 backlog 的值则应该是由 int listen(int sockfd, int backlog) 中的第二个参数指定,listen 里面的 backlog 可以有我们的应用程序去定义的;
12,应用发送太快导致丢包
查看统计:
netstat -s|grep "send buffer errors"
解决方案:
- ICMP/UDP没有流控机制,需要应用设计合理发送方式和速度,照顾到底层buff大小和CPU负载以及网络带宽质量;
- 设置合理的sock缓冲区大小:
setsockopt(s,SOL_SOCKET,SO_SNDBUF, i(const char*)&nSendBuf,sizeof(int));
- 调整系统socket缓冲区大小:
# Default Socket Send Buffer
net.core.wmem_default = 31457280
# Maximum Socket Send Buffer
net.core.wmem_max = 33554432
- 发表于 2024-06-12 02:38
- 阅读 ( 476 )
